作者:ChenShawn
https://zhuanlan.zhihu.com/p/2005256302918665528
我们最近 release 的工作 VESPO,是一个在 off-policy setting 下解决 LLM RLVR 训练稳定性问题,以及 bias-variance tradeoff 问题的优化算法
论文:VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
链接:https://arxiv.org/abs/2602.10693
本文主要内容包括 VESPO 工作开启之前,以及推进过程中的一些思考,是 reasoning content,是放在<think>...</think> 里面的内容,可能包含一些幻觉。
本文不是VESPO 的论文解读,不包含关于 VESPO 的剧透内容,读者可以放心食用
暴论一
所有传统 RL 算法优化的根基都是 Bellman 方程(包括 reinforce 和 PPO),而 LLM RLVR 中基于 GRPO 的算法是另一个体系的东西
传统 RL 中,即使是类似像 reinforce 和 PPO 这种 policy-based 方法,其根基还是从 Bellman 方程开始一脉相承的 value estimation - policy improvement 范式;
而现在基于 GRPO 的各种 LLM RL 算法,虽然保留了 PPO 的原始 loss 形式,已经是另外一个体系中,会让很多传统 RLer 感到陌生的东西了
就像章北海带领「自然选择号」从地球逃亡后组成的「星舰文明」已经不再属于人类文明的一部分一样
论证如下
Pre-LLM 时代学过 RL 的人基本都见过下面这张图,这张图告诉我们:最优的 value estimation 等价于最优的 policy,value estimation 和 policy improvement 是可以相辅相承的
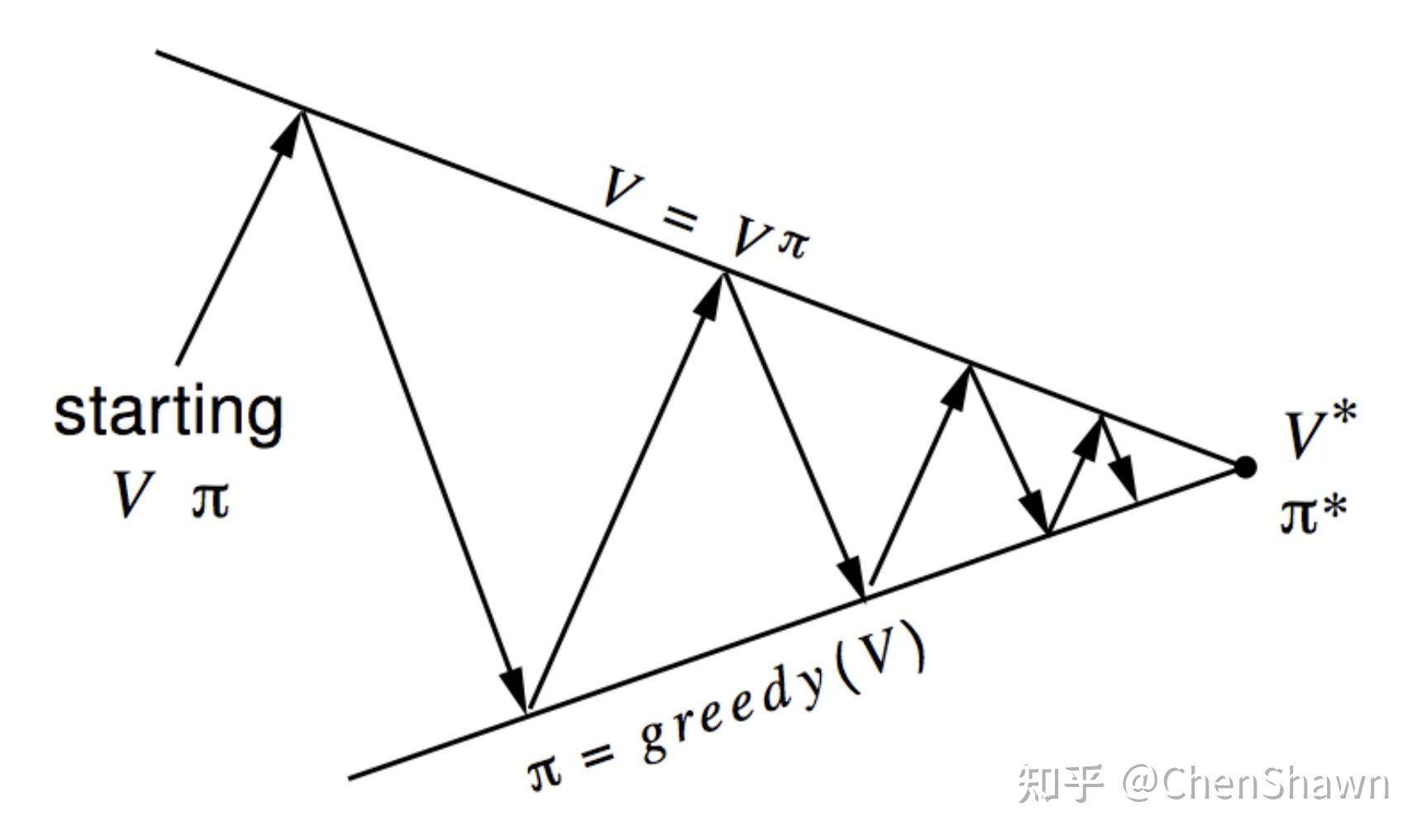
一方面,以前在游戏 RL 场景下的 PPO 训练中,一个重要的监控指标是 value loss,value loss 高了效果一定差,同样的道理可以推广到 Actor-Critic 架构中,value estimation 不准,policy improvement 一定不行;
另一方面,如果你能够通过「数据与工程的暴力」把 value estimation 做的相对比较准,policy 即使用简单朴素的 loss 也能优化好(e.g. 现在已经没人用也无人在意的 Retrace-IMPALA 系列工作);
传统游戏 RL 的训练中,一个实际长度为 T 的 rollout trajectory,rollout 长度超过 N 的情况下会被截断,用 critic 网络估计截断后未来期望的 value estimation,配合 GAE 调参。
这种做法和 multi-step actor-critic 在操作层面几乎没什么差别,所以的 PPO 训练也和 AC 类方法一样,天然存在「value 估计不准,policy 一定不行」的问题
完整 rollout:
R(\tau) := { s\_0, a\_0, s\_1, a\_1, ..., s\_{N}, a\_{N} , ..., s\_{T} }部分 rollout:
R(\tau\_{N}) := { s\_0, a\_0, s\_1, a\_1, ..., s\_{N} }R(\tau\_{N}) \leftarrow \sum\_{t=0}^{N} \gamma^{t} r(s\_t, a\_t) + \gamma^{t+1} V(s\_{N})V(s\_{t}) \leftarrow R(\tau)
在 GRPO 体系下,policy gradient 常被写作 advantage、IS weight、logp 梯度三项的乘积:
GRPO-R1 系列工作否定了一切传统 RL 角度出发,通过更好的 value estimation 促进 policy improvement 这个方向的尝试,这个公式里A(s,a) 是路人甲,一般不太需要关心「如何让A(s,a) 估计得更准确」这个问题;
f(.) 是一个函数映射:
1、 可以是线性的f(x)=x(reinforce);
2、 可以是非线性的 clip(PPO、GRPO);
3、可以是其他非线性的、连续的、可微的函数,例如SAPO,LUFFY)等等;
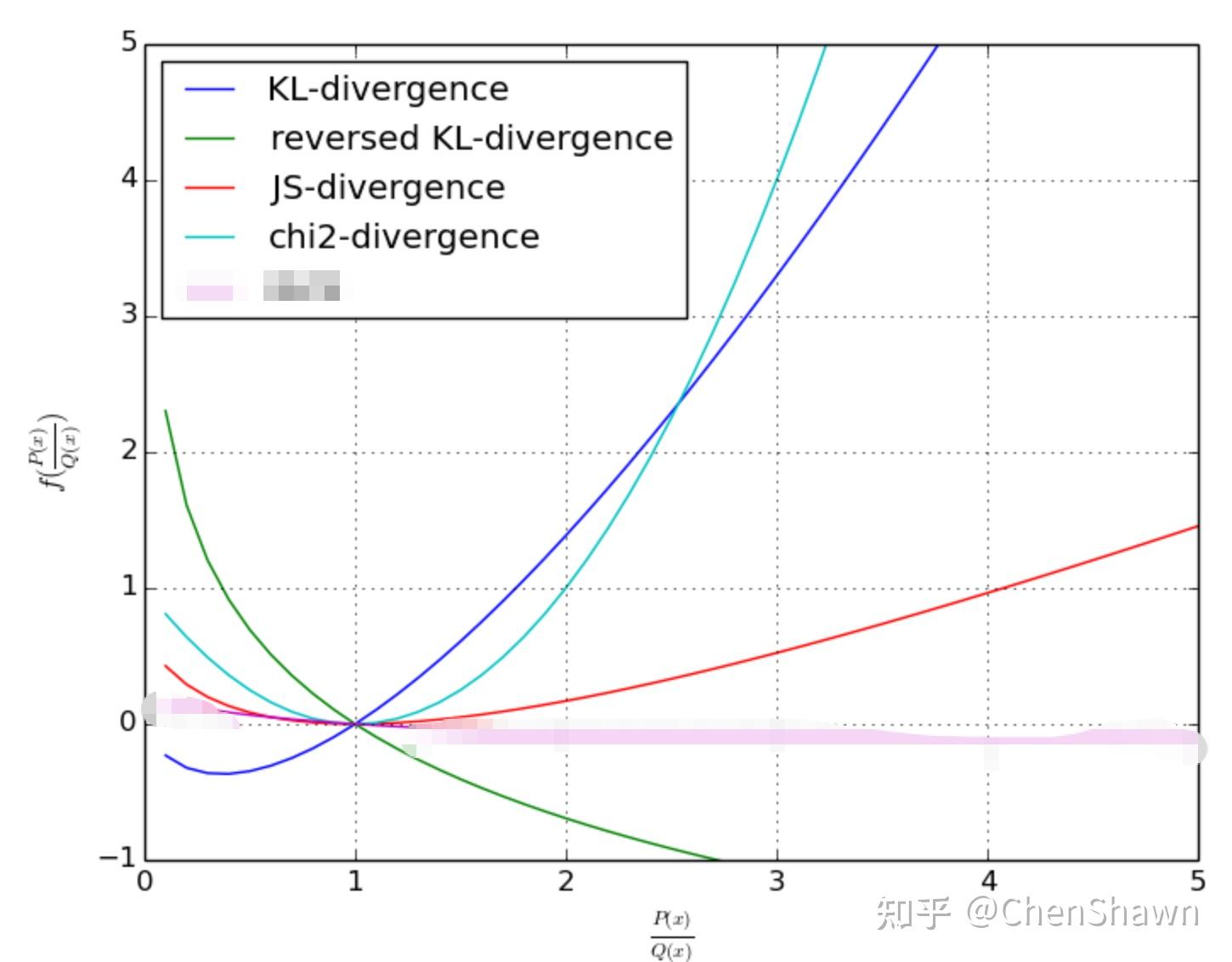
4、也可以是非连续的 indicator function: \mathbb{I}(D\_{f}(\mu, \pi) \leq \delta) ,这个 indicator function 在 mu 和 pi 两个概率分布距离远的时候等于 0。
至于怎么度量这两个概率分布之间的距离,可以是 Chi-Square divergence,可以是 KL divergence),可以是 Total Variation distance),看起来只要是个凸的 f-divergence,用哪个都行(差别应该不大);
虽然 GRPO 原始论文在公式推导层面保留了 PPO token-wise MDP 的表述形式,但实现层面,GRPO 是一个 sequence level 的算法,只有最后一个 token 有 outcome reward signal,每个 token 的 adv 相等,KL loss 均匀地分配在每个 token 上,不会有类似 KL reward 这种 token-level MDP 特有的东西
所以从 GSPO 到 SAPO 到 MiniRL 等一系列工作,他们追求通过 token level loss 来优化 sequence level 目标,这个建模是非常合理的
从这个视角来看,相比传统从 Bellman 方程出发的 RL,GRPO 更像 Weighted SFT
如果我们彻底放弃通过 policy gradient theorem 来理解 GRPO,而是从 weighted SFT 的角度来分析公式中 weight 到底是否合理,这一定程度上能解释为什么像 SAPO、LUFFY 这种已经不再符合原教旨主义 policy gradient theorem 的工作,in practice 实验效果也还不错
暴论二
如果彻底放弃从传统 RL 的视角来理解 GRPO,那么在 GRPO 的优化中,我们最关心的问题是什么?
(答案放在 boxed 里)
MIS 的博客文章中对于 policy gradient 的 bias-variance tradeoff 有一段非常好的分析:
深度!当速度扼杀稳定性:字节揭秘训练-推理不匹配导致的RL崩溃
【bias】policy gradient 算法天然是有 bias 的,正因为 bias 的存在,优化目标中才会出现 KL 约束,CPI和TRPO是基于 infinite horizon 带着 gamma 衰减来推导的。
实际上像 LLM 这种固定 context length 的场景,假设最大 response length 为 T,可以用相同的方式推导出 bias 正比于 T 的平方,并且和 Total Variation Distance(的平方)有关

如果建模从 token level MDP 变成 sequence level MDP:
- 普通非多轮的 RL(Math/Code 等)会直接变成 bandit 任务,bias 等于 0;
- Agent RL 多轮任务的 bias 会显著降低(ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL);
【variance】Importance Sampling 的方差与 chi-square divergence 有关,它比 TV、KL 都大,所以 trust region bound 住 KL 不等于 bound 住 Chi-Square:
如果建模从 token level MDP 变成 sequence level MDP,方差会随 response 长度 T 的增长指数爆炸: O((1 + \chi\_{\max}^{2})^{T})
所以 variance 是一个比 bias 更严重的问题,尤其是当你尝试用 sequence level MDP 的视角来看待 RLVR 任务,目前解决这个问题有以下几种思路:
【路线一】GSPO 路线,给样本 sequence 的概率开 T 次根方,变成 geometric mean,不是一个好的解决方案,2025 年年初,DAPO 就已经讨论过算 loss 不能用 sequence-mean,Understanding R1-Zero-Like Training: A Critical Perspective 这个工作表示,如果害怕方差太大爆炸,除以一个固定常数更靠谱

【路线二】Loss 形式仍然还是 token level 的,但是会从数学角度尝试证明在某些条件下,优化某个 token level 的 loss 约等于 优化 sequence level loss
【路线三】我们在 VESPO 中的方案(有点不走寻常路):列一个关于非线性函数f(.) 的泛函,在这个泛函中把 bias 和 variance 的约束都考虑进去,看看推出来的函数f 长什么样
这样做会带来一个好处,最终目标形式中会出现额外的超参,就像 GAE 调参数\lambda 一样,我可以通过调超参,在 bias 和 variance 中找到一个平衡点
最后发现推出来的函数f 形式对 sequence level 优化还挺友好的,也不用搞什么 token level 近似了,皆大欢喜
具体f 推出来什么样请看原文,本文点到为止