作者:阿龙aloong
https://zhuanlan.zhihu.com/p/2021015362817328193

那篇文章改变了我对 agent coding 的看法
2026 年 3 月 24 日,Anthropic 发了一篇工程文章:Harness Design for Long-Running Apps。
链接:https://www.anthropic.com/engineering/harness-design-long-running-apps
我反复读了好几遍。越读越觉得它跟市面上那些 agent 经验帖完全不在一个层面上——它可能是目前公开资料里,把长时间应用开发的 harness 讲得最系统、最工程化、也最坦诚的一篇。
过去一年里,围绕 agent coding 的讨论几乎全部集中在同一个问题上:模型到底够不够聪明?上下文窗口够不够长?工具调用够不够灵活?Anthropic 这篇文章把注意力拽到了一个完全不同的方向——外层系统该怎么设计。
这个视角转换非常关键。因为长时间开发任务里,真正会把系统拖垮的,往往跟模型聪不聪明没多大关系。任务一长,目标开始漂移;上下文一长,模型开始忘东忘西、张冠李戴;模型习惯性高估自己的完成度;每一轮看起来"差不多了",最后交出来的东西根本不能用。
这些问题,再聪明的模型也解决不了。它们需要的是工程层面的结构性约束——也就是 Anthropic 所说的 harness。
Harness 到底在解决什么问题
Anthropic 的应对方式说起来很朴素,就是把软件工程里那些老规矩搬回来。但它组合起来的效果,远比听上去要深刻。
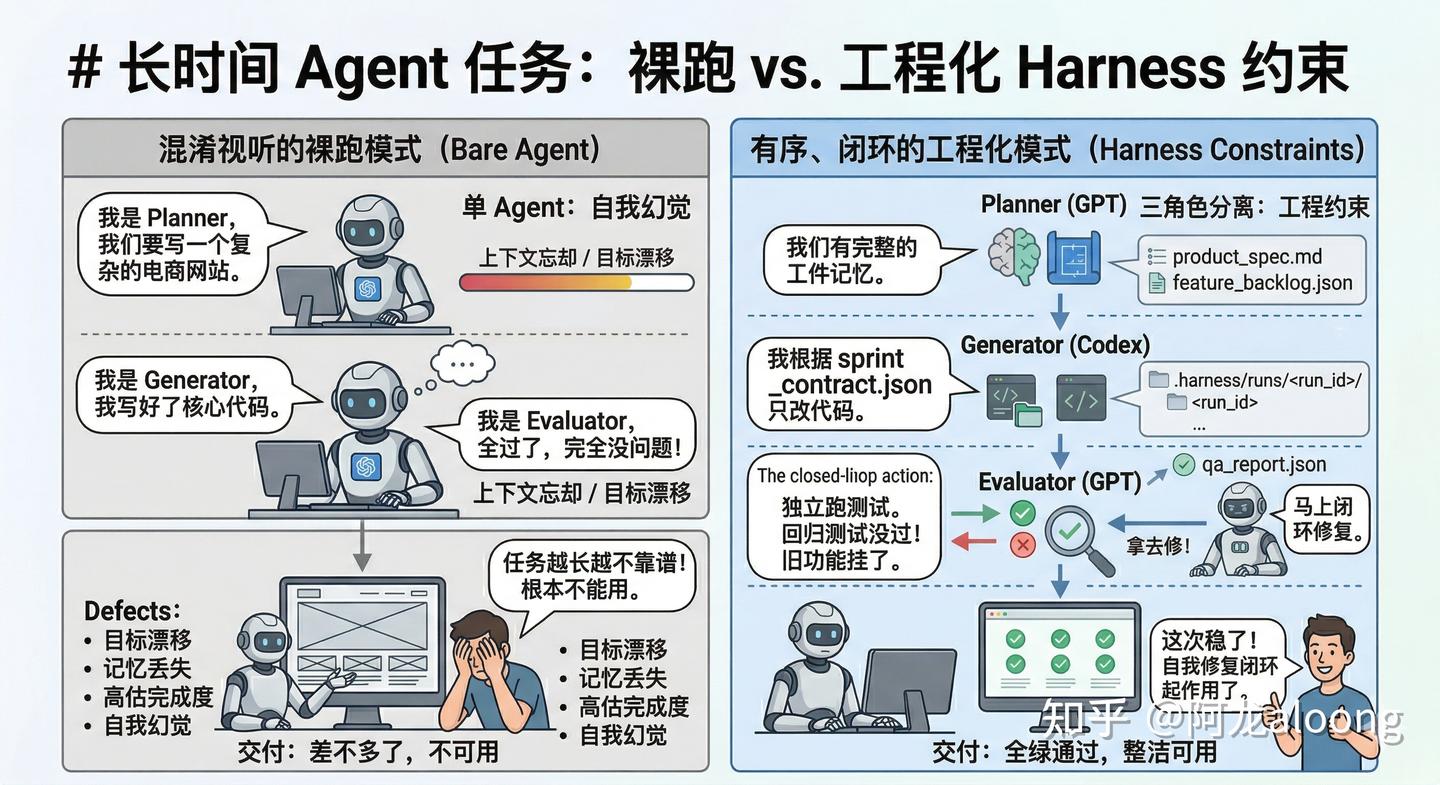
文章的核心结构可以压缩成三条。
第一条:planner / generator / evaluator 三个角色必须分开。 一个 agent 如果既理解需求、又写代码、又宣布自己通过了,这套系统的标准一定会越来越松。这是人类团队里早就验证过的规律——开发和测试不能是同一个人——Anthropic 只是把同样的原则搬到了 agent 系统上。planner 扩展需求,generator 实现当前 sprint,evaluator 独立验收,三个角色互不越权。
第二条:记忆要落到工件上。 长任务跑起来以后,"模型还记得之前说了什么"这件事极其靠不住——可能被截断、被压缩、被幻觉覆盖。真正可靠的记忆是落在文件系统里的工件:
product_spec.md
feature_backlog.json
sprint_contract.json
qa_report.json
progress.jsonl
git revision
工件完整、结构化、可追溯,系统就不用赌某一段上下文碰巧还没被丢掉。
第三条:最终判断必须来自可执行的验收。 页面能不能真的点通?测试能不能真的跑过?API 状态对不对?旧功能有没有回归?一旦这步缺了,前面所有精巧的 agent 编排都会退化成更长版本的自我幻觉。
这三条加在一起,指向同一个工程判断:让长时任务跑稳,靠的是 harness 的质量。 模型可以换,prompt 可以调,但如果外层系统撑不住,什么都白搭。
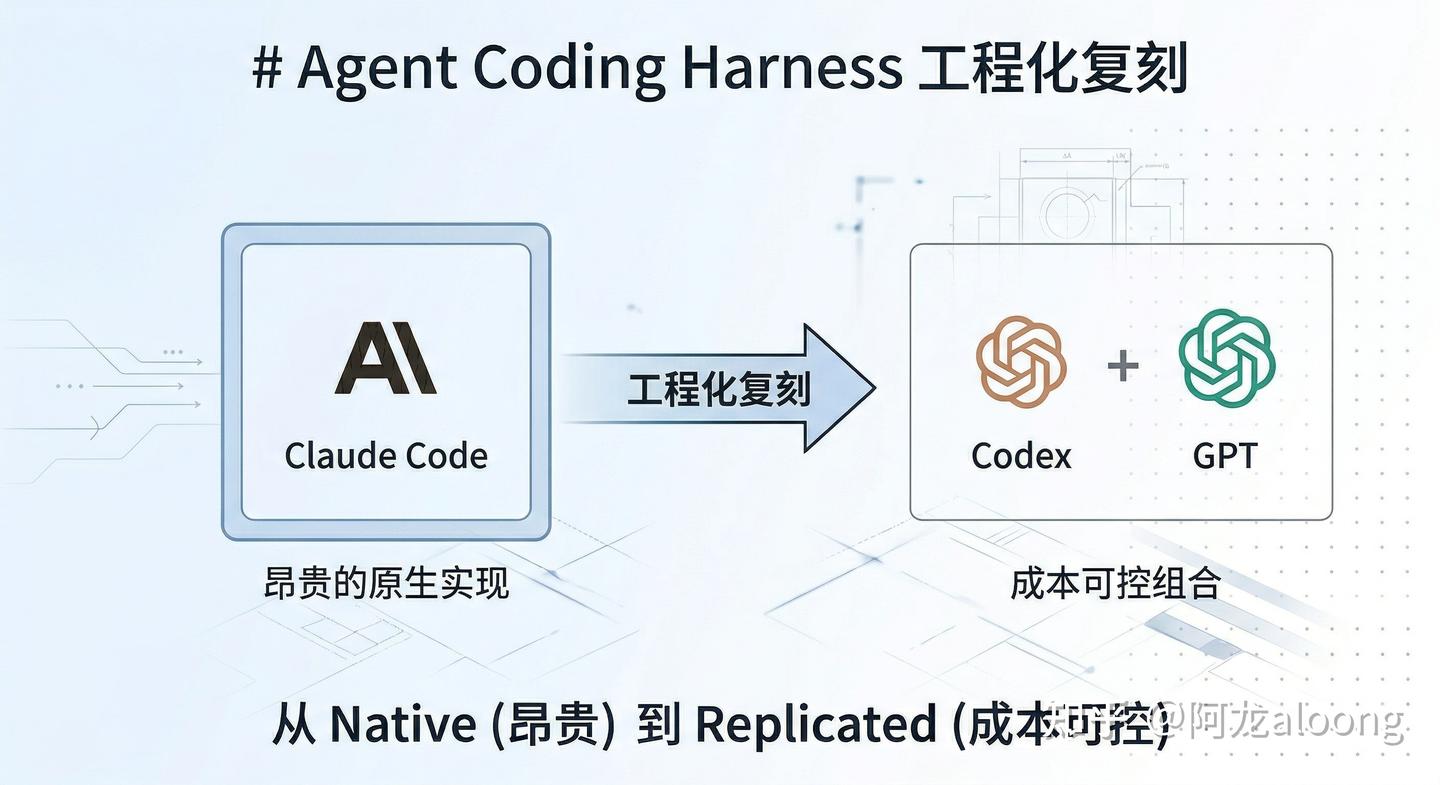
读完这篇文章之后,我做了一个决定:把这套思路认认真真复刻一遍。同时回答一个一直在脑子里转的问题——这套东西如果真的管用,它应该能脱离 Claude Code 独立存在。
第一堵墙:成本
我按照 Anthropic 的思路在 Claude Code 上搭了原型,跑了几轮。效果确实好——harness 的结构性优势很明显,任务完成质量比裸跑 agent 高出不少。
但账单也很好看。好看到让我开始重新审视整件事的可行性。
Anthropic 自己也没回避这一点。多轮代理、长回合执行、浏览器验收、反复重做,这些步骤本身就意味着高消耗。对 Anthropic 来说这当然是合理投入,但对于一个需要高频试错的独立开发者来说,情况就完全不同了。
问题的要害在这里:harness 这套思路之所以有效,恰恰是因为它鼓励你多跑——多做一次 evaluator、多开一次回归检查、多跑一轮失败修复、多做一次对照实验。每一个"多做一次"都是 harness 的生命线。但如果每一次"多做一次"都伴随着显著的成本焦虑,你就会开始省略步骤,而省略步骤恰恰是在掏空 harness 的根基。
Long-running harness 最怕的就是"因为贵,所以不敢多跑"。到了这个程度,成本已经不是一个账单优化问题了,它在直接削弱我使用这套架构的方式。
这让我确信,迁移到一个成本更可控的执行平面,不是锦上添花,而是让 harness 思路真正落地的前提条件之一。
为什么落在 Codex + GPT 上
迁移的原则很明确:Anthropic 已经证明有效的外层架构全部保留,只替换底层执行平面。把贵的地方降下来,把可持续试错的能力提上去。
随便找个便宜模型塞进去肯定不行,那会把 harness 本身做烂。我试了一段时间之后,落在了这个组合上:Codex 跑贴近仓库、贴近文件系统、贴近执行面的活儿,对应 generator 的角色;GPT 跑规划、整理、总结、结构化输出、审查,对应 planner 和 evaluator 的角色。两者配合,刚好能覆盖 Anthropic 三角色架构的各个层面。
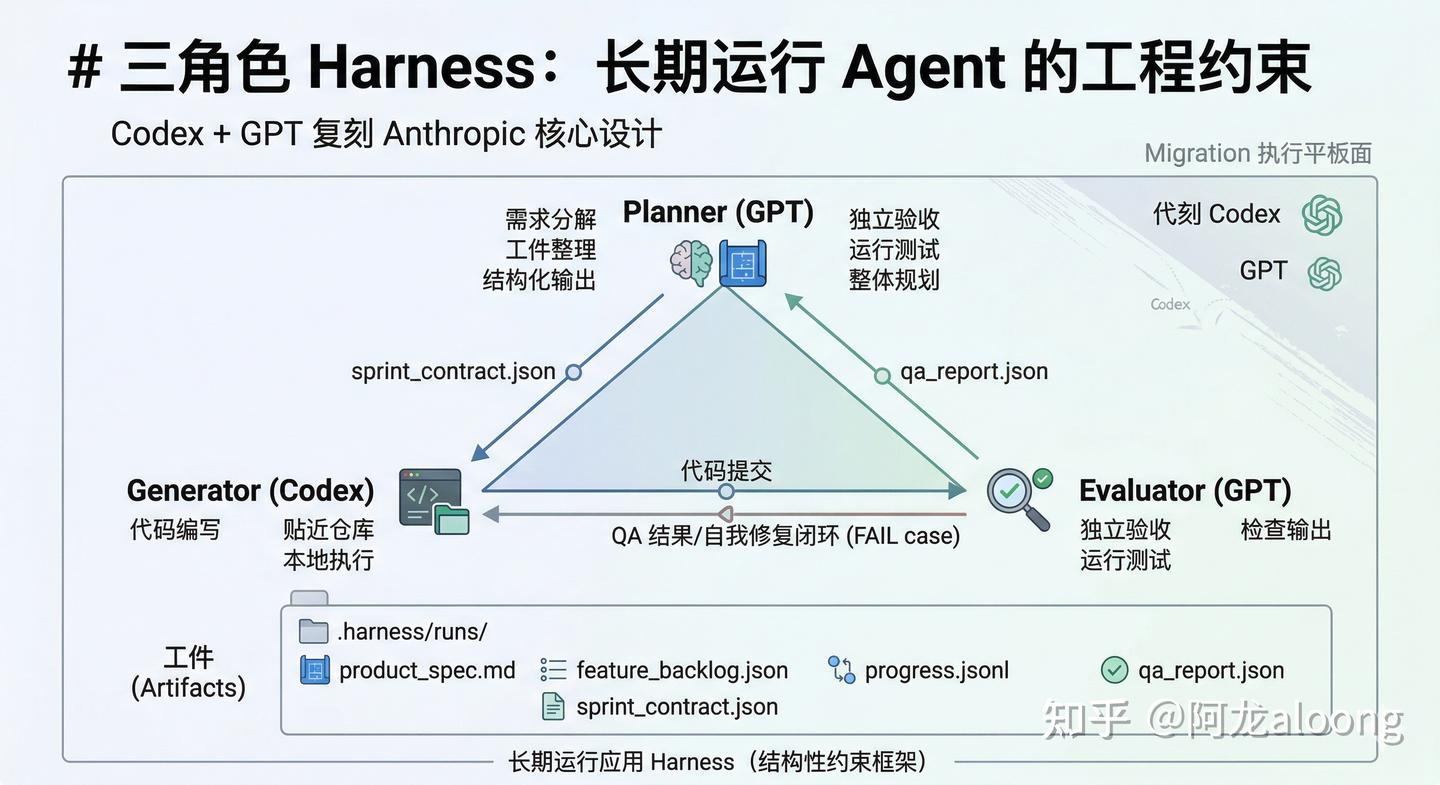
具体复刻了什么
在这个项目里,我保留了 Anthropic 设计中我认为最核心的四样东西。
1、三角色结构。 planner、generator、evaluator,各司其职。
2、工件化记忆。 运行过程中所有核心状态落到 .harness/runs/<run_id>/ 目录
run_manifest.json
product_spec.md
design_language.md
feature_backlog.json
progress.jsonl
sprint_contract.json
self_test_report.json
qa_report.json
final_report.json
不依赖会话记忆,每一份文件可追溯。
3、独立验收。 evaluator 不听 generator 怎么解释自己做了什么,而是独立跑本地测试、读取真实输出。浏览器和 API/DB 状态检查的骨架也预留好了,和 Anthropic 文章中的方向一致。
4、多轮重做闭环。 一轮 sprint 没过,QA 结果写回上下文,进入下一轮修复。没有"继续加油"这种口头安慰。
迁移过程中踩的坑
真正做下来以后,我越发确认:Anthropic 的文章给得出方向,但 Claude Code 和 Codex 的实际行为差异比想象中大,很多细节不能照搬。
Codex 需要更硬的约束
Claude Code 的体验像"同一个人一直在房间里干活",给比较模糊的指示也能自己摸索上下文。Codex 不太一样——输入文件、输出路径、schema、这轮到底做什么,你得全部写清楚。我把很多原本可以隐式处理的行为都改成了显式的结构化约束。
Evaluator 很容易被糊弄
generator 的 prompt 稍微写松一点,Codex 就会出现那种"先回你一段话,再说下一步打算"的模式——听起来很积极,实际上什么也没改。
我最后把几个环节钉死了:注入当前失败测试的真实输出、直接内联 sprint contract 的 JSON、无有效改动时自动重试、自测报告由真实命令结果合成。
这些措施让 harness 从"会说话"变成"会闭环"——这也再次印证了 Anthropic 那个核心洞察:光有聪明的 agent 不够,外层约束才是真正撑住系统的东西。
本地工程细节远比想象中重要
读 Anthropic 文章的时候很容易忽略的东西——Windows 下的非 ASCII 路径、兼容端点的 WebSocket 回退、真实仓库里的路径管理、子进程输出编码——每一个都可以卡你一整个下午。让 harness 从想法变成能跑的项目的,就是这些不性感但要命的地方。
跑出来的结果
为了不让这件事停留在架构图上,我用三个小型 disposable repo 跑了真实试验。
| 指标 | 结果 |
|---|---|
| Fresh-clone 任务数 | 3 |
| 最终通过率 | 3 / 3 |
| 首轮即通过 | 1 / 3 |
| 首轮失败后修复成功 | 2 / 2 |
| 达到首次全绿的中位 sprint 数 | 2 |
样本很小,统计上说明不了太多。但它已经展示出了 Anthropic 那篇文章里最重要的行为模式:generator 真实地改了代码,evaluator 独立地做了验收,第一轮失败后系统自己修了回来。
比起"首轮全过",最后这一条才是我真正在意的。因为 harness 存在的意义,从来就不是追求永不出错——而是出了错之后,系统还能继续干活,还能自己修回来。
三个任务里只有一个首轮通过,但最终全部通过,中位数两个 sprint 收敛——这恰恰说明 harness 在起作用。
回过头看这件事的意义
Anthropic 原项目最大的贡献,在于它把整个行业关于 agent coding 的讨论往前推了一大步。在它之前,大家讨论的主要是模型能力;
在它之后,"外层系统怎么设计"这个问题终于被正式摆上了台面。它没有逃避长任务的失败模式,没有把成功归功于某个 prompt 魔法,愿意把成本、回合数、质量这些真实问题一起摊开来讲。这些都值得尊重。
我做这次迁移,某种程度上恰恰是因为认同它。一套好的方法论不应该被锁死在一个供应商上——如果它能跨模型、跨工具链成立,它的价值才真正得到了验证。把 Anthropic 的 harness 思路成功搬到 Codex + GPT 上,本身就是对这套方法论最好的证明。
另一个更实际的考虑:很多优秀的 agent 系统最后没普及开来,倒在了使用成本上。如果这次迁移能在保住 harness 核心结构和工程可追溯性的同时把成本压下来,它推动的就不只是"换个模型"这件事——而是让一种原本偏贵、偏研究性质的工作方式,进入更多独立开发者和小团队的日常。
现状和后续
这个项目还远没有做完。它不是 Anthropic 内部 harness 的逐字复刻版,也没有在大规模场景上做过充分的 benchmark。
项目链接:https://github.com/LongWeihan/codex-long-running-harness
但最关键的第一步已经走完了:这条迁移路线走得通。Anthropic 的 harness 设计可以脱离 Claude Code 运行,Codex + GPT 能撑起同一套架构,成本结构也确实更适合高频试错。
原项目很好。也正因为它好,才更值得让更多人跑得起。