作者:欲壑难填
https://zhuanlan.zhihu.com/p/2024947723019843192
KL 散度是机器学习中的一个重要概念,其非对称性导致在实际中有 Forward KL 和 Reverse KL 两种形式,本文介绍这两种形式在优化过程中的差异,再讨论实际中应该如何选择。
定义和性质
KL 散度,用于衡量一个概率分布 p 与另一个分布 q 的差异。具体来说,从 p 到 q 的 KL 散度写为:
KL 散度具有如下性质:
- 从 KL 散度的式子上可以看出它的一个重要特点:非对称性。因为很明显的有 \mathcal{D}_\text{KL}(p||q)\ne \mathcal{D}_\text{KL}(q||p)。正因如此,KL 散度不是一个严格意义上的距离度量。
- KL 散度的取值区间在 [0,+\infty),当且仅当分布 p 和 q 完全相同时,\mathcal{D}_\text{KL}(p||q)=\mathcal{D}_\text{KL}(q||p)=0。
- 若要使 KL 散度 \mathcal{D}_\text{KL}(p||q) 的值有限,需要保证 p 的支撑集包含在 q 的支撑集内,即在所有 p 有概率的地方,q 都必须有概率。如果存在一个点 x 使得 p(x)>0 而 q(x)=0,那么 \mathcal{D}_\text{KL}(p||q)\rightarrow\infty。
Forward KL 与 Reverse KL
在机器学习的语境下,我们一般是用一个模型估计出的分布 q_\theta(x) 去拟合目标分布 p(x),这里 \theta 表示模型的参数。之前提到,KL 散度是非对称的,因此我们有最小化 Forward KL \mathcal{D}_\text{KL}(p||q_\theta) 和 Reverse KL \mathcal{D}_\text{KL}(q_\theta||p) 两个选择。
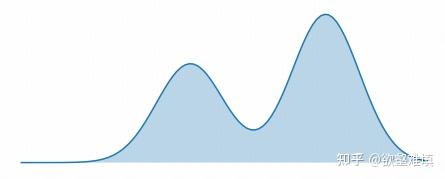
在实际的优化过程中,这两个目标的侧重点是不同的,接下来我们来详细的分析一下二者的差异。假设我们的目标分布 p 是一个双峰(bimodal)分布,如下图所示,我们尝试用一个简单的正态分布 q(x)=\mathcal{N}(\mu,\sigma^2) 来拟合它。
注意,我们这里刻意构造了一个拟合分布 q_\theta 的表达能力显著弱于目标分布 p 的情况,来探索在表达能力不足时 FKL 和 RKL 各自的拟合倾向。在实际的机器学习中情况也往往如此(比如知识蒸馏,学生模型的参数、能力显著弱于教师模型)。如果 q_\theta 的表达能力足够强,在充分采样的情况下能够完全地拟合目标分布,那也没什么分别讨论的意义。
Forward KL: Mean-Seeking (Mass-Covering)
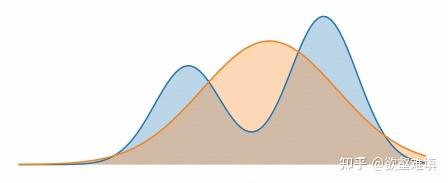
我们先来看 FKL,最小化 FKL:\mathcal{D}_{KL}(p || q_\theta) =-\mathbb{E}_{x\sim p}[\log q_\theta(x)] - \mathcal{H}(p),其中后一项是目标分布的熵,与参数 \theta 无关,因此最小化 FKL 等价于最小化前一项,即最小化交叉熵损失。用从 p 采样的样本(即训练数据)做蒙特卡洛近似后,就变成最大化样本对数似然之和 \sum_i \log q_\theta(x_i),因此 FKL 其实也就是最大似然估计。
总之 FKL 的优化就等价于最小化 -\mathbb{E}_{x\sim p}[\log q_\theta(x)] 这一项,意思是从目标分布 p 中采样样本点,最大化其在拟合分布 q_\theta 下的概率。这会强迫 q_\theta 在 p 的所有高概率区域都必须分配足够的概率质量,因为任何被 p 频繁采到却被 q_\theta 赋予低概率的点,都会让 -\log q_\theta(x) 变得很大,从而推高损失。即 FKL 要求:在所有 p 有高概率的地方,q 也必须有高概率。而对于 q 概率较高但是 p 本身概率不高的位置,由于几乎采样不到,因此 FKL 基本不会惩罚。
所以,FKL 形成了这种 “宁可摊开也不能漏掉任何一个峰(mode)”的倾向(见下图)。我们将 FKL 的行为称为 mean-seeking,因为当 q_\theta 表达力受限时(例如单峰高斯拟合多峰 p),最优解会落在 p 的均值附近,把概率质量摊在所有峰之间。
Reverse KL: Mode-Seeking
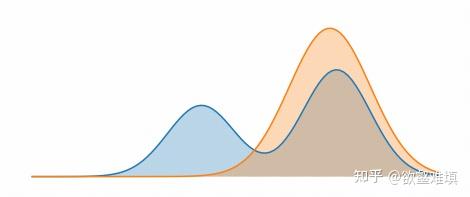
我们再来看下 RKL:\mathcal{D}_\text{KL}(q_\theta||p)=\mathbb{E}_{x\sim q_\theta}\left[\log\frac{q_\theta(x)}{p(x)}\right]=-\mathbb{E}_{x\sim q_\theta}[\log p(x)]-\mathcal{H}(q_\theta),这里前一项是在拟合分布中采样样本点,最大化其在目标分布下的概率。对这一项的分析和在 FKL 中是对称的:从拟合分布 q_\theta 中采样样本点,要求其在目标分布 p 下的概率尽可能大。由于是在自己的分布上进行采样,q_\theta 就完全不需要保证在所有 p 概率高的地方自己的概率都高了,因为如果自己在哪些地方的概率足够低,就根本不怎么会采样到那些样本。因此,RKL 只需要保证在所有 q_\theta 高概率的区域(自己频繁采样出来的地方),目标分布 p 也有高概率就好了。
后一项是拟合分布的熵,它与参数 \theta 是有关的,不能忽略了。在这里,可以将它看做是一个正则项。我们刚才提到,RKL 中只需要在所有 q_\theta 概率较高的地方,p 的概率也比较高。那对 q_\theta 来说就有一个比较保险的选择:坍缩到 p 概率最高的一个点。但这显然不是我们想要的,这里的将 q_\theta 自己的熵作为正则项,就能要求 q_\theta 本身有一定的多样性,从而避免这种坍缩的情况。
所以说,RKL 最终会 “尽可能地拟合一个峰,但不保证每个峰都有概率”(见下图)。我们将 RKL 的行为称为 mode-seeking。
怎么选?
既然 FKL 和 RKL 有这么大的差别,在实际中我们应该如何选择呢?
首先要清楚,对于不同具体问题中的 KL 计算方式,你不一定有得选。FKL 和 RKL 不是你想用哪个就能用哪个。首先得看看在你的情景中能不能满足采样的要求和(或)计算的要求。
怎么说呢?首先,毋庸置疑的,我们的目标分布 p 肯定是无法解析的(不然也不用优化拟合了)。那么我们对 p 的了解途径有两种,一是我们可以从分布 p 中采样,二是给定一个样本,我们能计算它在分布 p 下(即使是未归一化的)的概率密度。在不同的实际问题中,这二者是彼此独立的:可能可以采样,但无法计算概率;也可能可以计算概率,但无法采样;也可能二者都能;也可能二者都不能。
先说结论,我们需要可以从目标分布 p 采样,才能用 FKL;需要可以计算样本在目标分布 p 下的概率(即使是未归一化的),才能用 RKL。
这些要求其实从 FKL/RKL 的公式中就能看出。
FKL,\mathcal{D}_\text{KL}(p||q_\theta)=-\mathbb{E}_{x\sim p}[\log q_\theta(x)]-\mathcal{H}(p),其中后一项 p 的熵和优化没有关系,看前一项我们需要:1. 能从 p 中采样;2. 能计算 q_\theta(x)。计算 q_\theta(x) 肯定是可以的,因为 q_\theta 就是我们正在训的模型。因此,一个问题能不能用 FKL,就是要看我们能不能从 p 中采样。
RKL,\mathcal{D}_\text{KL}(q_\theta||p)=-\mathbb{E}_{x\sim q_\theta}[\log p(x)]-\mathcal{H}(q_\theta)。这次我们是从拟合分布 q_\theta 中采样,因此不必要求目标分布 p 可以采样了。但问题转到了对于样本 x,我们需要能够计算其在目标分布下的概率 p(x)。后面一项是模型 q_\theta 的熵,当然是可以算的。
情况一:可以采样,但无法计算样本概率。首先监督学习,都是这种情况,我们上面提到了 FKL 和交叉熵的等价性。另外,生成模型一般都是这种情况,我们可以轻易地收集大量图片,这可以视为从某个真实的图片数据分布 p_\text{data} 中采样的结果。但是给一张猫猫的图片,我们无法给出这张图片是真实世界图片的概率的具体值是多少。即无法计算样本的概率。比如自回归生成、VAE、扩散模型都可以算是这种情况。换个角度看,也正是因为用的 FKL,这些生成模型的多样性都比较好,不会像 RKL 那样坍缩到目标分布的某一个 mode 上。
情况二:可以计算样本概率,但是无法采样。这种情况听起来不太直觉,能算概率居然没法采样,但其实这在概率建模中是很常见的。比如贝叶斯后验、能量模型、变分推断等。当然了,实际上一般也不是计算目标分布的准确样本概率,因为通常有个归一化常数 Z=\int \tilde{p}(x)dx 积分是没法算的。但是实际中未归一化的概率 \tilde{p}(x) 就够用了,因为这个归一化常数与参数 \theta 无关,在对 \theta 求梯度时就消失掉了。
情况三:两者都不能。这种情况一般需要基于其他假设或曲线救国来建模。
情况四:既可以采样,也能计算概率。还有这种好事儿吗?对目标分布几乎是完全掌握的?有的兄弟,有的。最常见的场景就是:知识蒸馏。当我们有一个强力的大模型,出于成本或耗时的考虑,我们想要用一个中小模型蒸馏学习大模型的能力,来作为(高精度的)平替。这个大模型也是我们自己训练的,当然可以进行采样和概率计算。这种情况下,就既可以用 FKL,也可以用 RKL 了。这时才需要我们仔细分析,来判断具体任务、不同模型下,FKL 和 RKL 哪种方式更好。而机器学习中的其他大部分自然问题中,如上面讨论的,其实根本没得选。实际上,LLM 蒸馏究竟改用 FKL 还是 RKL,也正是近两年的一个研究热点(这个后面再单开一篇整理一下)。
总结
本文介绍了 Forward KL 和 Reverse KL 两种形式以及(当拟合能力有限时)它们在优化过程中的倾向,以及机器学习场景中如何选择。
参考
- 图源:https://dibyaghosh.com/blog/probability/kldivergence/
- Claude Opus