
假如让一个人去一个陌生城市找一家小店,他通常不会一开始就把地图放到最大。
他会先看整个城市,大致定位街区,再双指放大到具体门牌。一次"缩放"比在全景里满街扫要高效得多。
但今天的 RAG(Retrieval-Augmented Generation,检索增强生成)系统,主流路线却常常不是这样工作的。面对一个动辄上万文档的知识库,它们要么把所有文本切成小块,全语料上算相似度(像拿放大镜扫全城找店铺);要么先花几小时调用大模型,把整个知识库抽成一张"实体—关系"的知识图谱,再在图上反复多跳搜索(像为了找一家店先把整座城市重新测绘一遍)。
这两条路线看似在两端取舍,其实都卡在同一个困境里:RAG 的"索引开销"、"在线速度"、"并发能力"这三件事很难同时做好,一是离线索引太贵。以基于知识图谱的方法为例,构建一次索引往往要调用 LLM 反复抽取"实体—关系—实体"三元组,耗时动辄数小时甚至数十小时,内存占用也常常高达几十 GB。二是在线检索太慢。显式的图路径搜索和复杂的多跳推理,使单条 query 的延迟动辄几秒到十几秒,很难满足真实产品对响应时间的要求。三是并发几乎无解。现有基于结构化索引的方法大多只能串行执行,如果用朴素的数据并行直接复制整张图,几十条并发就会把显存打爆。
ACL 2026 论文 ZoomRAG: Hierarchical Random-walk Zooming across Multi-scale Information Graphs for Fast and Accurate RAG(华东师范大学、复旦大学、西南石油大学联合提出)给了一个干脆的答案:完全不建知识图谱,只用最便宜的命名实体识别(NER)搭两层不同粒度的关系图,让带重启的随机游走像双指缩放地图一样——先在一张全局粗粒度图上锁定少量相关文档,再在这些文档内部的细粒度局部图上精准定位证据块,从而系统地激活 RAG 的"先粗后细"能力。
这个设计听起来朴素,但把 RAG 系统在四个维度上一起往前推了一大截:准确率、离线索引开销、单条延迟、以及并发吞吐。方法的整体结构如下图。
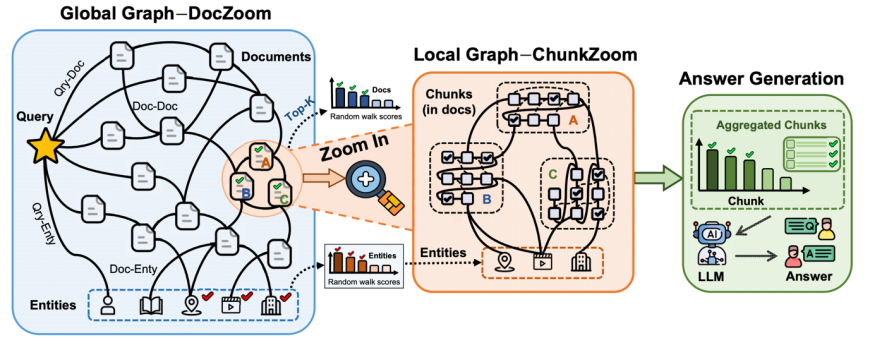
ZoomRAG 的三件事
第一,粗粒度 DocZoom:在全局图上锁定相关文档。
ZoomRAG 第一层图是一张三部图:一个查询节点、所有文档节点、所有实体节点。边也只有四种——文档与文档的语义相似度(Jina embedding 内积并稀疏化)、查询与文档的相似度、文档里出现的实体、查询里提到的实体。从查询节点出发跑一次带重启的随机游走(Random Walk with Restart),就能在整个语料上得到 Top-K 最相关文档。
这里有个容易被忽略但很关键的细节:HippoRAG、LinearRAG 等方法在游走时把查询节点用完就丢,只让它的一阶邻居继续传播;ZoomRAG 则把查询节点保留在每一轮的重启分布里,让"查询语义"像一根锚一样贯穿始终,避免游走漂走。
第二,细粒度 ChunkZoom:在选中的文档内部定位证据块。
拿到 Top-K 文档后,ZoomRAG 在这些文档内部再搭一张小图,只含文本块节点和实体节点,通常只有几十个节点。这层图的巧思在于——把"时间"也编码进了边权:块和块之间的边不只是语义相似度,还叠加了一个基于原文位置的高斯邻近项。
为什么这一点重要?多跳推理中,关键证据之间往往有天然的顺序("因为 A 所以 B 导致 C")。把这种顺序信号直接写进图里,等于在检索阶段就帮下游 LLM 做了一次证据排序,而不是扔一堆零散片段让它自己拼逻辑。由于图极小,这一步还可以直接解稳态方程(一次小矩阵求逆),比迭代传播更精确。
第三,算法级并行:让一张图服务成百条查询。
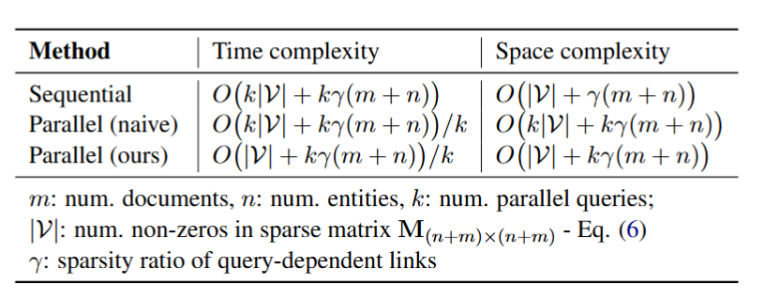
ZoomRAG 最容易被忽视、但工业界最在意的贡献,是它的 Algorithm-Parallel 版本。传统做法面临两难:串行太慢;朴素数据并行又要每次复制一整张全局图,几十条并发就会 OOM。ZoomRAG 在数学上把"跨查询共享的文档—实体图"和"每条查询独立的向量"严格解耦,只存一份全局图,再用批量矩阵运算把所有 query 的随机游走一次算完。三种方案的时间/空间复杂度对比如下。
实验结果
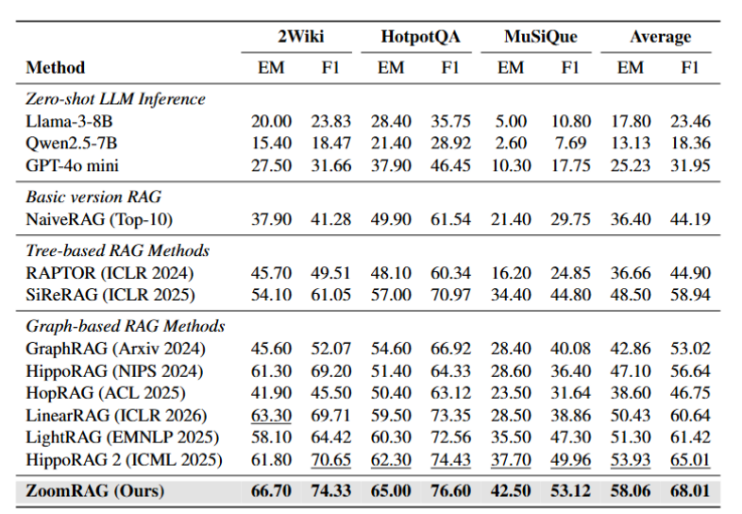
评估围绕三件事展开:多跳 QA 的答题准确率、证据检索的召回率、以及端到端的系统开销(离线索引、在线延迟、并发可扩展性)。作者在 2WikiMultiHopQA、HotpotQA、MuSiQue 三个多跳问答榜单上与 12 个基线(RAPTOR、SiReRAG、GraphRAG、HippoRAG/HippoRAG 2、HopRAG、LightRAG、LinearRAG 等)做了严格对比,所有方法均用官方代码复现,统一采用 GPT-4o-mini 作答、jina-embeddings-v3 做嵌入。
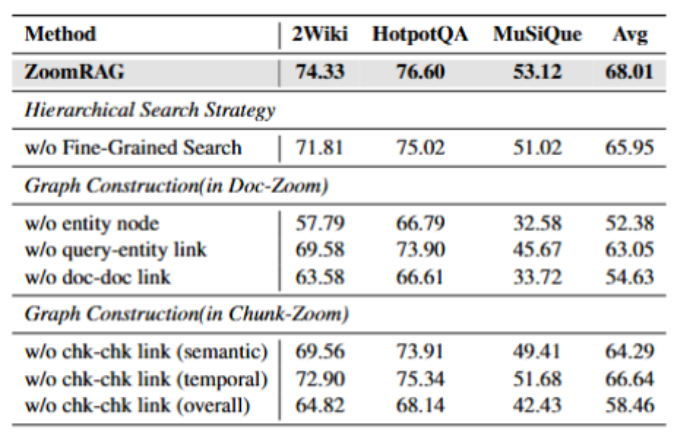
准确率:三个榜单全部 SOTA。 ZoomRAG 平均 F1 达到 68.01,比此前最强的 HippoRAG 2 高 3.0 个百分点,EM/F1 在不同数据集上的绝对提升稳定在 2.2%–4.9%。
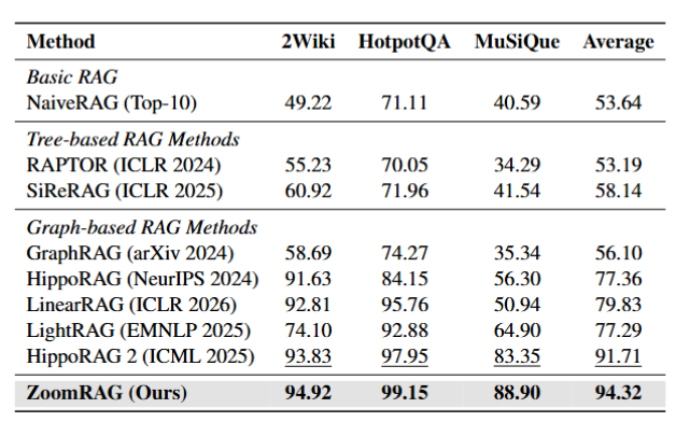
召回率:先粗后细没有丢证据。 多阶段检索的固有风险是第一阶段漏文档、后面再精细也救不回来。ZoomRAG 三个数据集上的证据召回率全部最高,平均达到 94.32%,比 HippoRAG 2 高 2.61 个百分点,在 MuSiQue 上差距拉到 +5.55 个百分点——这说明ZoomRAG 的粗筛阶段依靠全局图上的随机游走保证文档覆盖率,细筛阶段再在局部图上精确定位关键证据块,两步形成互补而不是串联叠错。
效率:这可能是 ZoomRAG 最有冲击力的数字。 离线索引平均只要 346 秒——对比 LightRAG 的 153,474 秒(约 42 小时),是 440 倍加速;对比 HippoRAG 2 的 3,343 秒,快 10 倍、省 6 倍内存。在线单条 query 平均 0.019 秒(即 19 毫秒),对比 GraphRAG 的 15.35 秒是 807 倍加速,对比目前最快的基线 LinearRAG 也仍有 6.8 倍优势。而且 ZoomRAG 的索引支持增量更新——新文档只需往邻接矩阵追加新行,不必重建整张图。
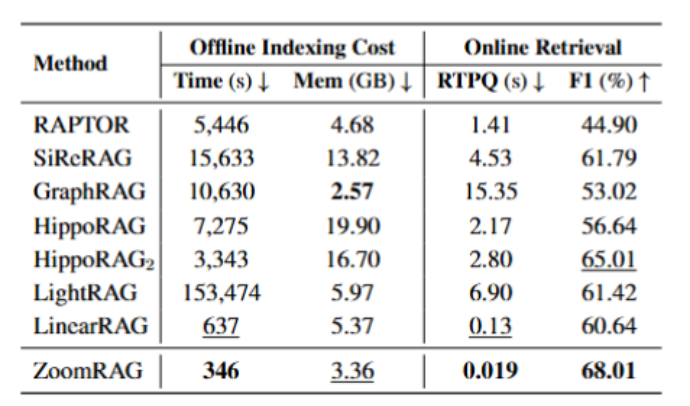
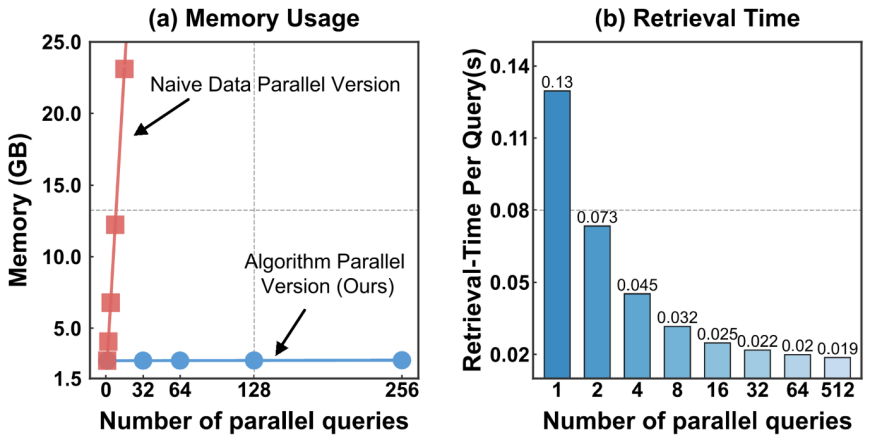
并发:512 条 query,内存几乎不动。 从 1 条并发扩到 512 条,ZoomRAG 内存增长不到 1%,单条延迟从 0.129 秒一路降到 0.019 秒;朴素数据并行的基线在 27 条并发时就 OOM 了。这个差距直接决定了系统能不能真的放进产品里服务大规模用户。
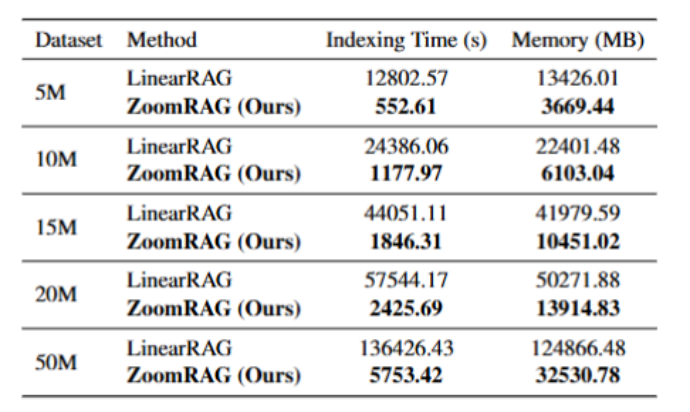
大规模扩展:5M 到 50M token 近线性。 把语料从 5M 扩到 50M token,ZoomRAG 索引时间和内存都近线性增长;50M token 下 5,753 秒、32.5 GB——相比 LinearRAG 的 136,426 秒、124.9 GB,是 23 倍加速、73% 内存节约。
一个反直觉的发现:索引做减法,效果反而更好
在所有参与对比的方法中,准确率最高的不是那些花费数万秒、调用 LLM 反复抽取三元组的知识图谱方法,而是 ZoomRAG 这个只依赖命名实体识别(NER)、甚至显得"朴素"的方案。
这说明,对 RAG 而言,"索引做得更重"和"检索效果更好"之间没有必然的正相关。知识图谱理论上能表达更丰富的关系,但三元组抽取本身是噪声来源——大模型在长文本里抽出的关系常常带幻觉和冗余,越大的图越容易把错误放大。ZoomRAG 的性能优势反而来自另一种思路:不再试图在一张大图里把所有关系一次性刻画清楚,而是让不同尺度的信息在不同阶段各司其职。对需要穿透多跳关系、找到正确证据链的任务来说,这种"先粗后细"的状态,反而比一张显式但充满噪声的知识图谱更利于检索的稳定性。
消融实验也印证了这一点:去掉粗粒度文档—文档边,平均 F1 掉 14 个点;去掉细粒度块—块边(含时序和语义),再掉 10 个点;去掉实体节点,整体塌 15.6 个点。ZoomRAG 里每一条边都不是摆设——这种"精确到位"的设计,恰恰是臃肿的知识图谱很难做到的。
写在最后
这几年结构化 RAG 的研究里,有一种"越重越强"的路径依赖:索引越做越大,图越建越复杂,好像更强的 RAG 必然意味着更昂贵的知识图谱。ZoomRAG 反着走一步——把索引做减法,把算法做加法:十分之一的索引开销、百倍级的在线加速、以及可扩展到上百并发的算法设计,换来的却是三个多跳榜单上最高的准确率。
这或许也是一个信号:在知识图谱之外,结构化 RAG 还有尚未被充分挖掘的空间。至于那些曾被默认"必须付出"的索引代价,也许值得重新审视一下。
论文:ZoomRAG: Hierarchical Random-walk Zooming across Multi-scale Information Graphs for Fast and Accurate RAG
会议:ACL 2026
单位:华东师范大学 · 复旦大学 · 西南石油大学
联系:52285901020@stu.ecnu.edu.cn | kzhang@cs.ecnu.edu.cn