作者:秋光的梦
https://zhuanlan.zhihu.com/p/2003112989201553035
近期许多基于视频生成网络的VA(也可以说是WAM)的工作,从25年末的LVP到Mimic-Video再到最近比较火的Lingbot-VA以及两篇NVIDIA的工作Cosmos Policy和DreamZero。
在小红书及各种介绍此类VA的帖子下面总看到有人说以上这些有啥区别,不就是把中间的视频生成网络换了又换,和现在VLA换VLM一个套路。
乍一看确实如此,但是假如把代码clone下来细看就完全不是一回事,也就是标题所说的形似神不似。
1.多模态Fusion方式的不同
就拿NVIDIA最近两篇Cosmos Policy和DreamZero来说,其注入视频生成模型的Latent Sequence就是非常不同的。
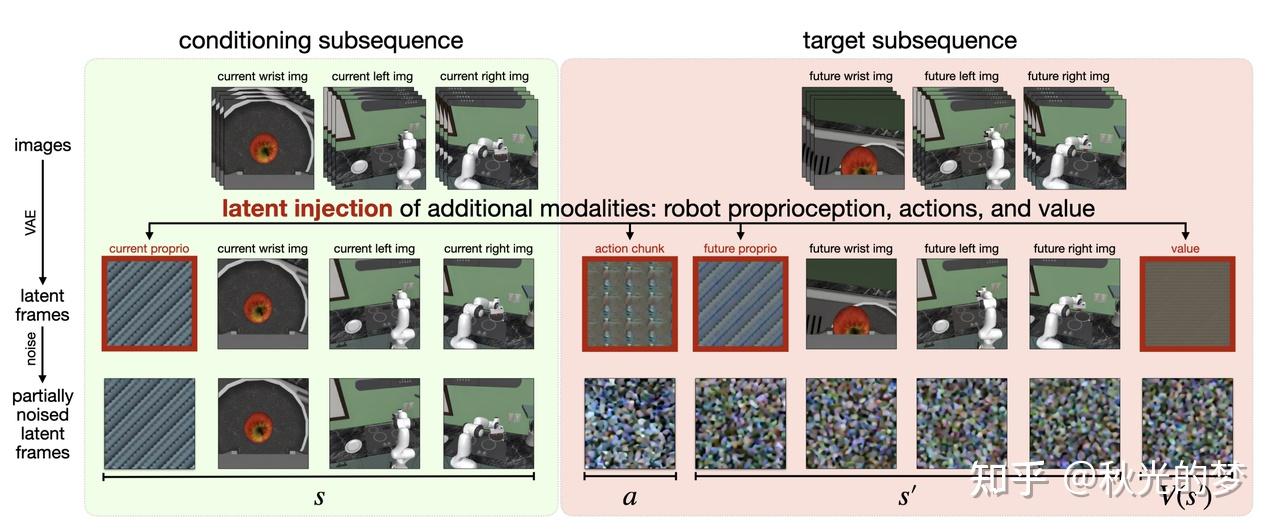
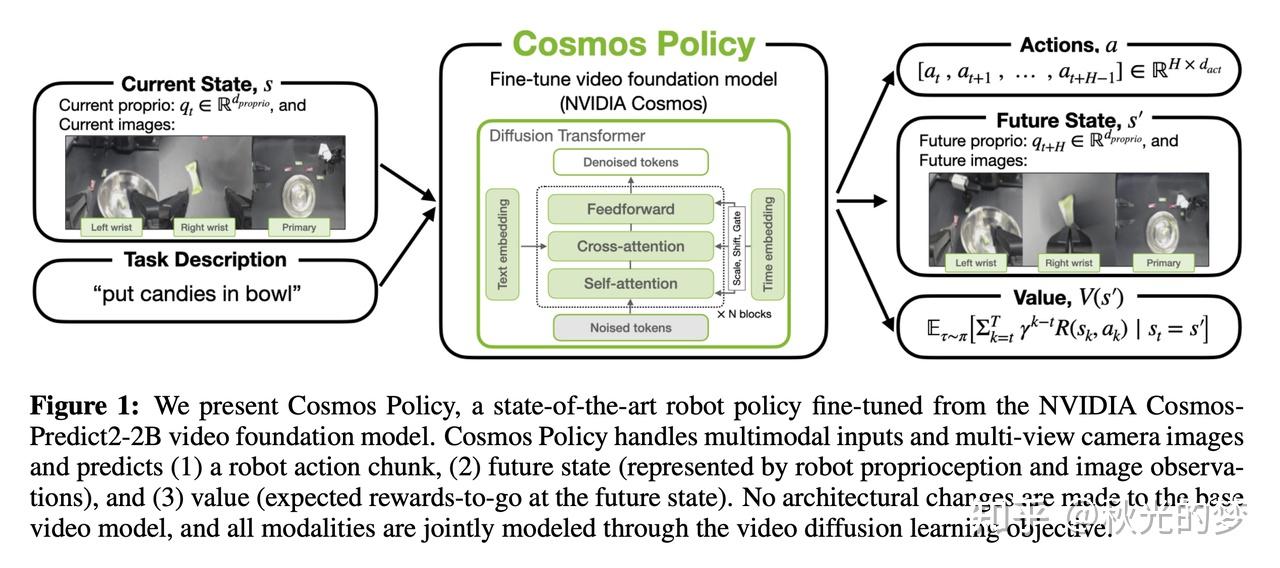
首先我们来说Cosmos Policy,其多模态融合的方式非常暴力,将端到端的精神贯彻到底。
最简洁的阐述就是其把Action,Proprio,Instruction以及Value函数全部Reshape成Images的形状,然后直接嵌入成为一个Latent Sequence喂入一个World Model(NVIDIA Cosmos),然后这个world model也就return一个对应的Latent Sequence,最后从这个Latent Sequence中重新提取出Action Chunk,Proprio以及Value的部分,再Reshape成正确的维度以输出。
具体做法是其定义了许多Index,每个输入的feature都对应一个index,然后按照index顺序嵌入到Latent Sequence中,最后解码也是按照index顺序把它解码出来。 所以在复现的时候最重要的就是这些index,每个数据集的index计算方法都是不同的。
以ALOHA数据集为例: 构造latent Sequence时有一个segment_idx,每添加一个逻辑段(current wrist/action/future image…),就 segment_idx+=1,同时把它记成 *_latent_idx(*就是当前的逻辑段名称);segment_idx是一个总的索引,不是实际帧数。每个逻辑帧会被重复num_duplicates_per_image次,但 idx 仍指向“逻辑段”。
segment_idx 内容
0 blank(tokenizer占位)
1 current_proprio(空图占位,proprio注入到latent)
2 current_left_wrist
3 current_right_wrist
4 current_primary
5 action(空图占位,action注入到latent)
6 future_proprio(空图占位,future proprio注入到latent)
7 future_left_wrist
8 future_right_wrist
9 future_primary
10 value(空图占位,value注入到latent)
而DreamZero就更为温和,其没有暴力的把Action,Proprio以及各种特征全部塞到一个Sequence里,而是将视觉、Action和Text分开注入:
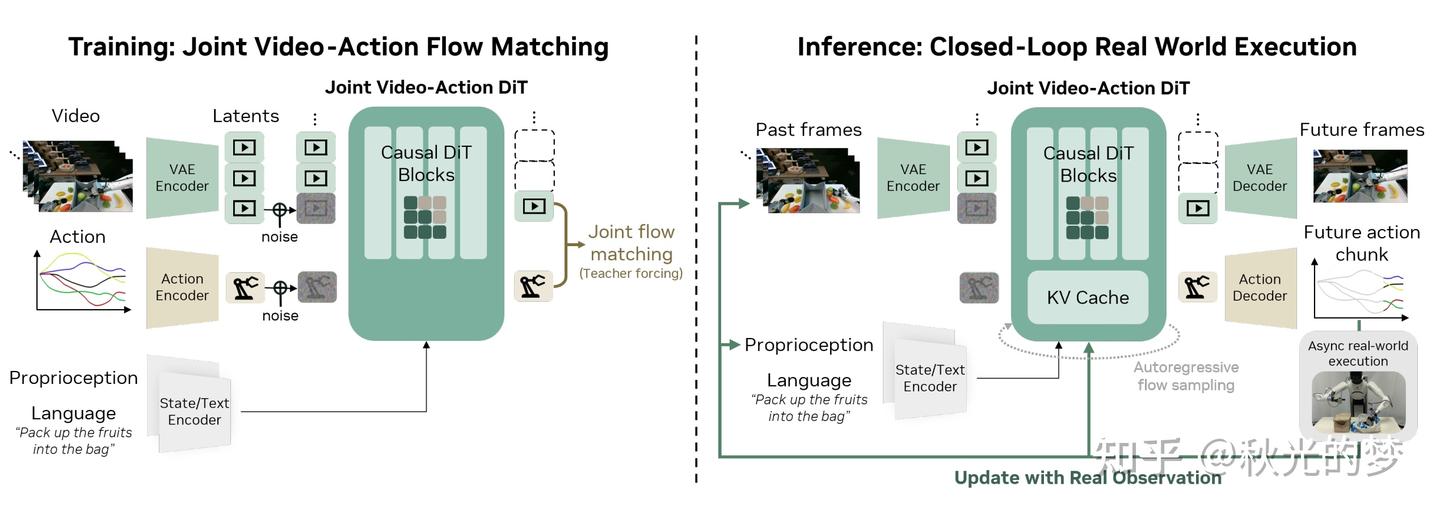
Video和Instruction在Dataloader阶段就进行了对齐。
这就显著的能看出来它们的不同。
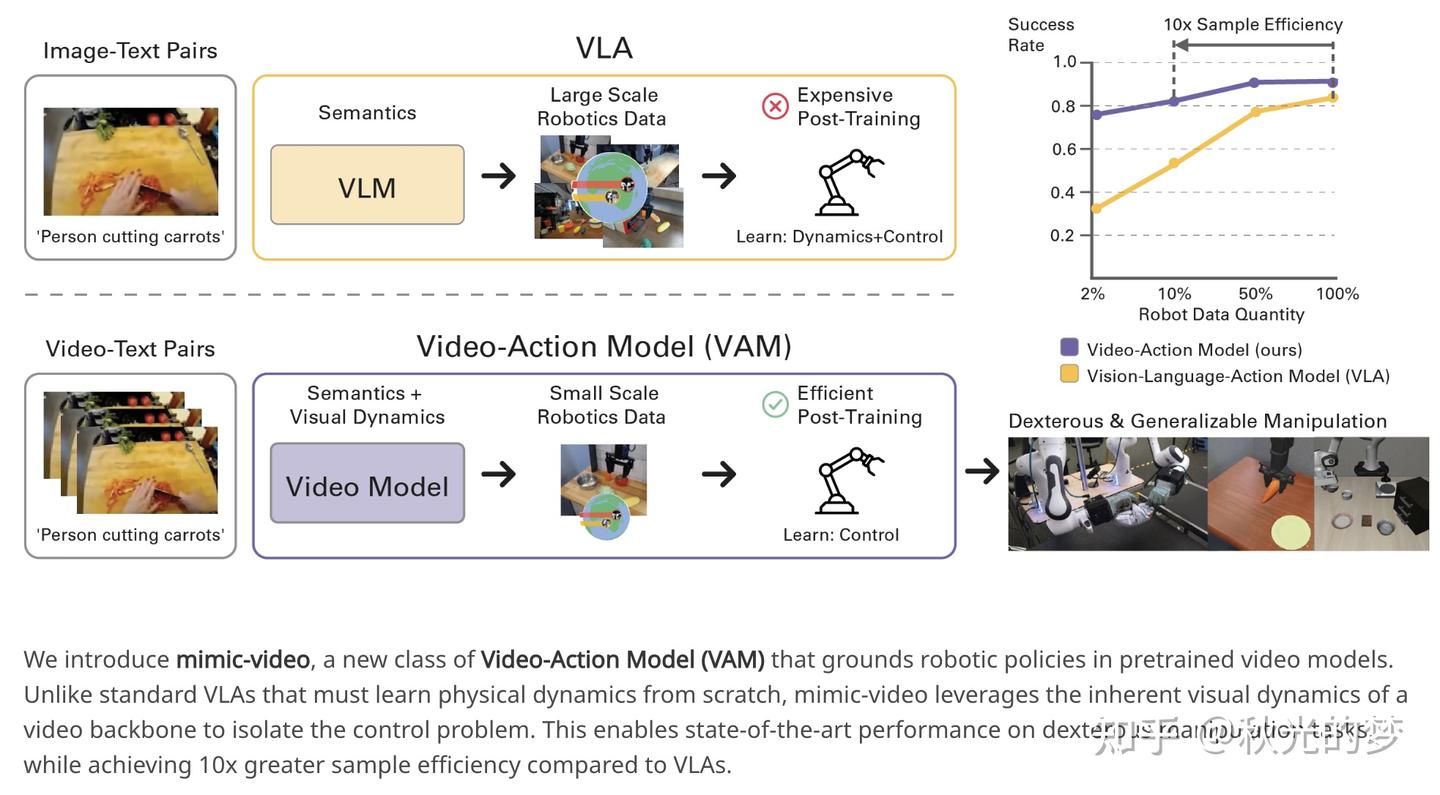
巧合的是,mimic-video的视觉backbone也是Cosmos-Predict2 (2B),但是其输入明显也是和Cosmos- Policy不一样的,从图中就可以看出,相比于cosmos-policy,mimic-video只是将视频/图片-文本对输入进了cosmos,最后通过Cross-Attention读取视频骨干的中间层特征,输出Action Chunk。
2.视频生成网络作用不同
这里就要提到LVP了,个人看来这个工作比较工程。其先通过视频生成网络生成future frame后就通过各种网络提取未来帧中的手/机械夹爪等的位姿,关节角等,
也就是说这里视频生成网络只起到了一个“生成视频”的作用,比较朴素。然后再通过网络去提取生成视频中的信息,从而得到MANO手或机械臂的位姿信息。
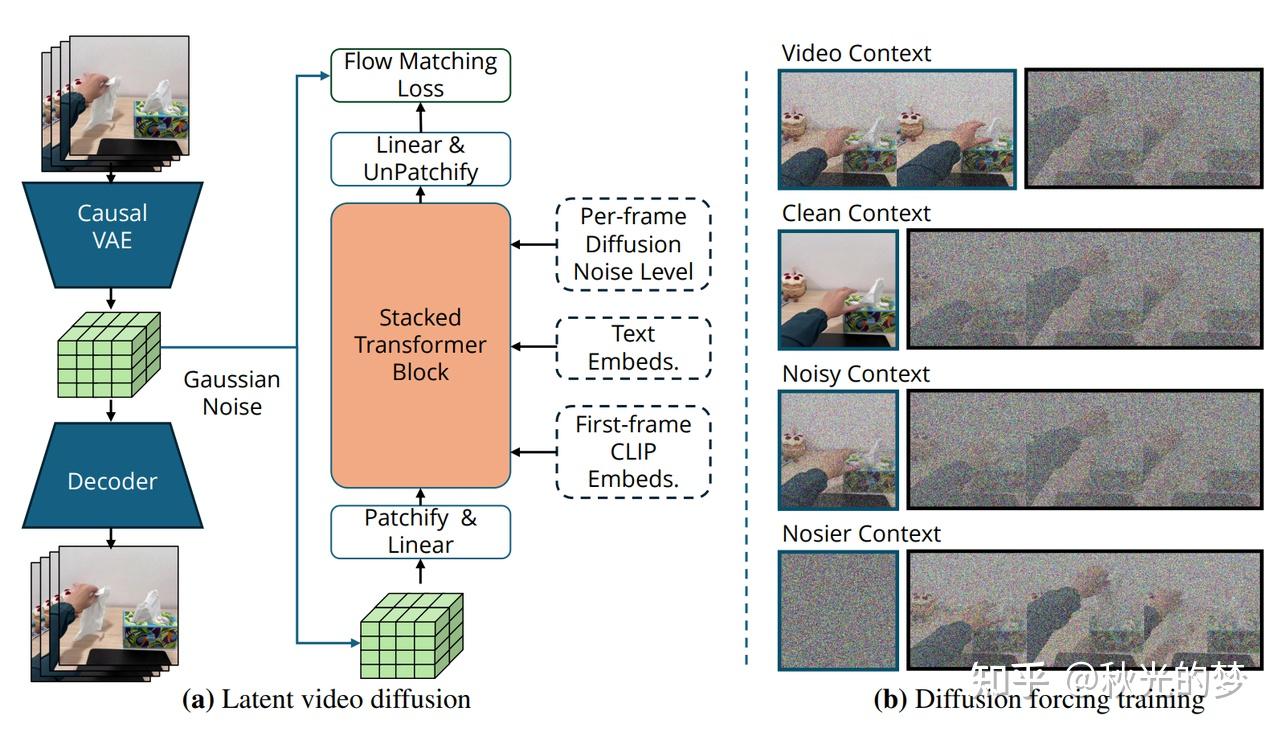
而在cosmos-policy里,视频生成网络的作用不仅仅是视频生成,而同时也会生成 Action,这就有点类似于LLM多模态的味道了,什么都是token,什么都可以输入进去。
其甚至没有传统的 Action Head,只需要从最后生成的Latent Sequence中利用Action的Idx信息将隐藏在Sequence里的 Action信息提取出来即可。
个人觉得Cosmos-Policy的想法非常好,这种多模态一起进入一个Framework有一种很优雅的感觉。但是其代码实现个人觉得写的比较丑陋,因为想法和工程之间是有gap的,不得不做一些ugly的trick去让这个想法work。
个人觉得比较丑陋的就是Cosmos的数据压缩是第一帧:单独处理,不压缩。而后续帧是每 4 张图像打包成 1 个Latent Frame。这就导致了一个问题,模型会把每 4 步的观测压成 1 个数据,导致我们分不清此时进行到了哪一步。
于是就直接把这个数据copy了四份以对上这4步的观测,这样做的目的是为了抵消模型自带的4帧压缩为1帧的机制,让每一个Latent Frame都代表了单一时间步的数据。
所以仔细阅读和理解一下代码是及其必要的,其实很多细节也在paper里写了,但是草草浏览的时候有些犄角旮旯的难免会忽略,而看代码就弥补了这个忽略。