论文:StepOPSD: Step-Aware Online Preference Distillation for Agent Reinforcement Learning
链接:https://arxiv.org/html/2605.27140v1
作者:Yanfei Zhang, Xu Lin, Chenglin Wu
做Agent post-training的人大概都遇到过同一个头疼的地方:
RL可以直接优化最终结果,但reward太稀疏,学起来慢;蒸馏能给更密集的 token 级信号,但问题是它把整条轨迹当成一段普通文本来学,根本不区分"哪步对、哪步错"。
单轮问答还好说,进入多轮Agent之后这个问题就很扎眼了。
举两个例子:
一个WebSearch Agent,前面推理都对,就是第一轮search query写歪了,后面收到的证据全跑偏,最终答错。一个 ALFWorld Agent,找到了目标物体、拿起来了、走到了正确位置,但中间少做了一次加热,最终reward还是0。
现在如果你把整条轨迹一起惩罚,模型学到的其实不是"第二步我写查询的时候出了问题",而是"这一大段都不行"——完全没有精准的错误定位。
StepOPSD要解决的就是这个:在多轮 Agent的RL训练里,把"是哪个token开始出了问题、哪个step开始出了问题"分清楚。
一句话说清楚它在做什么
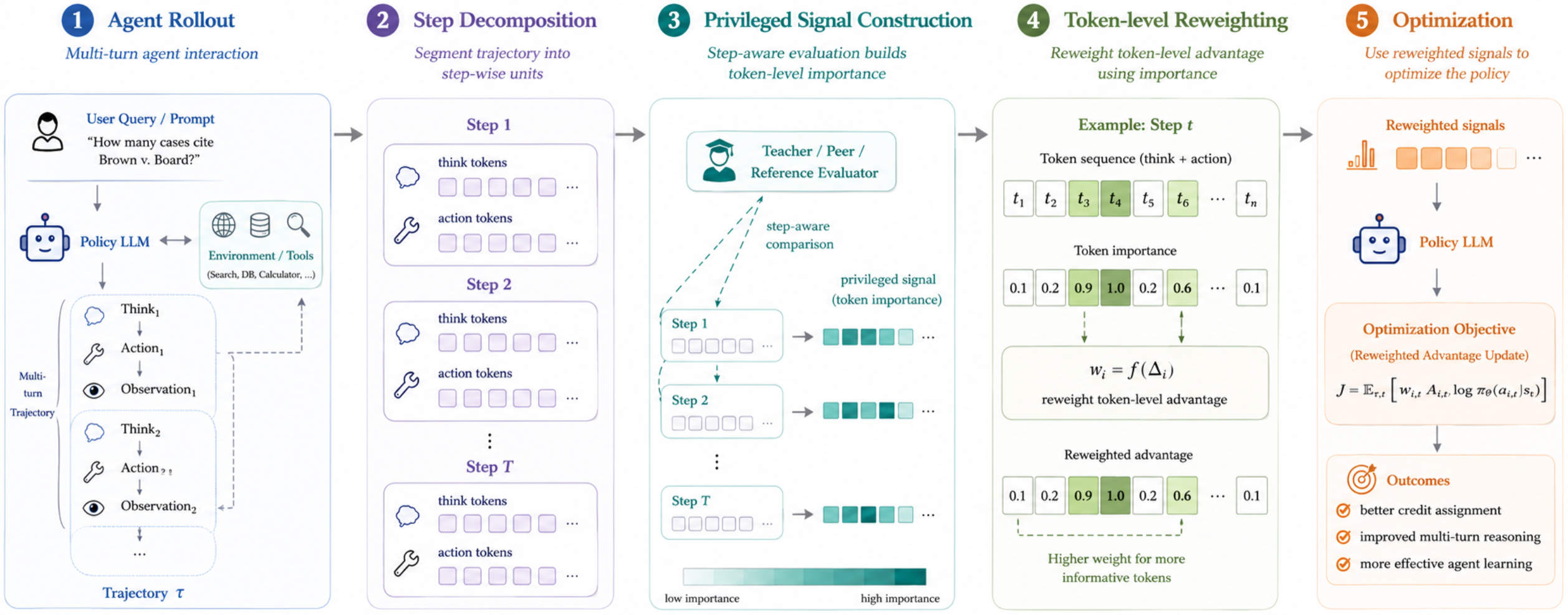
StepOPSD不是一个新的RL算法,也不替换掉GRPO。它做的事情更像是在GRPO rollout结束之后,加了一个"事后复盘"步骤:
把完整轨迹拆成以action为中心的 step,找一个知道"正确答案怎么走"的 teacher来重新打分,再把 teacher 和student的差距转化成对 advantage的局部调整。
说白了就是:RL 还是在决定往哪走,StepOPSD 只是在问——这条路上哪几步该多重视、哪几步可以少学一点。
为什么整条轨迹一起学是个问题?
标准 Agent RL 的流程是:
rollout → terminal reward → advantage → policy update
terminal reward 只告诉你最后成没成,不告诉你是哪一步导致失败的。这造成一次 malformed query、一次 invalid action、一次过早给答案,就能让几千 token 的 rollout 全盘作废。
StepOPSD 怎么做?三个关键设计
整个流程是:
rollout → reward → 拆 step → teacher/student 对比打分 → 调整 advantage → GRPO 更新
1. 只抽取模型能控制的 step
在ALFWorld这类embodied task里,用 action_only抽取——只看action,不看observation。
在Search-QA这类检索任务里,用 clean_step_no_observation——保留模型的reasoning和search query,把外部检索结果屏蔽掉。
这个细节很重要:不要把监督预算浪费在模型没办法控制的 token 上。
2. 用最终的成功/失败的标签+成功的同批轨迹当 teacher
不需要昂贵的外部黄金正确轨迹,teacher来源完全是in-place的,分为两个类别:
1、最终整个rollout是否成功/失败,其实这样的信号对于agent已经足够去做一些token层面的改动
2、在同一个 GRPO rollout batch 里,如果有成功轨迹和失败轨迹,就把成功的那条拿来做 hindsight teacher——相当于告诉模型"这道题你的某个同学走通了,是这么走的"。
然后对每个 step 的 token 计算:
Δ = log p_teacher(token | hindsight 上下文) - log p_student(token | 原始上下文)
Δ大说明teacher更认可这个token,这里可能是局部的关键决策点;Δ大但方向和 RL 信号相反,说明这里要小心。
3. 不改 RL 方向,只调大小
这是设计里最值得注意的一点。StepOPSD 没有把distillation搞成一个额外 loss去和RL抢优化方向,而是把Δ转成 advantage 的乘性权重:
w_raw = 2 × sigmoid(sign(A) × Δ)
w = clip(w_raw, 1 − α_clip, 1 + α_clip)
à = (1 − λ_mix) × A + λ_mix × w × A
两个旋钮:
λ_mix:teacher信号整体混进来多少α_clip:单个token的修正幅度上限
最重要的保证:sign-preserving——原来advantage是正的,修正完还是正的;原来是负的,还是负的。Teacher 不改变"往哪走",只改变"哪几步使劲走"。
实验结果:它在哪里最有用
在 ALFWorld 和 Search-QA 两个环境上,分别用Qwen3-1.7B和Qwen2.5-3B-Instruct跑了实验,训练最多150 steps,teacher用stale reference policy每10 steps刷新一次。
最重要的结论不是"平均分全面领先",而是:在reward和真实错误最错位的任务上,提升最明显。
ALFWorld:Heat/Cool/Pick2 最受益
Pick和Look这类简单子任务,标准RL baseline也能做得不错,StepOPSD 优势不大。
但Heat、Cool、Clean这类任务就不一样了:Agent可能大部分动作都对,只是某个状态转换没发生(比如没正确加热),最终 reward就是0。整条轨迹被一个局部错误拖死,这正是step-aware credit assignment最该发力的地方。
| 设置 | 结果 |
|---|---|
| 1.7B, λ_mix=0.05 | Heat 60.9%(vs GRPO 40.0%、SDAR 33.3%) |
| 1.7B, λ_mix=0.05 | Pick2 55.0%,该规模最好 |
| 3B, λ_mix=0.2, α_clip=0.05 | Heat 79.1%,Cool 78.9%,Pick2 95.0% |
| 3B, λ_mix=0.2, α_clip=0.05 | ALFWorld 平均 83.6% |
Pick2 难的地方是跨子目标 bookkeeping:做完第一个物体之后,得保持状态继续完成第二个。Step-level 的精准定位刚好适合这种场景。
Search-QA:query 写法的一点偏差,能决定整条证据链
NQ 相对简单,很多时候一次精准搜索就能答对,StepOPSD 优势不那么突出。
TriviaQA、PopQA、HotpotQA 对 query wording 和 bridge entity 更敏感,第一轮搜索词稍微好一点,后面的证据链可能完全不同——这里 step-level shaping 的价值更明显。
| 设置 | 结果 |
|---|---|
| 3B, λ_mix=0.05, α_clip=0.05 | Search-QA 平均 45.7%,3B 最好 |
| 3B, λ_mix=0.05, α_clip=0.05 | NQ 45.0%,TriviaQA 61.6% |
| 1.7B, λ_mix=0.05 | PopQA 45.6%,该规模最好 |
| 1.7B/3B, λ_mix=0.2 | HotpotQA 37.1% / 40.4% |
但在2Wiki、MuSiQue这类更深的多跳任务上,错误不只是某一个坏 query 造成的,而是全局证据整合和长依赖链维护的问题,局部纠错效果会被稀释。Bamboogle 则因为只要一次精准搜索就够了,强 RL baseline 已经能做得很好,提升空间本来就小。
两个旋钮到底怎么配
论文在这里做了一个值得细看的分析,追踪了 Std(Δ)的变化——也就是teacher-student gap的标准差,可以理解为"student和hindsight teacher的局部分歧是否稳定"。
一个关键时间点是step 50左右:这时 λ_mix 已经线性衰减到0,显式 shaping 停了,后面曲线主要反映成熟策略和 stale teacher 之间的漂移。
λ_mix(全局 teacher 锚定强度)
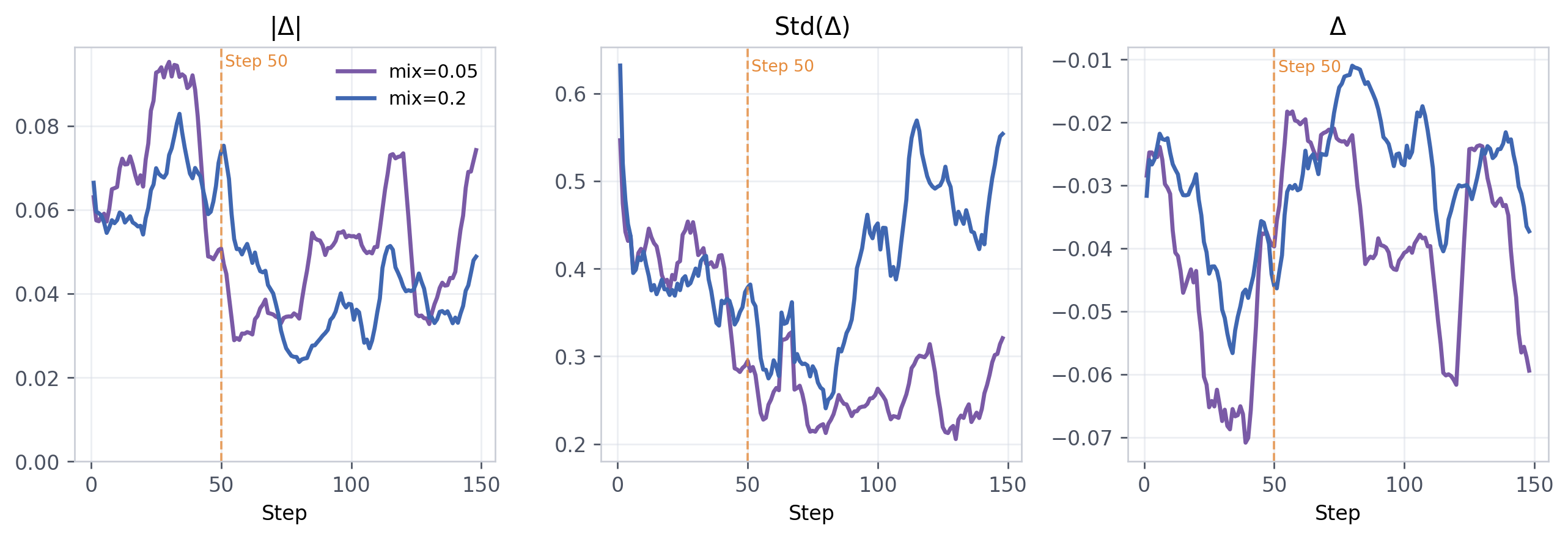
Search-QA里reward更稀疏,student 更需要teacher托着走。较强的 λ_mix能在后期保持gap variance稳定,防止策略乱漂。HotpotQA这类长证据链任务尤其明显,需要更强的锚定来压住credit assignment 噪声。
ALFWorld里反过来:Agent学会基本动作之后,过强的shaping会和环境探索打架,把策略往hindsight路径上拉,反而限制后期优化。所以行动型任务一般用更温和的 λ_mix。
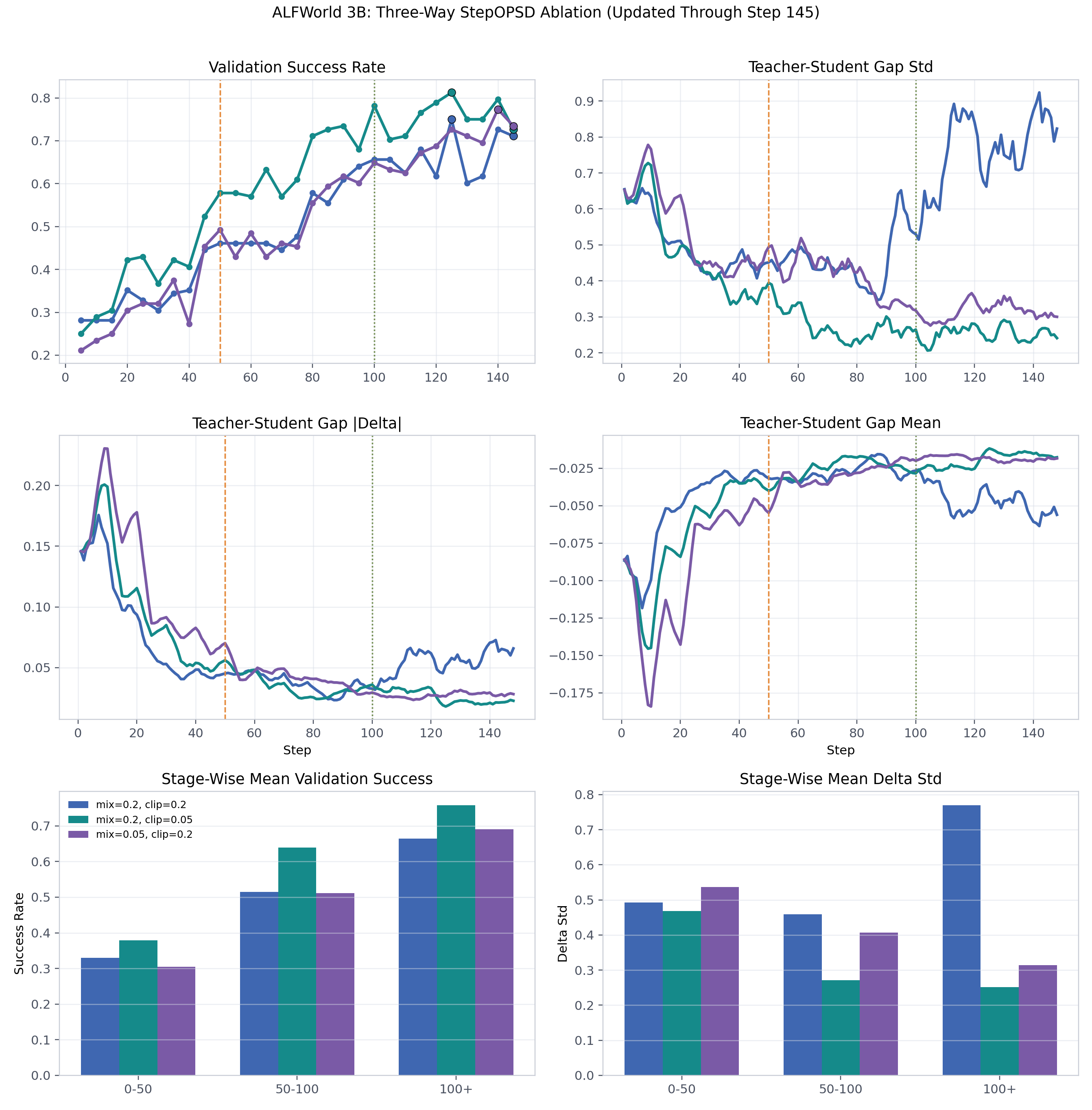
α_clip(单步修正安全阀)
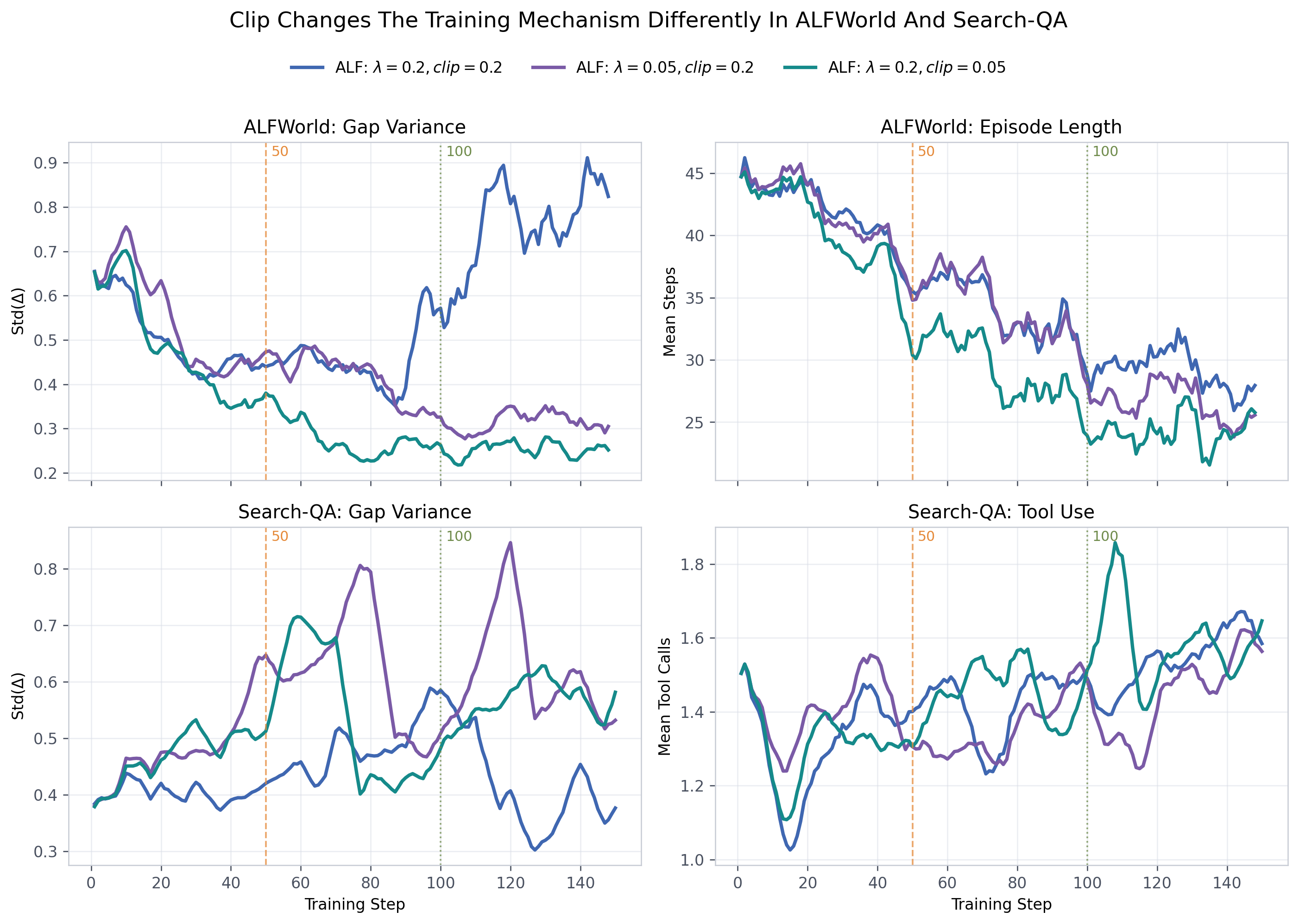
经验结论很简单:越小越安全。
3B ALFWorld 的 ablation 里,重 shaping 情况下后期 gap variance 可以跑到 0.770;把 α_clip 收紧到 0.05 之后,后期 gap variance 降到 0.252。
有意思的是,tight clipping 不是让模型"少动"。在 ALFWorld,它缩短了成熟策略的动作长度(变精简了);在 Search-QA,它反而提高了 tool use 频率(从 1.45 到 1.59),同时把平均 response 从 98.9 tokens 缩短到 86.4 tokens。
Clip 的作用不是削弱 teacher,而是防止少数几个 token 的超大修正量劫持整个 update。
这篇工作真正在说什么
StepOPSD背后有一个值得单独拎出来的判断:
多轮Agent任务的训练难点,很多时候不是reward不够强,而是reward的粒度不对。
如果失败是由某一个局部action决定的,把最终reward均匀广播给整条轨迹,本身就是在注入噪声。
StepOPSD的修正方式很克制:
- 不引入额外value model
- 不要求teacher在线干预生成
- 不改变RL advantage的正负方向
- 只在rollout之后,把hindsight信息回填到关键step的advantage幅度上
这种克制是有意为之的。Agent 训练里最怕的不是信号少,而是信号强但对错了地方。
一些人写的碎碎念
我们这个研究的落脚点其实是在Agentic Self-awareness,也即agent如何在rollout过程中能够提升对自我完成任务的“意识”,如何判定任务最终完成,以及状态转移是否对完成任务起到了积极作用。
我们在当前的科研中,对这个问题的回答是相对粗糙的,后续我们会更进一步textual world model训练的角度来对这个问题进行解答;我相信类似WMA在具身智能这块取得了较为优异的成绩(强先验带来的效果提升),在agent内,同样也需要从token级别切换成state级别,对state级别进行整体操作,才是能够使得agent能力在各个不同类别的方面上持续提升的核心思路。
我本人目前在兴业证券投行工作,同时服务多家AI及泛AI产业企业,也希望自己在AI这块的科研能够同时服务于AI科学前沿发展与中国的AI产业蓬勃发展。