作者:方弦
https://zhuanlan.zhihu.com/p/2020514624856957623
记录整理一下最近学习vllm和sglang源码的一些思考和笔记。
其中包含了和LLM交互问答得到的一些内容(源码分析和注释等部分),用于加深对现代高性能推理引擎实现的理解。分析基于的源码版本更新到了: c01ee848b (2026/3/24)。如有错漏,欢迎指正,覆盖不全,仅供参考。
本文不重复源码逐行解读。
0. 这篇文章的读法
本文探讨”为什么”(why)——设计决策的动机、核心矛盾、以及各模块如何共同构成一个协调一致的系统。后续会有对各个模块的详细解析,尽可能把“如何做“(what)说清楚。
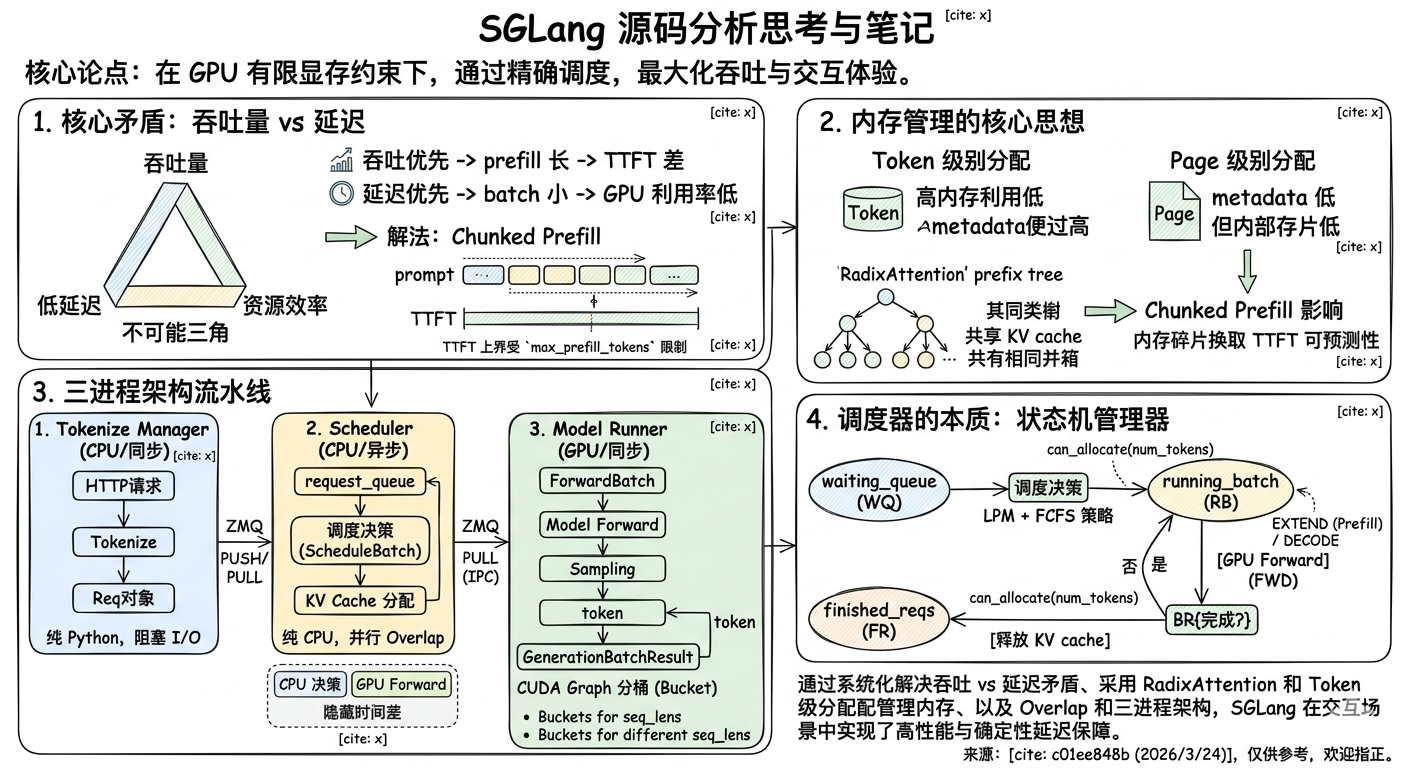
0.1 核心论点
SGLang 的设计哲学可以用一句话概括:
在 GPU 有限的显存约束下,通过精确的调度决策,最大化端到端吞吐与交互体验。
这个目标驱动了 Scheduler、KV Cache、Model Runner、Attention Backend 四个子系统几乎所有的设计决策。
1. 核心矛盾:吞吐量 vs 延迟
1.1 三种 serving 范式的取舍
LLM serving 存在经典的不可能三角(吞吐量、低延迟、资源效率),不同框架的核心区别在于在不可能三角中选择哪个顶点作为首要约束:
| 调度目标 | 吞吐量 | 延迟 | 资源效率 | 核心约束 | 代表 |
|---|---|---|---|---|---|
| 吞吐优先 | ★★★ | ★ | ★★ | batch size 足够大 | HuggingFace TGI |
| 吞吐优先,兼顾延迟 | ★★ | ★★ | ★★★ | 内存不溢出 | vLLM / SGLang(通用) |
| 延迟可预测优先 | ★★ | ★★★ | ★★ | TTFT 上界显式可控 | SGLang(有 SLA 保障需求) |
关于 vLLM 与 SGLang 的区分:两者都支持 Continuous Batching 和 Chunked Prefill。
核心差异在于首要约束:vLLM 以内存不溢出为首要约束(内存满时触发 Chunked Prefill);SGLang 支持以 TTFT 上界为首要约束(max_prefill_tokens控制每次 prefill 的最大 token 数,上限可控)。
vLLM 同样广泛部署于交互应用;SGLang 的优势在于对延迟有确定性保障需求的场景。
1.2 矛盾的具体表现
吞吐优先:batch 越大越好 → prefill 越长 → TTFT 越差
延迟优先:prefill 尽可能短 → batch 越小 → GPU 利用率越低
SGLang 的解法:Chunked Prefill(分块 prefill)
每次 prefill 不超过 max_prefill_tokens(默认 16384 tokens),将长 prompt 拆成多个 chunk:
TTFT 的上界受 max_prefill_tokens 限制,而不是整个 prompt 的处理时间
代价:长 prompt 被拆分后,KV cache 无法被完全复用(见第 4 节)
1.3 Prefill 和 Decode 能混合吗?
混合调度:prefill_chunk + decode 同时运行 → GPU 利用率最高
但 decode 延迟被 prefill 干扰 → 用户体验下降
分离调度:纯 prefill 批 + 纯 decode 批交替 → 体验稳定
但 GPU 可能空闲 → 吞吐量下降
SGLang 默认采用混合调度,但通过 chunked_req 机制控制 prefill 时间片,在吞吐和延迟之间取得平衡。
2. 抽象层次:从请求到 token 的四层模型
2.1 为什么需要这么多层?
SGLang 处理一个请求,需要跨越 Python 进程、CPU、GPU 三种运行环境:
请求 (Python HTTP)
↓
Req 对象 (Python heap) ← 跨进程:Tokenize Manager
↓
ScheduleBatch (Python heap) ← CPU:Scheduler 决策
↓
ModelWorkerBatch (CPU→GPU 边界) ← CPU/GPU 拷贝
↓
ForwardBatch (GPU VRAM) ← GPU:实际计算
每层边界的约束:
- Python ↔ GPU:序列化开销巨大,必须批量打包
- CPU ↔ GPU:PCIe 带宽远低于 GPU 算力,必须最小化内存拷贝
- Scheduler ↔ Model Runner:两者解耦才能支持 overlap(见 2.3)
2.2 四种 Batch 类型的关系
Req(请求粒度)
↕ 打包(ScheduleBatch.init_new)
ScheduleBatch(调度决策粒度)
↕ to_model_worker_batch()(进程边界拷贝)
ModelWorkerBatch(跨进程边界)
↕ init_forward_batch()(GPU 分配)
ForwardBatch(GPU 执行粒度)
关键设计洞察:ScheduleBatch 和 ForwardBatch 是同一数据的不同视图(view)。
它们不是两个独立数据结构——ScheduleBatch 在 CPU 侧构造元数据(哪些请求、哪些 token),然后通过零拷贝(zero-copy)的 tensor 引用直接映射到 GPU tensor:
# 源码: python/sglang/srt/managers/schedule_batch.py:1220-1255
@dataclasses.dataclass
class ScheduleBatch:
# 这些 tensor 在 CPU 侧构造
req_pool_indices: torch.Tensor # shape: [b], 请求在 req pool 中的索引
seq_lens: torch.Tensor # shape: [b], 每个请求的序列长度
input_ids: torch.Tensor # shape: [b], 输入 token IDs
output_ids: torch.Tensor # shape: [b], 输出 token IDs
# Model Runner 直接使用这些 tensor,不需要重新拷贝
# 只需要确保它们在正确的 device(GPU)上
2.3 为什么需要 Overlap?
传统做法:Scheduler 在 CPU 上做完所有决策 → 等待 GPU 完成当前 batch → 再调度下一个
CPU 决策时间 (50μs) ─────► GPU Forward (1ms) ─────► 下一个调度
↑ CPU 在这里空闲等待
SGLang 的 Overlap 机制:
# 源码: python/sglang/srt/managers/scheduler.py:2163-2177
# 在 GPU 执行当前 batch 的同时,CPU 已经在准备下一个 batch
# get_next_batch_to_run() 和 model_runner.forward() 并行执行
if (
not self.running_batch.is_empty()
and not self.running_batch.is_prefill_only
):
self.running_batch = self.update_running_batch(self.running_batch)
ret = self.running_batch if not self.running_batch.is_empty() else None
# CPU 在 GPU 执行时已经完成了下一个 batch 的调度准备
Overlap 使调度开销(50μs)在 GPU forward 时间(1ms+)中被完全隐藏。
3. 调度器的本质:状态机管理器
3.1 调度器的三个核心职责
SGLang 的 Scheduler 不是"批处理算法",而是一个请求状态机管理器:
flowchart TD
WQ["waiting_queue"] --> DEC["[调度决策]"]
DEC -->|"分配 KV cache"| RB["running_batch"]
RB --> FWD["[GPU Forward]"]
FWD --> BR{完成?}
BR -->|"否:继续 decode"| RB
BR -->|"是"| FR["finished_reqs"]
FR -.->|"释放 KV cache"| DEC
RB -.->|"下次调度"| DEC
style WQ fill:#dae8fc,stroke:#6c8ebf
style RB fill:#fff2cc,stroke:#d6b656
style FR fill:#f8cecc,stroke:#b85450
style FWD fill:#e1f5c4,stroke:#9ace5a
style DEC fill:#e8e8e8,stroke:#999
职责一
维护请求状态 每个 Req 对象记录请求的完整生命周期状态:
- 当前是 prefill 阶段还是 decode 阶段
- 已生成多少 token(output_ids)
- 分配了哪些 KV cache 槽位
- 是否有 grammar 约束需要等待
职责二
决定调度时机 什么条件下,从 waiting_queue 调度新请求到 running_batch:
- 内存充足:can_allocate(num_tokens) == True
- batch 未满:running_batch.batch_is_full == False
- 没有资源冲突:没有正在处理的 chunked prefill
- 优先级满足:waiting_queue 中的请求优先级顺序
职责三
管理内存分配 Scheduler 持有 req_to_token_pool 和 token_to_kv_pool_allocator,每次调度时决定分配多少 KV cache 槽位。
3.2 调度策略的权衡
SchedulePolicy 决定从 waiting_queue 选择哪些请求加入 running_batch:
| 策略 | 逻辑 | 优点 | 缺点 |
|---|---|---|---|
| FCFS | 先来先服务 | 公平、简单 | 短请求等长请求 |
| LPM | 最长前缀匹配优先 | 优先调度前缀匹配最长的请求,最大化 KV cache 命中率;同前缀请求批量处理 | 队列过长时 O(n²) 排序开销大;跨不同前缀的短请求可能饿死 |
| RANDOM | 随机选择 | 避免最坏情况 | 不可预测 |
SGLang 默认策略是LPM + FCFS 的组合:队列长度 ≤ 128 时按前缀匹配长度排序选取;队列过长时自动降级为 FCFS 避免 O(n²) 开销。
3.3 正确性约束 vs 性能优化
调度器必须在多个正确性约束下工作:
约束1:内存不溢出
running_batch 的总 token 数 ≤ KV cache pool 大小
→ 每次调度前必须检查 token_to_kv_pool_allocator.available_size()
约束2:prefix cache 正确性
相同前缀的请求必须路由到相同的 KV cache 位置
→ RadixAttention 保证 tree 结构的一致性
约束3:grammar 约束
grammar 编译未完成的请求不能参与调度
→ grammar_manager.poll() 返回就绪请求后才加入 waiting_queue
约束4:TP 一致性
所有 TP rank 必须就同一批请求达成一致
→ 跨 rank 用 all_reduce 同步调度结果
几乎所有调度器的复杂度都来自于在满足这些约束的同时,最大化 GPU 利用率。
4. 内存管理的核心思想
4.1 两种粒度的内存分配
SGLang 的 KV cache 内存分配有两个粒度:
Token 级别分配(精细):
每个 token 一个 kv_pool 槽位
优点:内存利用率高(按需分配,无 page 内部碎片)
缺点:元数据开销大(每个 token 需要独立追踪槽位);碎片化来自分配器管理的外部碎片
Page 级别分配(粗粒度):
每 N 个 token 一个 page
优点:元数据少(一个 page 一条记录);分配/释放快
缺点:内部碎片(page 尾部未用空间浪费)
SGLang 默认使用Token 级别分配,通过 RadixAttention 的前缀树结构管理复杂共享关系。
4.2 分配策略:先到先得 vs 按需分配
先到先得(FIFO):
- 第一个请求分配 [0, N) 的 kv_pool 槽位
- 后续请求分配相邻的空闲槽位
- 优点:简单;
- 缺点:容易产生内存碎片
按需分配 + 压缩:
- SGLang 的做法:新请求从 waiting_queue 调度时,动态计算需要多少槽位
- 运行过程中如果请求完成,释放槽位并压缩(defragment)
# 源码: python/sglang/srt/managers/scheduler.py:2080-2137
def get_next_batch_to_run(self) -> Optional[ScheduleBatch]:
# 1. 过滤已完成的请求
if self.dllm_config is not None:
self.dllm_manager.filter_finished_reqs()
# 2. 合并 prefill batch 到 running batch
if self.chunked_req is not None:
self.stash_chunked_request(self.chunked_req)
# 3. 如果 GPU 正在运行,继续处理 running_batch
# 4. 如果 GPU 空闲且有新 prefill 请求,启动新的 batch
4.3 Chunked Prefill 对内存的影响
这是 SGLang 最微妙的设计之一。考虑一个 10,000 token 的 prompt:
不分块:
一次性分配 10,000 个 kv_pool 槽位
所有 10,000 个 token 的 KV cache 都可以被复用
分块(假设 128 tokens/chunk):
每个 chunk 分配 128 个槽位
chunk 1 → chunk 2 → ... → chunk 78(最后一块)
中间的 KV cache 在 chunk 之间无法共享给其他请求
内存碎片化程度更高
为什么仍然选择分块? 因为内存碎片换取的是 TTFT 的可预测性。对于面向用户的服务,用户宁可每次等待有限时间也不要等待数秒。
5. 关键数据流:请求的lifecycle
5.1 完整数据流图
flowchart TD
subgraph TokenizeManager["Python 进程(跨进程)"]
HTTP[HTTP 请求]
TM[Tokenize Manager]
Req[Req 对象]
end
subgraph Scheduler["Scheduler 进程(CPU)"]
WQ[waiting_queue]
RB[running_batch]
POLL[grammar_manager.poll]
SCHED[SchedulePolicy 决策]
BATCH[new_batch]
end
subgraph ModelRunner["Model Runner(GPU)"]
MWB[ModelWorkerBatch]
FB[ForwardBatch]
FWD[Model Forward]
LOGITS[Logits → Sampling]
RESULT[GenerationBatchResult]
end
HTTP --> TM
TM --> Req
Req --> WQ
POLL --> WQ
WQ --> SCHED
SCHED --> BATCH
BATCH --> RB
RB --> MWB
MWB --> FB
FB --> FWD
FWD --> LOGITS
LOGITS --> RESULT
5.2 Prefill 请求的完整路径
1. Tokenize Manager(进程边界)
HTTP 请求 → tokenize(prompt) → Req 对象(包含 origin_input_ids)
2. Scheduler(CPU 调度)
Req 进入 waiting_queue
SchedulePolicy 选择该请求 → ScheduleBatch.init_new()
分配 req_pool_idx + kv_pool 槽位
设置 forward_mode = EXTEND
3. Model Worker Batch(CPU→GPU 边界)
to_model_worker_batch() → 将 tensor 拷贝到 GPU
分配 out_cache_loc(KV cache 写入位置)
4. Forward(GPU 执行)
embedding lookup → QKV projection → Attention → O projection → MLP
→ 每个 transformer 层:保存 K/V 到 token_to_kv_pool
→ 最后输出 logits
5. Sampling(GPU → CPU)
logits → grammar_bitmask 过滤 → temperature sampling → token
→ 更新 Req.output_ids
→ 判断:是否完成?(eos 或 max_tokens)
6. Scheduler(CPU 收尾)
如果完成:从 running_batch 移除 Req → 返回结果给 Tokenize Manager
如果未完成:Req 留在 running_batch → 参与下次 decode 调度
5.3 Decode 请求的完整路径
Decode 和 prefill 的关键区别:
| 维度 | Prefill | Decode |
|---|---|---|
| 输入 | 整个 prompt + 已生成 tokens | 仅最后一个 token |
| KV cache | 写入 | 读取 + 追加写入 |
| Forward 模式 | ForwardMode.EXTEND | ForwardMode.DECODE |
| Attention 类型 | Causal(全连接到历史) | 参与 token 数 |
| Prefill | ✓ | 整个 prompt | O(\mathrm{seq\_len}^2) |
|---|---|---|---|
| Decode | ✓ | 历史 + 1 新 token | O(\mathrm{seq\_len}) |
Decode 阶段的 attention 永远是对全部历史 token 的 causal attention,但 KV cache 的累积使每个 decode step 的实际计算量不变(只是 O(1) 的矩阵乘法)。
6. 进程间通信:为什么需要三个进程?
6.1 三进程架构的设计动机
传统 LLM serving 的问题:
- Tokenize/Detokenize 是 CPU 密集(Python GIL 阻塞)
- Model Forward 是 CUDA 密集(GPU 空闲等待)
→ 两个阶段在同一进程内互相阻塞,GPU 利用率低
SGLang 解法:流水线
┌────────────┬────────────┬────────────┐
│ Tokenizer │ Scheduler │ Model │
│ Manager │ │ Runner │
│ (CPU/同步) │ (CPU/异步) │ (GPU/同步) │
└────────────┴────────────┴────────────┘
│ │ │
│ ZMQ PUSH/PULL │ ZMQ PUSH/PULL │
│◄─────────────┼─────────────►│
│ 多路复用 │ IPC │
Tokenizer Manager:纯 Python,阻塞 I/O,用 asyncio 实现多路复用,不占用 GPU 时间。
Scheduler:纯 CPU 逻辑(调度决策、内存分配),与 GPU forward 并行执行(overlap)。
Model Runner:CUDA 代码,一旦开始 forward 就不能中断,必须保证足够的 batch size。
6.2 IPC 通道:ZMQ Socket
三个进程通过 ZMQ PUSH/PULL socket 通信(asyncio 用于 Tokenizer Manager 内部的 HTTP 异步 I/O):
Tokenizer Manager Scheduler
│ ▲
│ request_queue.put(req)(ZMQ PUSH) │
│ │
└─────────────────────────────────────────┘
IPC(ZMQ PUSH/PULL)
Scheduler Model Runner
│ ▲
│ forward_queue.put(batch)(ZMQ PUSH) │
│ │
└─────────────────────────────────────────┘
IPC(ZMQ PUSH/PULL)
Scheduler 前置队列(request_queue)的缓冲区大小影响吞吐和延迟的权衡:
- 队列大:请求等待时间长 → TTFT 增加;但 GPU 始终有请求可处理 → 吞吐高
- 队列小:请求等待时间短 → TTFT 低;但请求到达间隔不均匀时 GPU 可能空闲 → 吞吐下降
最优值取决于请求到达率与 GPU 处理能力的匹配程度。
7. Attention Backend 的策略选择
7.1 为什么需要多种 Attention Backend?
不同模型规模、硬件配置下,最优的 attention 实现不同:
| Backend | 适用场景 | 显存占用 | 速度 |
|---|---|---|---|
| FlashAttention-2 | 通用(≤ 32K seq) | 中 | 快 |
| FlashInfer | 长序列(> 32K)/ Decode 阶段 | 中 | 解码优化 |
| NSA(Native Sparse Attention) | DeepSeek-V3 稀疏 pattern | 低 | 稀疏 pattern 下最快 |
| Triton FlashAttention | 定制 kernel | 中 | 取决于实现 |
SGLang 的设计原则:Backend 可插拔。
# 源码: python/sglang/srt/attention/layer.py
class Attention:
def __init__(self, layer_id, ...):
backend = get_attention_backend(
self.server_args.attention_backend,
self.model_config,
query.size(1), # seq_len
)
self.impl = backend.get_supported_func(prefix, ...)(...)
同一个模型,在 seq_len=1K 和 seq_len=100K 时,应该使用不同的 backend。
7.2 CUDA Graph 的本质约束
CUDA Graph 要求一个图中的所有操作在形状(shape)上完全一致。这对 LLM serving 造成了一个根本性约束:
CUDA Graph 带来的约束:
同一个 graph capture 中,所有 tensor 的 shape 必须固定
SGLang 的做法:
1. 按 seq_len 分桶(bucket)
bucket_0: [1, 128] tokens
bucket_1: [128, 512] tokens
bucket_2: [512, 2048] tokens
...
2. 每个 bucket 捕获一个独立的 CUDA Graph
3. 调度时,将请求路由到对应的 bucket
4. 如果请求的 seq_len 跨越 bucket 边界 → 不使用 CUDA Graph
这解释了为什么 SGLang 对短序列(<= 2K)的加速效果最明显——大部分请求落入固定 bucket,可以命中 CUDA Graph。
8. 设计哲学总结
8.1 SGLang 的五个核心原则
| 原则 | 表现 | 权衡 |
|---|---|---|
| 交互体验优先 | Chunked Prefill、Streaming | 吞吐量低于离线批处理 |
| CPU/GPU 完全 overlap | Scheduler 和 Model Runner 并行 | 调度逻辑复杂度增加 |
| 内存效率至上 | Token 级别分配、RadixAttention | 分配器实现复杂 |
| 可插拔抽象 | Attention Backend、Grammar Backend | 接口抽象的运行时开销 |
| 配置即策略 | ServerArgs 控制所有行为 | 参数空间庞大,调优困难 |
8.2 与 vLLM 的核心区别
SGLang 和 vLLM 在大部分功能上高度重叠:Continuous Batching、Chunked Prefill、Prefix Caching、Speculative Decoding 等两者都有。核心差异在于架构哲学和调度侧重点:
vLLM:调度决策以内存压力为首要约束
→ 内存满时拆分 prefill;decode 队列饥饿时优先插入 prefill
→ GPU 利用率高,长 prompt TTFT 受 batch 队列深度影响
SGLang:调度决策以延迟目标为首要约束
→ `max_prefill_tokens` 显式约束每次 prefill 最大 token 数
→ TTFT 更可预测,高并发下 decode 饥饿时可能暂停 prefill 插入
两者在吞吐量和延迟上的实际表现,取决于具体场景(SGLang 在长 prompt + 低延迟场景占优,vLLM 在高吞吐优先场景占优),需要实测对比而非哲学推断。
唯一真正独有的功能差异:Grammar 约束。 vLLM 没有在采样阶段过滤非法 token 的机制,JSON Schema、正则等约束必须靠 prompt engineering + 后处理重试,SGLang 可以从源头保证格式正确。
8.3 选型建议
| 需求 | 推荐 |
|---|---|
| 需要 JSON Schema、正则、XGrammar 约束 | SGLang |
| 团队已有 vLLM 经验、需求不特殊 | vLLM |
| 其他场景(主流模型、无特殊约束) | 两者均可,建议实测对比 |
没有绝对正确的选择:SGLang 和 vLLM 的性能差距在具体场景下可能反转,选型更多取决于团队熟悉度和功能需求,而非框架本身的高低。
9. 常见误解澄清
误解 1:SGLang 用了 Continuous Batching 所以吞吐量一定高
真相:Continuous Batching 解决的是 GPU 空闲问题,不解决"batch size 是否足够大"的问题。如果请求的 average output length 很长(> 500 tokens),decode 阶段仍然是 memory-bound,GPU 利用率不一定高。
误解 2:RadixAttention 可以让所有相同前缀的请求共享 KV cache
真相:RadixAttention 保证的是"相同前缀的请求写入相同的物理位置",但是否命中共享,取决于请求到达的时序——第一个请求建立前缀 KV cache,后续请求才能共享。如果前缀建立后 cache 被 evicted,就无法共享。
误解 3:Overlap 让调度开销变成零
真相:Overlap 只隐藏了"下一个 batch 的调度决策"时间。如果 GPU forward 时间很短(比如极短的 decode batch),overlap 可能仍然不够,且 CPU 调度本身可能成为瓶颈。
误解 4:多 TP 时,Scheduler 在所有 rank 上运行相同逻辑
真相:Scheduler 只在 rank 0 上运行调度决策,其他 rank 通过 all_reduce 同步结果。这避免了在每个 rank 上重复计算调度决策的开销。