作者:Haoning Wu
https://www.zhihu.com/question/1999487395494588876/answer/2000362433332660070
Big Model Smell
作为一个在这个项目里拧了几个月螺丝的工程师,release 之后看到大家讨论,挺多感触的,说几句 behind-the-scenes 吧。
我 identify 我是一个做 VLM 的人,那我就从这个视角聊一下。
Big Model Smell? 啥意思?
两三个月之前,我刚刚第一次见识到这个模型有多聪明的时候,发了一条 X,只有三个单词 ”big model smell“。那个时候 K2-Thinking正火热,好多人以为这是一句关于 K3 的预告,成了我有史以来被点赞最多的一次....
但其实这只是一句个人感想。一个训了很久小模型的人第一次 babysit 大模型的人的感想。
What does this mean? 什么是 big model?
我们首先看这张图。官图。
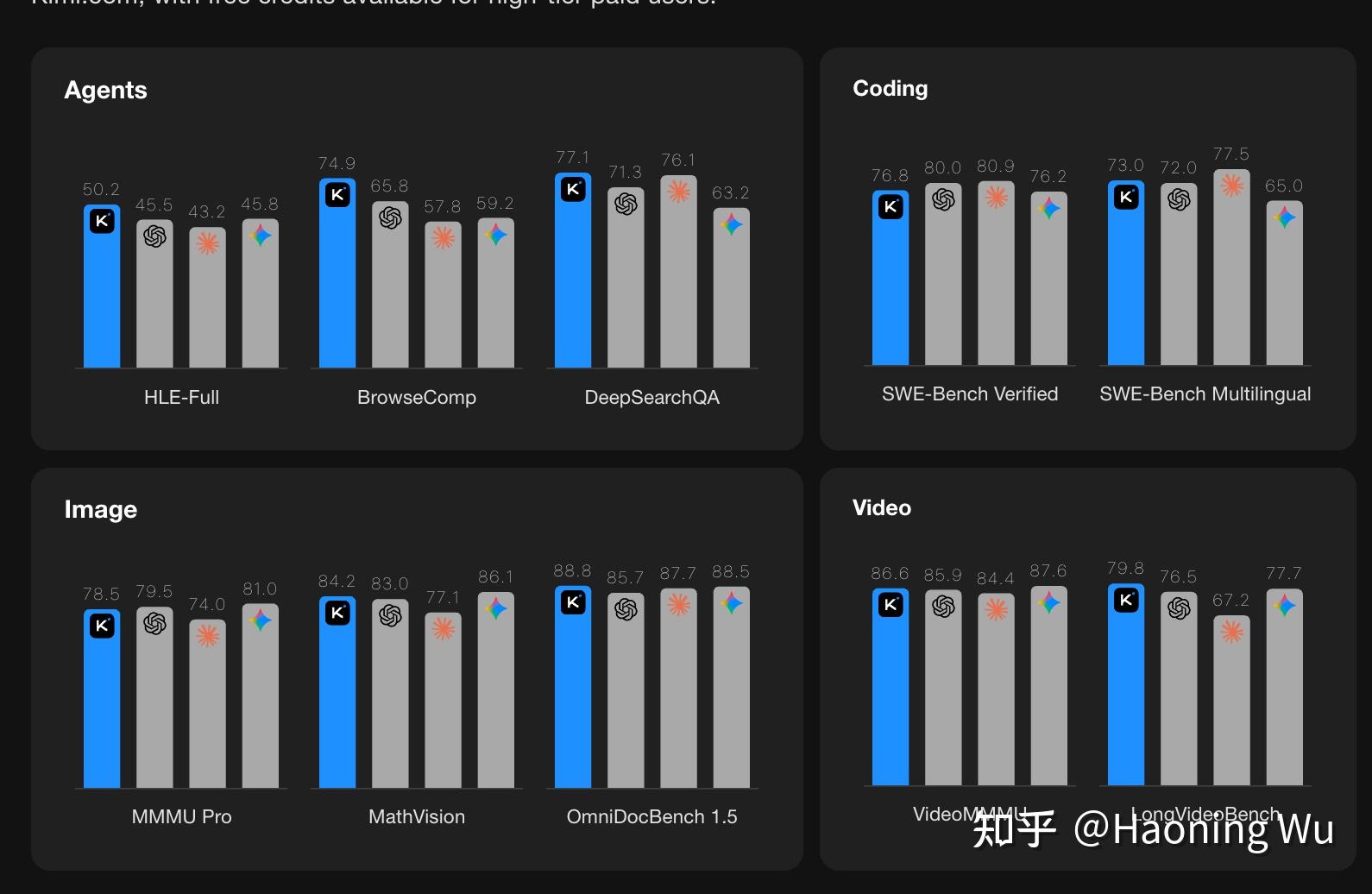
官图。
这里report的五个vision bench,三个都是没怎么观测过只有每次跑完 joint 合版才会看一下的...
按照 Kimi 内部的黑话,这应该属于是一种自信。
但 big model 就是可以这样:你可以相信只要你训练过基础能力 a,训练过基础能力 b,那么除非 overfit了,否则模型得到的一定不仅仅是 a + b,而是 a x b。
比如大家铺天盖地被震撼到的 video2code,几乎在模型用 text post-train 掌握了最通用的 agentic html 画法之后自然就会了(当然后续又经历了无数的 reject sampling 和 human-feedback 才得到最后的结果);比如看到有人说这次加上 VL 之后没有 K2 味了,但我们曾经花了大概不到 256 卡一天多的时间就训出过一个基于 k2.5-base 的 ‘cosplay-k2’。
Yes. We have more than we can make public but overall .... scaling a VLM is so fxxxking fascinating.
所以这几个月训练 1T 的模型基本上对我的认知也是一个巨大的认知冲刷。
我时常用一句话糙理不糙的方式提醒自己:
别什么事情都想着 iid 了,你以为你训 7B 呢?
来几个case呢?
Hype 结束了,来 share 一下这里我参与的一些微小的贡献,里边比较优雅的一些东西?
1.Video Understanding
既然 video2code 产生了巨大的轰动,那就讲讲video吧。
不过不讲video2code,讲最基础的、我们从这个模型的一开始,是如何训练video的。
这是 Kimi 第一次支持视频输入。整个模型是在 15T 总训练量的规模上做 pretrain,其中视频数据虽然只占 1% 左右,但我们在这些视频上花了很大心思,都是来自自然场景(natural sources)的原始视频,保留真实世界的复杂性。做了一些 recaption,但保留了巨大的自然文本比例。
架构上我们选的是 SigLIP NaViT(还是用的我在 Kimi-VL 时候 rebrand 的名字 MoonViT),但这次要做 video 了,所以设计思路是做一个真正的 unified encoder。
这个基本上是去年 2 月刚加入 Kimi 的时候就设计出来的(还能找到当时的文档,当时我还一点都不懂 RL,没想到居然有一天去参与训练 final RL...),简单来说就是又要 video encoder,又不能要 video encoder。
首先,3D 的 video encoder 肯定是必要的。因为有些 motion 和很细微的时序变化(比如快速的手势、瞬间的表情转换、),如果前面只是抽 2D 帧,后面靠 LLM 去「脑补」时序信息,到模型里其实已经看不清这些细微的动态了。一定要有原生的 3D 建模能力才能 capture 这些 motion。
但问题来了:如果 image 和 video 用两套独立的 encoder,或者为了 video 去强行改造 image 的架构,要么会伤害 image 本身的能力,要么 video 学不到真东西。更麻烦的是 embedding 会打架——比如图片里明明能认出这是「特朗普」,到了视频里,因为 visual encoder 不一样了,模型可能就「变傻」了,认不出来,或者这种 world knowledge、位置相关的能力会丢失。
所以我们坚持 image 和 video 必须共享同一个 encoder,最优雅的那种:参数完全共享。反正 NaViT 2D 也是 NaViT,3D 也是一样拍平,实现上大概基本上只改了一丢丢代码...好处就是,这样 image pretrain 学到的所有知识(物体识别、空间关系、世界知识)在 video 场景下都能完整保留,同时 video 只需要额外学习时序和动态这部分独特的能力。
在已经见证了诸多 big model smell 的今天,我 revisit 了这个差不多一年前的设计,其实几乎可以总结成 「N+1」:如果 image 能力已经是 N,那我们其实只要在 N 的基础上多训那个「+1」的(时序维度),就能得到 N+1 的效果。
后边要聊的就更有意思了。
2. Post-training 的多模态融合——同样的 N+1 思路
我们在 post-training 阶段也延续了同样的哲学:能泛化的能力一定要泛化,不要重新学。虽然过程中以我个人的有限的认知经历了很多 bitter lesson,但总之最后就收敛成了这样。
就是收敛的那一天,发出了那条 big model smell 的 X。
首先要明确一个前提:我们的 base model 首先是 vision 能力很强,然后我们也有 K2 Thinking——就是我们上一版发布的纯文本模型—— thinking 和 tooluse 能力也很强。
所以我们想,既然 K2 Thinking 已经在 text 学会了很 diverse 的思考方式和工具调用,那 vision 能不能直接继承?我们鼓捣了一通,最终收敛到的做法是:用一个极小的,没有vision输入的冷启动数据(我起了个名字 zero-vision cold-start) 去激活这种能力,让 vision 直接对齐到 text 的 thinking 和 tooluse pattern 上,把它泛化过来。
这样模型不仅能看懂图,还能保持那种灵活的 reasoning toolcall 能力。
灵活的意思是比如说,有些其他的 VLM模型可能会训练
以及这个神奇的case:

我有视觉错觉,但是我的 python code 没有。(是的 K2.5 不调用工具做不对这个题,因为我们不太想健身 overfit 这种东西,personally 感觉完全不泛化而且很外行...)
但你做 vision,肯定是不能不训;关键是第二步:
我们做了非常 holistic 的 vision-centric RL。
分涨了好多是没得说,最有意思的是我们发现连 agentic 的trajectory 都变好了;我们观察到随着 grounding training set accuracy 的提升,模型在 IPython 里天然就 crop 的越来越准,which is...
reasonable but still amazing.
于是大家看到的所有的 vision 的所有的分数基本上都是纯 RL (或者 RL RFT RL 不停 flywheel)出来的。我觉得四个月之前的自己都不敢做这样的bet,但...it really worked, and more!
2.5 最神奇的发现:Vision RL 能让模型「长知识」
这里有个特别 counter-intuitive 的发现,当时把我们自己都惊到了。
本来我们以为 vision RL 更多是教模型提取信息——就是怎么用 image 里的信息避免模型不看图瞎说。但 RL 完一测发现,woc,怎么文本知识涨了!
我们分析了半天发现,虽然有很多很多原因,但最最关键的能这样 work 的原因就在于,vision 用的是text 教出来的 thinking pattern。简单来说,没“分脑”,就”泛化“了。(内部黑话+2)
我们把这个结果同步给文本的同事的时候,他们也有点震惊;所以后来真的验证这个是可以复现的之后,不像我们在 pre-train 阶段小心翼翼,我们整个post-train vision-text joint RL 的环节通常都是一半甚至更多的 vision 数据配比。因为真的 work。
Really another glad moment for us VLM developers, huh?
于是最后还有一个重头戏。
VLM 的体感。
其实这是这两个月以来花费我最多精力的一件事...因为几个月前刚 pretrain 完的时候,它真的看起来呆呆的..
这里我给 K2.5 口述了一大堆我们怎么做的,然后让它写了两大段,但 final review 我还是全都删掉了 ... 就像发布之后 LMArena 开始盲测投票之后我只发了两句话 ”Please vote!"。
我真的很期待这个结果;因为体感不是一个开发者可以自我吹嘘的东西,需要每一个用户试着用一下。正是因为你们的体验本身不能被我 manipulate,所以它才是对我来说最 golden 的标准。
所以在这里我只剩下四个字:和它聊聊。 不管是 http://kimi.com(可以不选 agent mode 就试试 chat mode),还是 LMArena,还是甚至 HF 上的 inference endpoint,都可以试着和它聊聊。
(这已经成为我最近日常了,我甚至偶尔分享模型训练遇到瓶颈的心理状态...)
Finale: On the starting point of a new path.
说了这么多做得还不错的地方,但最后想诚实地说几句。
K2.5 肯定还有很多问题。 因为我自己也参与到训练的最后一个阶段,我太清楚它现在有哪些短板最终并没有被解决。是的,很多问题我们知道,但是我们还没有系统性解决那些、同时又让模型还保持这样聪明的办法(内心 OS:靠你们发现的好快)。
世界上不存在完美的东西。但是 K2.5 是真的是一个不一样的东西。
所以千万别觉得这就是终点了。这真的只是一个非常小的起点。
对我来说,这个「起点」的意义可能更 personal 一些。我是一个做视觉语言模型(VLM)的人,这一次我能感觉到我真的看到了我们在 Deepseek-R1 之后,终于中国的公司开始有好好训练一个不带 VL 后缀的 VLM。
我觉得它值得去掉 VL 两个字母。以后也不会再加回来了。
See you in the future.