作者:Neal
链接:https://www.zhihu.com/question/1999487395494588876/answer/2000722695596299217
利益相关,在K2.5参与了Pretrain和部分Post-train的环节。本来想默默潜水,后面发现酒香也怕巷子深(还有很多小伙伴不知道K2.5已经支持了vision general toolcall),恰逢K2.5 report ^1 发布,怒来强答一下。
什么是好的VLM Pretrain?
最早这个问题可以追溯到2年前在互金搓一个7B VLM。那时除了4o,大部分的VLM还很简单。大部分工作还在效仿LLaVA,所谓的vision pretrain就是在一个post-train好的language model上,freeze Vit和LLM,用约500k image-text pair训练中间的projector。
然后攒几个vision学术集data混起来做sft,就能得到一个还不错的VLM model。但当时直觉上就很奇怪,如果想用一个VLM用这些token和很少的trainable parameters来做pretrain,是不可能建模整个世界的。于是当时就和博哥 ^2 开始思考一个问题,什么是好的VLM Pretrain?
后面一个比较toy的想法是,我们首先要在llm pretrain阶段就加入vision data,先把flops搞上来再说。结果后续遇到了一系列模态冲突问题,探索了很久Vision- language Joint Training,最后磕磕绊绊还是攒出来一个还不错的VLM模型。
后来机缘巧合来到了Kimi,有了更多的资源,可以scale vision到更大的模型,有幸在非常懂Vision的Tim ^3 的手下,有KimiV一众实力强大的小伙伴,还能和很强的language同学能一起经常讨论,所以有机会更深入的思考Vision这个问题。此处种种先不展开,在K2.5,我们先给出了两个答案
Native Multimodal Pretrain
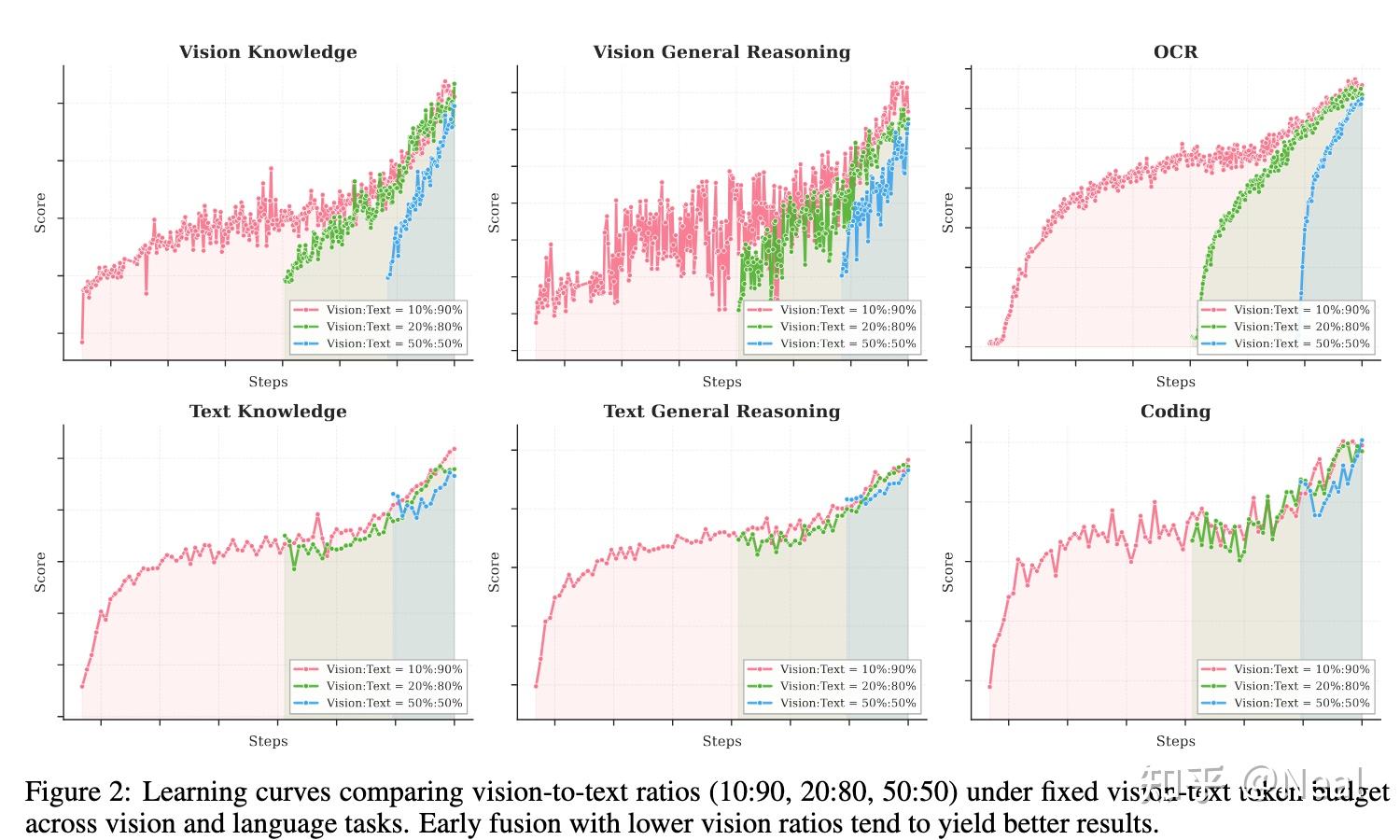
如果说在LLaVA时代,大家并没有真正意义上的vision pretrain。那么在Qwen-VL,DeepSeek-VL的时代,大家面临的问题就是,如何处理模态冲突问题。
直到今天大部分工作给出的答案依然是在language训练的末期大比例的混入vision data。我们给出的第一个答案是,要Native Multimodal Pretrain,越早越好。我们的实验发现,在固定vision-text token量的情况下:
- 1.Vision ratio 对最终的多模态性能影响没有想象那么大。在总 text-vision token 数相同的情况下,越早期融入vision(对应更低的vision ratio)反而效果更好。
- 2.同时,会观察到language curve在mid fusion和late fusion的时候perf会先下降再上升,这也是因为vision的混入剧烈改变了training data的分布,导致整体curve也不是很健康。
这直接指导了我们的训练策略:不需要激进的 vision-heavy training,而是采用适中的 vision ratio,在训练早期就 integrate。
可惜由于资源限制,我们还是需要接着Kimi K2进行continue training。尽管如此,我们还是在K2.5的训练起步阶段就进行Vision- language Joint Pretrain。
World Knowledge
我们在Pretrain过程中在思考的另一个问题是,什么才是真正适合vision pretrain的data。后面想清楚了,其实很简单,能一直scaling的data就是好data。但是举目望去,大部分vision bmk很难找出可以伴随某种token scale而perf稳步提升的bmk。
大部分VLM的bench,如MMBench,OCRBench,RealworldQA等,只需要很少的token就可以做到不错的效果。MMMU是一个很好的pretrain bench,但是MMMU和language牵连太深了,你很难从一个MMMU的perf去说到底是模型的vision knowledge变强了还是language变得更好了。
Vision缺少真正的vision pretrain task,我们认为knowledge是vision其中的一个重要pretrain方向。最终将vision knowledge定义为了K2.5核心要scale的pretrain能力。
WorldVQA ^4 的前身也应运而生,这是一个考察vision centric world knowledge的benchmark。构建一个全面的knowledge benchmark并不容易。
knowledge bmk本质上是世界的一个投影,你如何shape the world knowledge决定了你如何定义这个bmk,也决定了你如何优化你的VLM。我个人认为是目前比较好的vision benchmark,具体的细节感兴趣的同学可以参考
https://github.com/MoonshotAI/WorldVQA
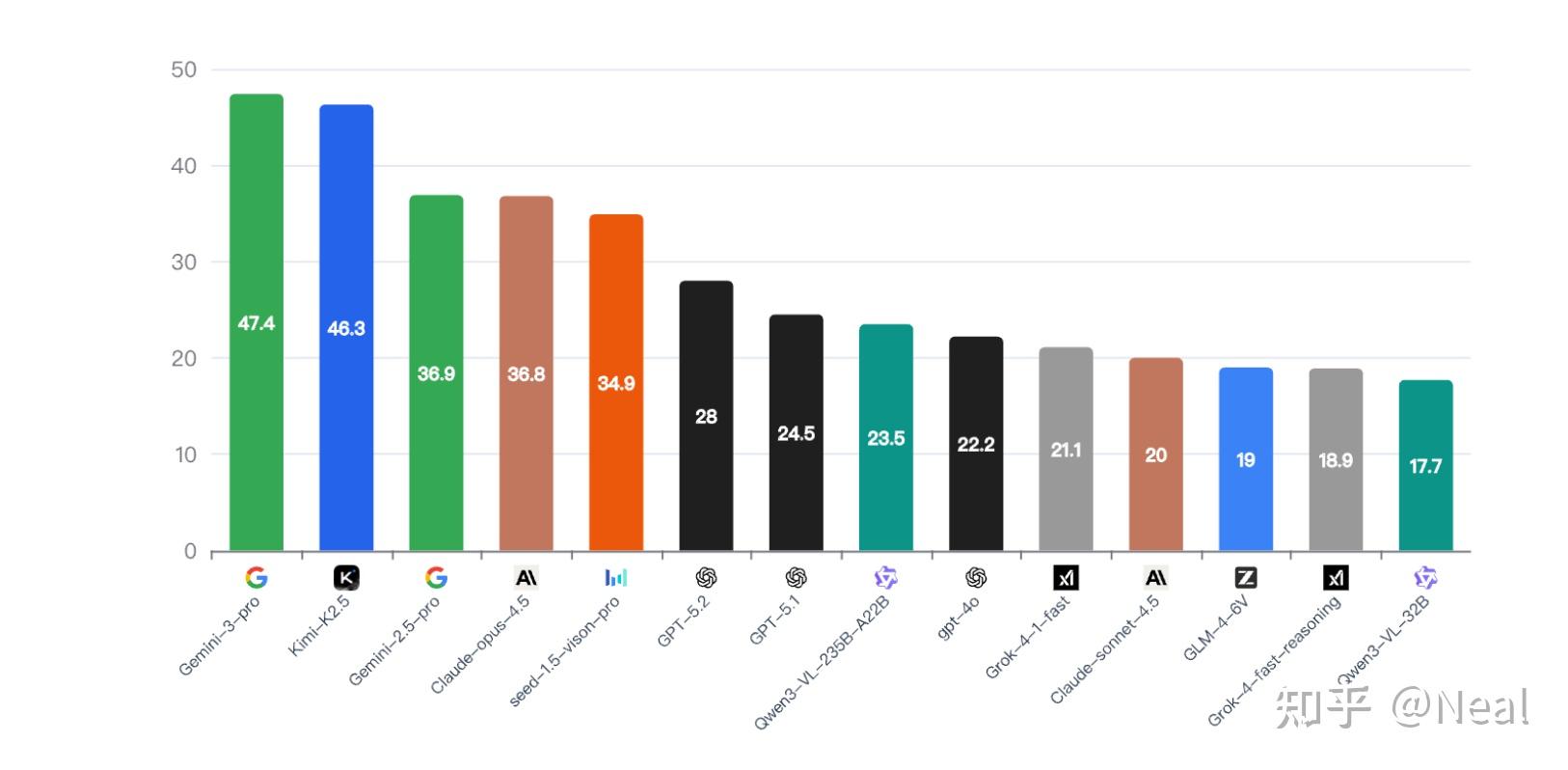
K2.5在WorldVQA上最终有非常好的分数,和Gemini-3-pro有着comparable的水平,考虑这个bench有1/3的中文语义场景,这个分我们还是占了一些便宜的。但K2.5在MMMU, SimpleVQA也有着SOTA的水平, 我们内部评测/vibe下来K2.5的World Knowledge很强,也欢迎大家多多试用。
Perception
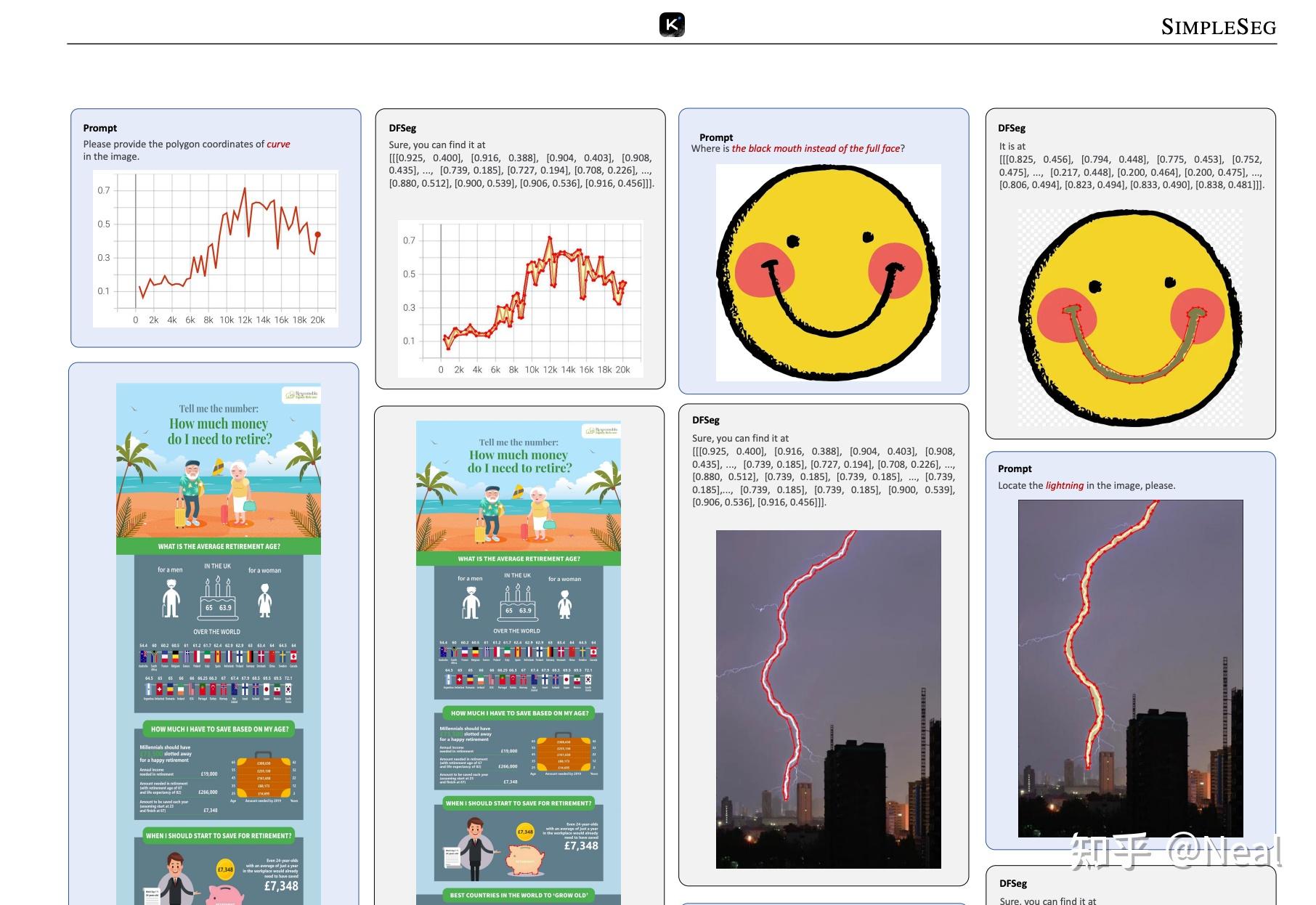
关于perception,目前我们内部还没有完美的解决方案。但内部一个有趣的工作SimpleSeg ^5
https://arxiv.org/pdf/2601.19228
我们尝试用VLM去直接predict一个物体的轮廓(contour),我们发现不引入任何的arch改进,只是单纯的predict 轮廓的坐标点,现代VLM arch 也可以直接 predict 物体的轮廓(contour),并给出 pixel-level 精度的回答。
这说明架构本身具备 pixel-level 理解能力,但由于label/training范式的种种原因,现在perception依然存在很大的问题,这需要整个社区的努力去解决,这里就不展开了。
Vision Agentic
K2.5 这次也加入了 Vision General Toolcall。最早对这个事情有兴趣是在o3发布的时候。因为之前o1爆火后,对vision思考过一个事情
我们的眼睛关注细节时
- 可能只有几个bit的锐利视觉
- 比如你看这行字时,你的眼睛看不到下面两行在说什么(不信你仔细盯一盯
但我们用非常牛逼的video视觉解决了这个问题
- 我们不断的扫描
- 用我们attention范围内的小区域,不断的扫描任何图
所以感觉vision的一个问题不是模型眼神不够好,而是缺失一种vision test-time scaling的方式。所以o3发布的时候产生了非常大的兴趣。开始拉泽哥zijia隋总和几个intern同学一起来做这个事。
在探索中我们一开始也磕磕绊绊遇到一些情况。一开始我们为了bootstrap和搭建相关基建,采用了传统做法,即为视觉 agent 设计 specialized tooling(crop、rotate、zoom)做 SFT,然后在小模型上迭代。
后来pipeline跑起来后很快也慢慢在部分bmk有所体现。但很快发现模型最终也只会这几个toolcall,不具备任何泛化能力。
同时模型一进入到这几种toolcall的模式后,就表现的特别傻(我们内部称之为分脑行为,即一个pattern过于强化导致模型完全overfit到了这个pattern上)。
同期国内也有很多工作陆陆续续推出了vision toolcall,但我们内部仍然觉得这个事情有点跑偏了,距离oai非常smart调用很diverse的工具还有着非常大的距离。
事情的转机来自一次机缘巧合,那时K2.5 midtrain刚结束,我们可以在一个1T的模型上迭代。
但其他方向压力很大,vision toolcall又是一个偏research的project所以资源不是很大。我们趁着一个下午在一个有空卡跑了几十步,然后模型就被kill了。
模型只见了3000个vision toolcall样本,但在vision+code上有着惊人的泛化体验。一开始我们认为这是模型大了变强的结果,但是后续有资源继续迭代,发现跑久了反而模型又开始变傻了。后面干脆一点vision toolcall数据都不训,发现模型又可以泛化了。
那个时候我们有点震惊又有些难受,震惊的点来自于我们发现纯靠joint pretrain模型就有着惊人的泛化,难受的点在于我们之前试图定义的操作反而一直在bind模型的上限。那段时间我们戏称,thinking with image这个topic最重要的第一步就是remove vision。同期做post-train的haoning在thinking上也有着相似的发现。
所以最后vision的冷启动就全变成zero vision了。目前我们还在探索的初期,有很多已知问题,但很多场景上K2.5已经有着非常smart的表现了,以下是一些摘自K2.5 report的例子(下面这个很屌的24小时视频编辑例子来自泽哥和隋总),也欢迎大家多多试用。


写在最后
本文只介绍了笔者参与的部分工作,工作由vision和language团队同学齐心一起解决。多模态尚有很多问题亟待解决,欢迎对多模态感兴趣的小伙伴加入Kimi一起登月~
1. 博哥,现浙大AP,人很强很nice,欢迎报考https://scholar.google.com/citations?user=PefHCMUAAAAJ&hl=en
2. Tim,Kimi点子王https://scholar.google.com/citations?user=Jv4LCj8AAAAJ&hl=en
3. WorldVQA, https://github.com/MoonshotAI/WorldVQA/blob/master/paper/worldvqa.pdf
4. SimpleSeg, https://arxiv.org/pdf/2601.19228
5. Kimi K2.5, https://github.com/MoonshotAI/Kimi-K2.5/blob/master/tech_report.pdf