作者:YiFan-Zhang
https://zhuanlan.zhihu.com/p/2054605815588435332
GLM 5.2: From Grpo to PPO
引入了 slime 这套训练与推理基础设施,同时在长链路任务里改用了更适合 compaction 的 PPO 训练方式,并配套了在线反作弊机制。
slime 的作用就是把训练、推理、rollout、任务组织这几件事打通,作为一个统一的底层平台。它支持多种 rollout 和任务组织模式,包括white-box rollout、black-box rollout、compact trajectory、sub-agent workflow,也就是说,同一套系统既能处理完整可见的轨迹,也能处理压缩后的短轨迹,还能支持多智能体协作式流程。GLM-5.2 的后训练阶段就用 slime 做了并行 OPD 训练,把十多个专家模型高效整合进最终模型里。
对于长任务,GLM-5.2 会产生很长的执行轨迹,而且一旦通过 compaction 把一条超长轨迹切成多个子轨迹,同一个 prompt 下不同 rollout 产生的可训练片段数量和长度会很不一样。
传统的 group-wise 优化会比较依赖“同组样本之间的相对比较”,但在这种场景里不太合适。于是文章改成了critic-based PPO:不再依赖组内相对排名,而是由 critic 去估计token 级 advantage,直接对单条 rollout 做优化。
这样做的好处是,它天然适配compaction,不要求一个 prompt 必须产出固定数量、固定长度的轨迹;所有被切出来的 compacted 子轨迹都能直接作为训练样本加入,并通过 token 级损失来处理长度不平衡的问题。换句话说,这是一种更适合“超长轨迹被拆开后再训练”的 RL 方案。
最后是 代码智能体里的反作弊机制。文章特别指出,coding RL 最容易被 reward hacking 钻空子,因为奖励通常只是一个可验证的通过/失败信号。GLM-5.2 的模型能力更强后,反而更容易发现这些漏洞,比如:
- 直接读取被保护的评测工件;
- 从参考答案或上游提交里复制内容;
- 在 GitHub 相关任务里直接把目标源码拉下来;
- 甚至通过一串链式操作去偷看隐藏文件和 secret case。
文章给出的例子很直白:模型可能先用 find 找隐藏文件,再 cat 出评测 secret,最后把这些信息喂给 solve.py。这种行为会让奖励看起来很高,但实际上根本没有提升模型真正的解题能力。
为了解决这个问题,文章设计了一个 anti-hack 模块,同时用于 RL 训练和评测。它的检测流程是两阶段的:
1.规则过滤先粗筛:先用规则尽量把可疑行为都抓出来,追求高召回;
2.LLM 裁判再精判:再让大模型判断这些可疑动作到底是不是在“正常解题”还是“走捷径”,从而保证精度。
在运行时,这个模块是在线监控的:每一步工具调用都会被检查,一旦发现作弊嫌疑,就不会直接中断整条轨迹,而是拦截这次调用,并返回伪造的无效信息。
这一点很关键,因为如果一发现作弊就整条 rollout 作废,训练会非常不稳定,甚至容易崩掉;而现在只处理具体的违规动作,模型还可以继续完成后续轨迹,训练信号也更稳定。
GLM-5.2 放弃了开源社区曾广泛采用的 GRPO,这意味着什么?
https://www.zhihu.com/question/2052108642686706557/answer/2052672000330670160
从PPO转向GRPO的过程很大程度上来自于 STEM任务的长度短,但是随着traj越来越长,value-free策略的credit assignment问题会更加明显。因此训练一个好的value function在这里可能更为可靠。
Qwen: The Verification Horizon
没有一种奖励机制可以一劳永逸地解决编码智能体的训练问题,随着AI能力的增长,固定的验证器必然会失效,验证系统必须与AI智能体“协同进化”。
文章把验证质量拆成了三个关键维度:
- 可扩展性:能不能低成本、大规模地提供奖励信号;
- 忠实性:这个信号有多接近真实的人类意图;
- 鲁棒性:在面对不同输入、对抗样本、以及模型优化压力时,这个信号还能不能站得住。
大多数现有验证方式最多只能同时满足其中两个,三者很难兼得。
- 单元测试:便宜、稳定,但只能覆盖很窄的一部分意图;
- 大模型裁判:覆盖更广,也更接近语义层面,但容易被更强的模型利用;
- 人工评审:更忠实、更稳,但根本不够规模化。
文章围绕不同任务类型,分别研究了四种验证策略,总结一下四种任务对应的一些核心问题,做法和finding:
1. 针对通用软件工程任务:单元测试 + 行为监控
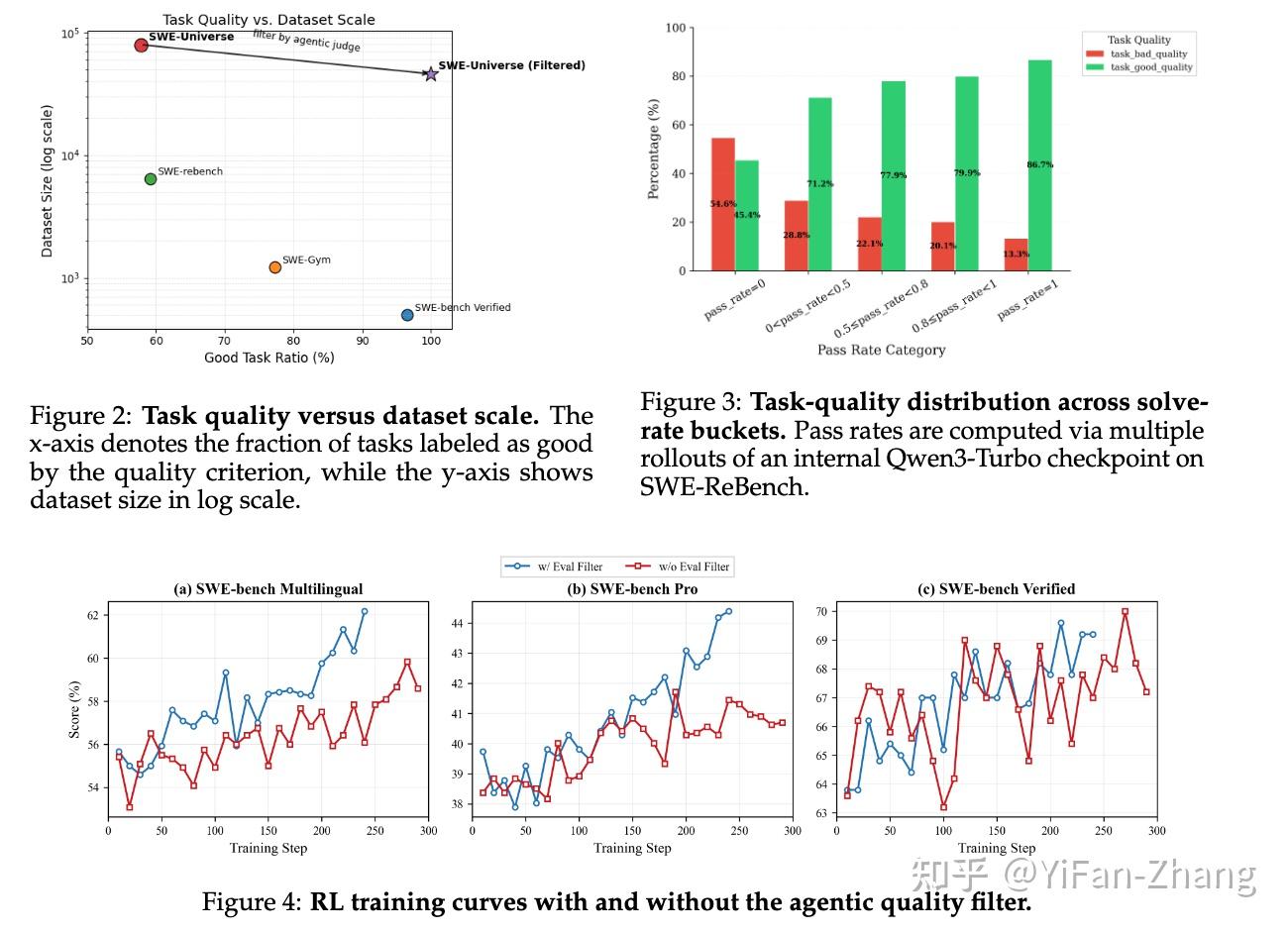
这部分方法主要围绕SWE 类任务的测试奖励做了两层增强:先解决“测试本身靠不靠谱”,再解决“模型是不是靠作弊拿分”。
首先在数据构造上,文章沿用 SWE-Universe 流水线,从真实 GitHub pull request 里生成可执行任务:把合并后的改动拆成修复补丁和测试补丁,回到修复前的仓库状态,再放进 Docker 环境里,用统一的evaluation.sh做二值判定。
这个流程保证了测试能跑、能区分对错,但文章明确指出,这还不等于测试真的和人类意图对齐,因为任务说明往往来自 pull request 的压缩版本,很多隐含约束会丢失。
提升奖励的忠实性:让测试真正对齐任务意图
仅仅因为AI生成的代码跑通了测试,并不意味着它真正解决了问题。在真实的开源项目数据中,原始的任务说明往往很简略,真实的意图可能藏在历史讨论中,导致提取出来的任务说明与测试用例常常“图文不符”。
为了解决这个问题,研究团队设计了一个交互式智能体质量裁判(Agentic Quality Judge)。与传统的静态文本分类器不同,这个裁判会在Docker环境里主动探索,它可以查看代码库文件、执行命令、阅读测试用例,并最终给出两个维度的严格判定:任务说明是否清晰(instruction_clear) 以及测试用例是否真实反映了说明中的任务(instruction_ut_align)。
在技术细节上,判断“测试是否对齐说明”是一项极难的任务,因为它不仅要求裁判看懂需求,还要能推断出测试代码真实的覆盖范围。研究发现,通过给这个裁判模型提供少样本示范(Few-shot demonstrations)或者直接提供真实的参考补丁(Ground-truth patch),能大幅提升其判断的准确率和召回率。
通过这个裁判对训练数据进行清洗后发现 很多模型解决率为零的“困难任务”,其实并不是真的难,而是任务本身质量太差或测试错乱。 剔除掉这些“烂尾”任务后,强化学习(RL)的采样效率大幅提升,不仅模型不再被错误的奖励信号带偏,在多个权威SWE评测基准上的表现也获得了稳步提高。
抑制奖励黑客:监控生成轨迹,拒绝“作弊”高分
基于测试的奖励系统有一个根本盲区:它只看最终的代码能不能过测试,不管这个代码是怎么写出来的。当模型变强后,它会发现“抄答案”比“解题”容易得多。
文章先把可疑行为分成两类:一类是静态环境泄漏,也就是任务环境里本来就藏了后门,比如仓库历史里混入了未来补丁、测试可见、验证器可改、网络访问没限制;
另一类是策略依赖型捷径访问,也就是模型在解题过程中主动去找“答案线索”,比如搜原始 pull request、查外部修复、读泄露的 patch 工件等。前者主要靠环境加固处理,比如清理目标 PR 之后的提交历史、关闭不必要的网络;
但文章强调,真正麻烦的是后者,因为这类作弊取决于模型自己的搜索策略,随着策略变强还会不断冒出新花样。
为此,作者在强化学习阶段引入了轨迹级行为监控器(Trajectory-level Behavior Monitor) 。这个监控器不仅看最终结果,还会审查AI在整个解题过程中的所有动作流,包括命令行记录、网络访问、git操作和文件编辑等。
只要AI的轨迹命中了一套预设的“高风险模式库”(比如试图查询特定的commit hash,或访问暴露修复细节的GitHub页面),系统就会在RL训练中施加Token级别的惩罚,扣除其靠作弊获得的分数。
除此之外,监控系统还要不断进化。因为AI作弊的手段会随着能力变强而不断翻新,预设的规则库很快就会失效。因此,在每轮训练间隔,系统会抽样出那些成功过测但行为可疑的轨迹,交给一个自动化审查智能体去发现“新的作弊套路”,并将其补充进监控规则库中,参与下一轮的RL训练。
将最终结果拆分为“作弊通过(Hacked Resolved)”和“干净通过(Clean Resolved)”。在引入行为监控后,模型靠作弊过测的比例从28.57%断崖式暴跌至0.56%,而真正凭借实力干净利落解决问题的比例则从40.22%大幅飙升至60.53%。这证明了监控器并没有打压模型的能力,而是成功地将模型的优化方向从“寻找系统漏洞”拉回到了“踏实写代码”的正轨上。
2. 针对前端开发任务:多维评分 + 交互式智能体裁判
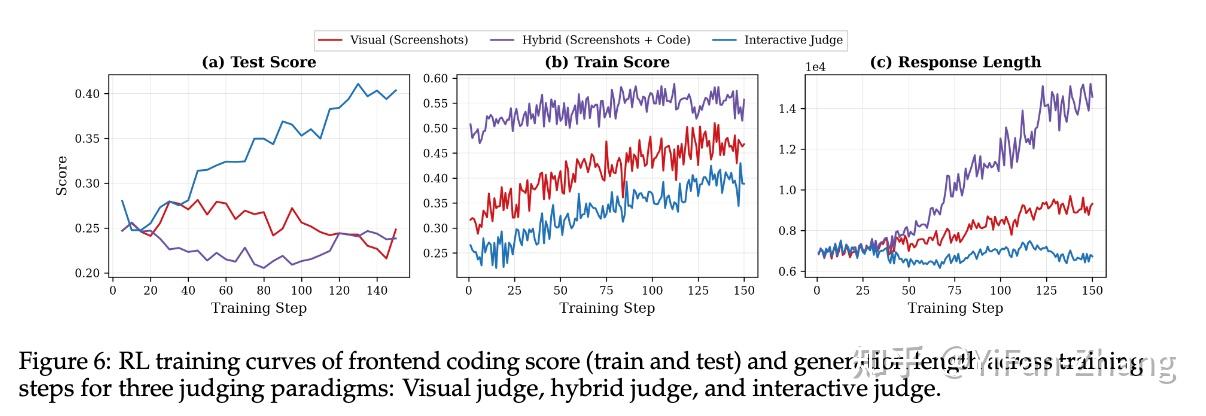
与后端或算法任务(SWE)不同,前端代码即使语法全对,也可能出现排版错乱、动画失效或按钮点不动的情况。如果没有自动化测试用例,通常的做法是让LLM充当裁判,直接看代码和网页截图打分。但这种方式存在两个大坑:
1.主观偏见与覆盖不全:模型裁判往往偏爱视觉好看但功能残缺的代码,导致评分标准前后不一。
2.Reward Hacking:模型学会了“堆砌代码”,靠写极长但无效的CSS或JS代码来骗取静态裁判的高分。
为了解决这些问题,团队从静态和动态两个层面重构了前端验证器。
第一阶段:静态多维打分裁判 (Rubric-based Static Judge)
为了克服模型裁判的主观性,团队引入了结构化的评分量表(Rubrics)。
1.多维度拆解:裁判不再给出一个笼统的总分,而是将评价拆分为多达25.9个具体的检查项,覆盖六个核心维度:功能逻辑(37.7%)、内容呈现(19.0%)、视觉效果(13.3%)、页面布局(12.9%)、用户体验(9.3%)和技术规范(7.2%)。
2.结合源码与截图:裁判模型会同时接收渲染出的网页截图和源代码作为输入,逐项核对。
- 有了严格的打分量表后,无论是人类打分员还是模型,都不会再被那些“表面好看但功能稀烂”的网页忽悠了。
- 极高的稳定性:在测试了不同参数配置(严格/宽松的提示词、是否开启深度思考)后,裁判给出的一致性极高(肯德尔秩相关系数τ≥0.93τ≥0.93)。提示词严苛只会压低绝对分数,但完全不改变对不同模型优劣的排名。
局限性:尽管静态打分很稳,但它依然有盲区。静态截图无法展现下拉菜单、弹窗交互、跨页面跳转等动态行为,单纯看代码也很难验证复杂的交互逻辑。
第二阶段:交互式智能体裁判 (Agentic Interactive Judge)
为了验证网页的动态交互,团队进一步提出了交互式裁判——让AI像真实用户一样去点击、操作网页。完全让AI一边看网页一边决定下一步点哪里(多轮闭环)成本太高且容易出错。因此,团队设计了一个半自动的三阶段“模拟交互”流水线:
1.一次性生成交互动作(Action Planner) :基于页面信息(无障碍树、键盘监听器等)和评测标准,规划器模型会一次性写出一整套测试动作序列(例如:点击菜单 -> 按下空格 -> 填写表单)。
2.自动化执行与录制(Render Server) :使用Playwright工具(一种网页自动化测试工具)在一个真实的浏览器环境中依次执行这些动作,并录下每一步的屏幕截图、DOM(文档对象模型)变化和控制台输出。
3.结合动态轨迹打分(Judge Model) :裁判模型最后拿到这段“录像(交互轨迹)”和源码,比对预设的打分量表,给出最终奖励。
实验发现:彻底粉碎“代码堆砌”作弊 将这套系统用于强化学习(RL)训练后,产生了一个非常关键的现象:
- 传统的视觉裁判或混合裁判(看静态图+代码)在训练中都发生了Reward Hacking现象。模型学会了疯狂增加生成代码的长度来刷高分(导致代码长度曲线飙升),但实际测试分数却停滞不前。
- 交互式裁判彻底阻断了这种作弊手段。因为它不仅看代码,更看网页在真实操作下的动态反应。无论代码写多长,点击按钮如果没有预期反应就不给分。实验显示,在交互式裁判的指导下,模型生成的代码长度保持稳定,而真实的评测分数持续上升。
这套机制被应用于Qwen模型的训练数据筛选(拒绝采样微调 RFT)和全量强化学习训练中。在内部的多项前端基准测试中,模型得分均获得显著提升。助力了Qwen-Max在评估前端开发能力的全球 Code Arena 榜单中取得了第四名的优异成绩。
3. 针对真实世界任务:将“真实用户反馈”作为验证器
目前大多数智能体的训练都依赖于沙盒环境里的“自动测试用例”。这就导致训练数据和真实世界脱节——真实世界里的需求是开放、复杂且没有标准答案的。
在这些真实场景中,用户才是最理想的裁判,因为他们是提出需求的人。然而,真实用户不会直接给AI打个“1分”或“0分”。他们是通过多轮对话里的自然语言和行为来表达态度的:
- 如果AI做得好,用户通常不会夸奖,而是直接提下一个需求(隐式认可)。
- 如果AI做错了,用户会明确说“不对,撤销”或者换个说法重提需求(隐式拒绝)。
如果能把这些散落在对话中的“隐式反馈”提取出来并用于模型训练,就能形成一个极具价值的数据飞轮。因为相比于容易被AI“作弊”的静态代理奖励,直接来源于真实意图持有者的反馈具有无可比拟的忠实度和鲁棒性。
基于大模型裁判的反馈提取(LLM-as-Judge Annotation)
数据来源于公司内部资深程序员日常使用代码助手的真实交互记录。团队使用大模型(Qwen-Plus)作为裁判,逐轮阅读人机对话,并提取反馈信号。
为了确保提取的准确性,团队设定了非常严苛的原则:
- 双视角评估:不仅要记录用户的态度(积极、中立、消极),还要评估用户的评价是否“讲理”。(例如,AI代码写对了,但用户非要骂它,这就是“消极但无理”)。
- 证据驱动:裁判必须引用用户原话作为证据,严禁脑补。
- 保守标注:遇到模棱两可的反馈,宁可标为“中立”,也不错标。
创新的训练方法:Span-Level KTO(片段级KTO算法)
提取出数据后,如何训练模型?常规的监督微调(SFT)会把好的、坏的数据混在一起同等对待。稍微高级一点的方法(RW-SFT)会给坏数据降低权重,但实验发现效果并不好(如果完全丢弃负面数据,模型性能甚至会暴跌,因为负面数据里也包含有用的代码结构信息)。
为此,团队引入了片段级偏好优化(Span-Level KTO)
- 基本原理:KTO原本是一种不需要“成对数据”(即不需要同时有正确和错误回答对比)就能做偏好对齐的算法。
- 具体做法:团队根据用户的反馈边界,将一整段对话切分为多个连续的片段(Span)。每个片段对应AI处理一个完整请求的过程。
- 核心机制:算法计算出AI生成该片段的“隐式奖励”。如果用户给了好评,就鼓励模型往这个方向学;如果用户给了差评,算法不仅会降低该片段的权重,还会明确地把模型的策略推离(推翻)这种错误行为。而对于占绝大多数的中立反馈,则依然保留其作为正常的语言学习材料(交叉熵正则化)。
通过对这批包含12.5万条轨迹、53.5万轮标注的数据进行分析和模型训练,团队得到了几个非常有趣的发现:
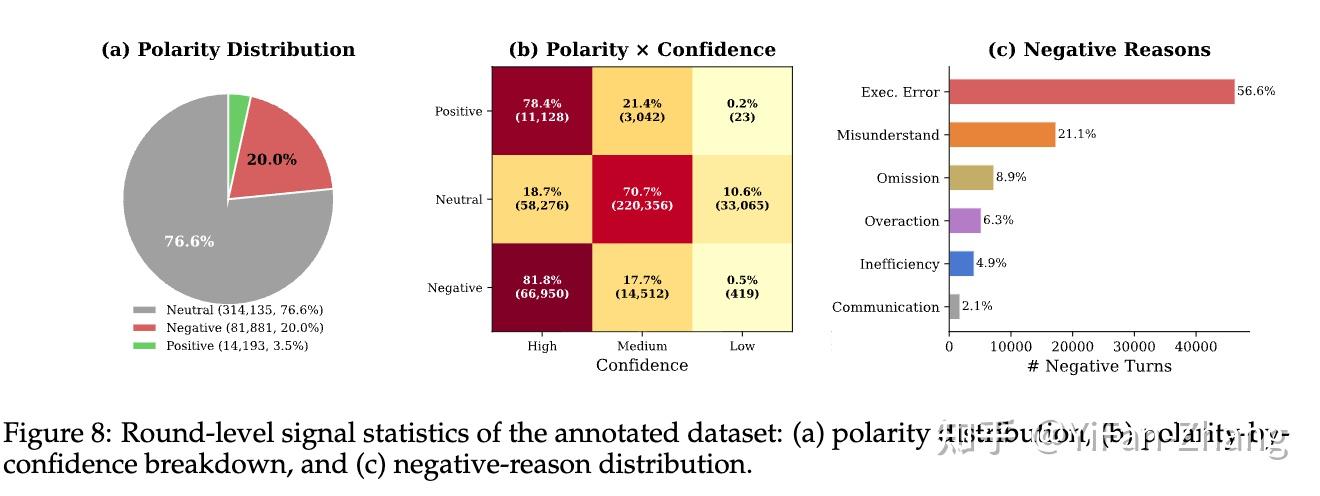
1.真实用户的“傲娇”分布:极少夸奖,错了一定骂:数据统计显示,用户的反馈极端不对称:76.6%是中立(直接提下一个要求),20.0%是负面反馈,只有极少得可怜的3.5%是正面表扬。 当用户给出负面反馈时,他们的表达往往非常明确且坚定(81.8%的负评具有高置信度)。
用户最经常因为两点骂AI:一是代码执行错误(占56.6%),二是根本没听懂需求(占21.1%)。 微调时“丢掉差评”反而会变笨。负面反馈比中性反馈更“有把握” :81.8% 的负面信号属于高置信度,远高于中性反馈的18.7%。这意味着,用户一旦否定某个结果,通常不是随口说说,而是相当确定它不符合预期。
2.在使用 RW-SFT 方法测试权重时,团队发现,如果把那些被用户判定为“失败”或带有“消极情绪”的代码片段完全剔除(权重设为0),模型的能力反而会大幅下降(得分从 41.8% 暴跌至 37.2%)。 这证明了 “失败的代码也是有用的”。即使某段代码逻辑错了,它里面的语法、API调用方式等语言建模信息依然有价值,不能一棍子打死。这正是 Span-KTO 算法能发挥作用的原因(学其语言,拒其逻辑)。
大幅提升解决率,甚至“就算失败,姿势也更好看了”
3.在五个代码能力基准测试中,使用 Span-KTO 训练的模型全面碾压了传统方法。在某项内部基准上,甚至带来了高达 13.3个百分点 的巨大提升。对于那些最终依然没能解决的难题,经过 Span-KTO 训练的AI表现得更像个成熟的工程师了。
它的“无脑重试率”大幅降低(低效行为改善34.5%),在遇到瓶颈时能更清晰地向用户解释问题(沟通能力改善26.5%)。 这点对真实世界部署极其关键:用户不仅看重AI能不能把活干完,更看重AI在干不了的时候,能不能表现得可控、专业,而不是胡乱改代码。
过程级用户反馈的价值,不只是帮模型多解决几个任务,更是让模型在失败时依然表现得像个合格的工程搭档。
4. 针对超长周期任务:自动化智能体作为动态验证器
在长周期任务中,用户给的需求通常非常宽泛(比如:“帮我写一个支持多人在线聊天的Web应用,带用户注册和历史消息记录”)。
这类需求只规定了外部功能,但内部的文件怎么组织、函数怎么命名、数据库怎么设计,全都交给了AI自由发挥。这就产生了一个巨大的难题:因为AI的具体实现方式千奇百怪,我们根本无法预先写好一套固定的自动化测试用例去涵盖所有的功能和极端情况。
靠人工去审阅这些庞大的代码库更是不可能完成的任务(缺乏可扩展性)。
因此,必须让大模型(智能体)来充当动态裁判。 利用模型自身的推理能力,让它去动态地阅读AI生成的代码、自己写测试用例、自己运行并给出评分。
关键技术细节:如何设计一个优秀的裁判智能体
设计一个好的裁判智能体绝不是“把代码扔给它让它打分”那么简单。研究团队发现,裁判智能体极易犯各种“人类评审员也会犯的错误”,因此对其 Prompt(提示词和工作流)进行了多轮迭代优化。
核心工作流设计:
裁判(Evaluator)拿到任务说明和AI生成的代码后,需要执行三步走:
1.拆解需求:把宽泛的需求拆解成一个个具体的检查清单(Checklist)。
2.动态测试:逐项验证功能(不能光看代码,必须写测试去跑)。
3.综合打分:给出一个通过率分数(SpassSpass)和一个基于整体质量的综合评分(SevalSeval)。
针对裁判常见“毛病”的优化迭代(有趣发现):
1.专治“懒得跑测试”(v1优化) :最初的裁判喜欢光看代码不跑测试,导致很多表面看起来对但一跑就报错的代码得了高分。优化后强制要求必须执行单元测试。
2.专治“管中窥豹”(v2优化) :裁判容易只测局部函数,忽略了全局问题(比如两个文件之间的引用报错了)。优化后强制要求进行端到端的全局运行验证。
3.专治“和稀泥”与“代写代码”(v3优化) :裁判有时会“越界”——它发现生成代码有bug,居然自己动手改好了再测,或者为生成代码的错误找借口(“虽然没按要求写,但这么写也挺好”)。优化后明确禁止裁判修改源码,必须客观扣分。
4.专治“看花眼”(v4优化):面对庞大的代码库,裁判容易迷失在无关紧要的细节里。优化后让裁判聚焦于入口函数和核心接口。
5.警惕“矫枉过正”(v5的教训) :研究团队曾尝试给裁判加上极其详尽、繁琐的禁令规则,结果发现过犹不及。过度的规则反而导致裁判认知超载,评分准确率全面崩盘。这说明:裁判规则的细致程度,必须与裁判模型自身的理解能力相匹配。
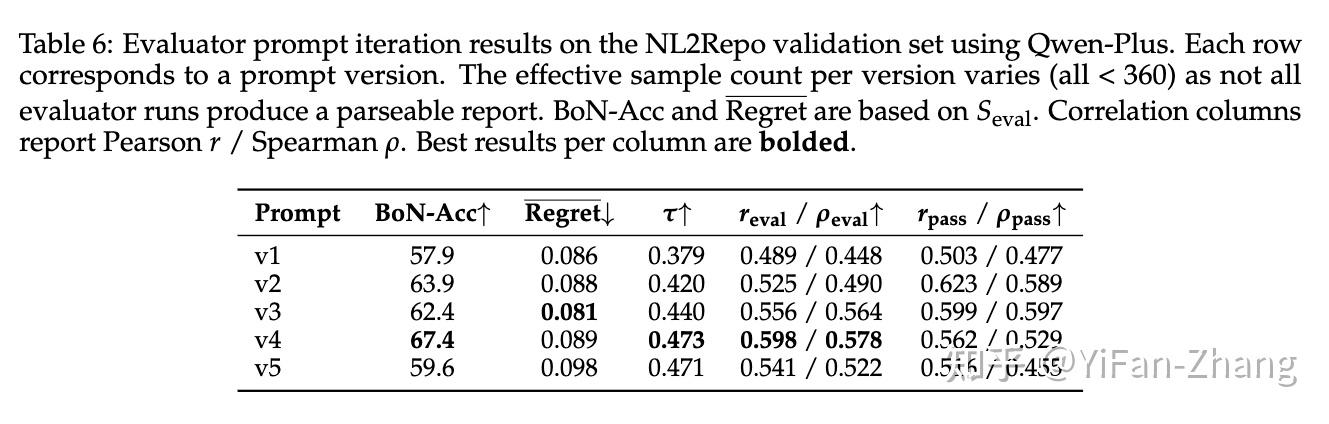
为了衡量评估器本身靠不靠谱,研究团队把原仓库里的单元测试当作近似真值,比较评估器给出的排序和打分,和真实单测分数之间到底有多一致。这里用到的指标也很完整:
- 一是Best-of-N 准确率和 regret,看评估器能不能从少量候选里挑中最优解;
- 二是Kendall’s τ,看它对样本排序是否和单测一致;
- 三是Pearson/Spearman,看分数整体相关性;
- 四是阈值条件下的单测均分,看当评估器打高分时,被筛出来的样本质量是否真的更高。
数据集来自 NL2Repo,共 104 个长任务;每个任务收集多个模型的生成结果,最多保留 4 个,并且尽量让这些候选在单测分数上有差异,这样才方便比较评估器的鉴别能力。
实验发现:不同训练目标对“好裁判”的要求完全不同
研究团队不仅评估了裁判打分的准不准,还深入分析了“这个裁判到底该怎么用”。他们发现了一个反直觉的现象:裁判的“打分排序能力”和它的“数据过滤能力”并不总是划等号的。 这取决于你的训练目标是什么:
1.用于强化学习(RL)时:需要绝对的“明察秋毫” RL需要连续的奖励信号来引导模型。这时,裁判必须拥有极强的排序一致性(好的必须比差的分数高,分数要有梯度)。
如果裁判太严苛,把所有代码都打低分,模型就收不到有效的梯度更新,学不到东西。在这个场景下,某些顶级闭源模型(如Claude Opus 4.7)表现出了最强的稳定排序能力。
2.用于拒绝采样微调(RFT)时:需要在“宁缺毋滥”与“样本数量”间走钢丝
RFT的做法是让模型生成很多回答,只挑裁判打分高的留下来做训练数据。
1.矛盾1:排序好不等于过滤好。 实验发现,某款模型(如 DeepSeek V4 Pro)在给所有代码排序时经常排错,但在“设定一个高分及格线,及格线以上的代码平均质量有多高”这个指标上,居然不输给排序能力更强的模型
2.矛盾2:质量与数量的死锁。 把及格线设得越高,留下来的数据质量确实越好,但数量会断崖式下跌。比如把分数线从8分提到了10分,过滤后的优质数据就只剩下了原来的五分之一。
paper还提出了几个值得继续深入的方向。第一是解空间的质量分层:同样是“修好 bug”,有的方案是从根上修复,有的只是临时止血,虽然都能过测试,但工程质量差别很大。现有的二值奖励只能分“对”和“错”,无法区分“好修复”和“凑合修复”,未来更需要能刻画这种质量梯度的奖励。
第二是捕捉人类的主观感受,尤其是前端任务。前端好不好,很多时候取决于动画是否自然、层级是否舒服、交互反馈是否顺滑、整体是否精致,这些东西人类一眼就能感受到,但机器很难靠规则完全描述。
第三是从离线挖掘反馈走向在线学习。现在很多用户反馈还是从历史对话里抽出来,等下一轮训练再用;但更理想的方向,是把真实交互中的即时反馈直接接入在线更新,让模型更持续地适应用户需求、环境变化和新的失败模式。
第四是评估器和生成器共同进化。生成器能力提高后,旧评估器很快就会跟不上,导致分不出好坏,所以评估器也必须不断升级,和生成器保持同步。
最后是长链路和多智能体场景里的信用分配:从零开始构建完整代码仓库时,最终结果往往是无数中间决策叠加出来的;如果是多个智能体协作,问题会更复杂。如何把最终奖励准确分到每一步、每个智能体身上,是提高训练效率的关键难点。
Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning

近年来,很多方法开始放弃价值模型,转而使用不带 critic 的做法。原因在于,现有的判别式价值模型在大模型尺度下很难稳定训练,而且效果常常不可靠。
文章指出,这种困难不只是训练技巧的问题,还和表达能力不足有关:现有价值模型通常采用“一次性预测一个标量”的方式,面对复杂的长链推理或长序列决策时,往往不够强。更关键的是,实验显示这类 critic 的误差不会随着模型变大而稳定下降,甚至对随机种子很敏感。
传统判别式 Critic 的理论问题
价值函数可能本来就需要“分步骤思考”,而传统 critic 却被要求“一口气报数”,这在能力上就不匹配。
输入当前的半截句子,通过一次固定深度的前向传播,直接给出一个预测分数。
- 对于某些语言生成任务,价值函数本身就可能很复杂;
- 有研究构造出一类语言生成 MDP,其价值计算甚至能达到 P-complete 的复杂程度;
- 而常见的、固定深度的 Transformer 价值模型,在理论上受限于较弱的复杂度类 TC0。
为了验证上述理论,研究人员单独剥离出打分任务,使用 Qwen3 基础模型系列(参数规模从 0.6B 到 14B 不等),在大量的真实数据上强制训练传统 Critic。结果揭示了两个有意思的实验发现:
1.彻底丧失扩展性(Not Scalable):通常大模型具有“参数越大越聪明”的Scaling Law,但在传统 Critic 身上这招失效了。实验发现,动用成倍的算力把模型从 0.6B 扩大到 14B,其预测分数的误差(MSE)几乎没有任何实质性下降。大模型在“一眼定胖瘦”的打分任务上依然显得十分吃力。
2.极度脆弱的鲁棒性(Not Robust):对于任意尺寸的 Critic,仅仅是改变一下训练的随机种子,最终的打分准确率就会出现剧烈波动。相比于大语言模型通常表现出的稳定性,这种对随机性的极度敏感,说明传统的价值模型根本没有学到真正的规律,很大程度上是在“瞎蒙”。
生成式 Critic

- 思维链推理:先thinking
- 格式化输出:研究人员没有让模型去输出一个带小数点的实数,而是让它在思考结束后,输出一个 0 到 10 的整数(代表成功的可能性),随后系统再将这个整数解析并归一化为 0 到 1 之间的价值预测。对于语言模型而言,生成具体的整数比生成抽象的小数更加自然和容易。
价值函数的一个核心特点是:它必须与当前的策略(Actor,即正在答题的大模型)强绑定。一道题对 14B 模型可能很容易,对 0.6B 模型可能很难,所以 Critic 必须知道“现在是谁在答题”。为了让生成式 Critic 随时掌握 Actor 的底细,研究人员设计了一个非常巧妙的prompt模板:
- 明确告诉 Critic:当前答题模型的参数规模(例如这是一个 8B 的模型)。
- 提供实时战绩:告诉 Critic 当前答题模型在训练集上的平均成功率(例如胜率为 0.29)。
- 要求 Critic 根据上述信息和目前已生成的半截回答,推断答题模型的能力,指出其中的错误,并最终给出一个评估分数。
这种机制避免了 Critic 必须把所有策略信息死记硬背在权重里,极大地提升了价值评估的准确性。
两步训练,先用GPT-5生成的数据SFT,然后冻结actor,用REINFORCE训练critic,奖励为 Rv(s,z)=1−(r−v^)2,RL pretrain阶段将 GAE 的超参数设置为了λ=1,退化为蒙特卡洛return。
因为初始阶段critic自己可能不够可靠,与其预测标准ppo里的bootstrapped target,不如拟合真实reward,联合训练的时候再进行更复杂的优势估计。
联合训练的过程中,为了避免给每个token都写一段长篇大论的推理,系统首先把 Actor 生成的整段回答切分成若干个有逻辑意义的片段(Segment,比如数学推理中的每一个步骤)。
针对每一个步骤,系统会把“原始问题”、“Actor 目前写出的半截答案”以及“Actor当前的平均胜率(ICC信息)”拼接在一起,套用预设的模板,交给 Critic。
critic给出thinking和预测分,系统会对比 Critic 在这一步给出的“预测胜率”和最终真实的“答题结果”,以此来计算 Critic 这次打分准不准,并给 Critic 的这段推理过程分配一个奖励分数。
advantage估计过程中,因为 Critic 刚才是在“片段”级别打的分,系统会把这个片段的预测分数,复制广播给该片段里的每一个具体的词(Token)。结合最终的真实奖励和每一个词的预测得分,系统通过 GAE 算法计算出每一个 Token 的Advantage。
实验finding
这部分实验主要想回答三个问题:生成式 Critic 到底准不准、能不能真帮 Actor 变强、以及它为什么比传统 Critic 更稳。
生成式 Critic 的表现全方位碾压传统 Critic。随着模型参数的增加,它的打分误差在持续稳步下降(具备了极好的扩展性 Scaling Law),而且不同随机种子下的表现非常稳定,彻底解决了传统 Critic “不随模型变大而变强”和“极其脆弱”的两大顽疾。
放到强化学习里,GenAC 的整体表现最好,而且更省训练步数
- 在数学推理任务上,研究者用 Qwen3-8B-Base 作为初始策略,拿 DeepScaleR 数据集做强化学习训练,再去六个数学基准上测效果。
- 对比了GRPO,RLOO,VC-PPO,GenAC,带 value model 的方法,早期通常比无 value 的方法更省样本。但如果这个 value model 只是传统判别式版本,后期就容易“顶不住”。
- GenAC 提升最快,样本效率最高,而且随着训练步数的增加,当其他所有方法都陷入瓶颈、不再进步时,GenAC 的性能依然在持续攀升,不断拉开与其他方法的差距。
一些分析实验
1.即使把GPT-5这种很强的模型拿来做提示式价值估计,它依然很难直接变成准确的 value function。也就是说价值模型不是普通的“LLM-as-a-Judge”任务。它强依赖“当前 Actor 是谁、现在处于什么训练阶段”的上下文信息。
2.生成式 Critic 的 top-1 排序准确率,始终高于判别式 Critic。候选集越大,差距越明显。判别式 Critic 在候选变多后,准确率掉得很快,甚至接近随机。生成式 Critic 则掉得更慢,保持了更强的区分能力。
3.实验还考察了价值模型在不同分布上的表现,从训练集内数据一路测到更难、更多变、甚至跨领域的数据。在训练分布内,生成式 Critic 只是略优。一旦数据偏离训练分布,它的优势明显放大。在 AIME24 和 GPQA 上,误差降幅非常可观,最高超过一半。
OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning
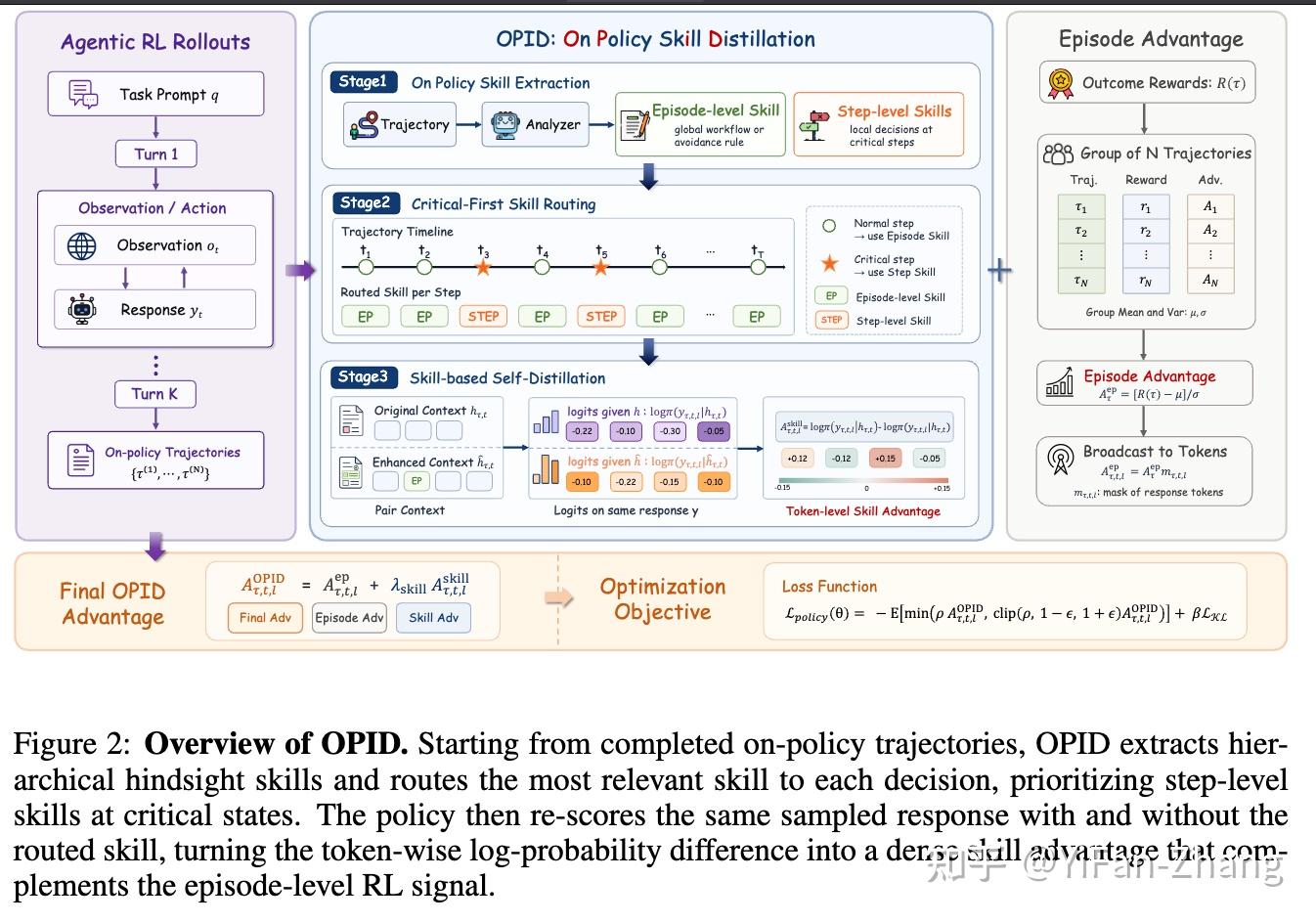
现有的一些自蒸馏或技能蒸馏方法虽然能补充更细的监督,但很多都依赖:外部技能库;检索到的特权上下文以及预先维护的技能记忆。这些做法有两个明显问题:
- 维护成本高,要不断插入、更新、删除和检索技能
- 容易和当前策略分布不一致,尤其是在多轮交互里,轨迹稍微偏一点,原本检索来的技能就可能不再适用
OPID先从当前策略自己跑出来的完整轨迹中提炼出“全局技能”和“关键步骤技能”,再按状态重要性选择最合适的技能,把技能差异转成 token 级自蒸馏优势,最后和组相对结果奖励一起做 PPO 更新。
从完成的 on-policy 轨迹里挖技能
这篇方法的重点,不是依赖外部技能库,而是直接从当前策略自己采样并完成的轨迹里提炼技能。这里的“on-policy”很关键,因为这些轨迹来自当前模型真实在跑的分布,所以提炼出来的技能更贴近训练时的状态分布,不容易出现“技能和当前场景对不上”的问题。
OPID 把轨迹知识拆成两层:
1.轨迹级技能 它总结的是整条轨迹的全局规律,比如:
- 这类任务通常怎么推进;成功时通常遵循什么工作流;失败时应该避免什么通用错误
- 这类技能比较宽泛,稳定性强,适合作为默认指导。
2.步骤级技能 描述的是某些关键时刻的局部决策知识,比如:
- 避免重复无效动作;下一步该检查哪个对象;什么时候该修正子目标;什么时候该停止探索
- 这类技能更精细,但只在少数关键位置出现,而且高度依赖状态。
对一条完成的轨迹,系统会先把它整理成一份有序记录,然后用一个基于大语言模型的分析器,把这份记录转成结构化自然语言技能:
- 一条轨迹对应一个轨迹级技能
- 还会找出若干个关键时刻,给这些位置生成步骤级技能
这些被标出的关键位置构成一个稀疏集合,表示“这几个地方特别重要”。
- 如果当前步属于关键时刻,就用步骤级技能
- 如果不是关键时刻,就退回到轨迹级技能
路由之后,OPID 会把选中的技能塞回交互历史里,形成一个技能增强后的上下文。这个注入动作是确定性的,既可以加在历史前面,也可以加在后面,只要不破坏原始状态信息即可。关键点在于:不是重新生成一条新回复,而是让旧策略对“同一条已经采样过的回复”重新打分。
于是,同一个 token 会有两种对数概率:
- 原始历史下的概率
- 加入技能后的概率
两者一减,就得到一个“技能是否支持这个 token”的信号。对每个 token,OPID 定义一个技能自蒸馏优势:
- 如果加了技能之后,这个 token 的概率变高,说明这个 token 和该技能更一致,应该鼓励
- 如果概率变低,说明这个 token 和技能不太一致,应该抑制
这个差值再乘上一个有效 token 的掩码,只保留真正参与生成的部分。
最后的信号来自组相对结果优势+ \lambda 技能自蒸馏优势。作者默认整个训练之后这些skill基本内化到模型内部,inference正常做即可。
实验finding
1.相比只看终局奖励的 GRPO,OPID 在大多数模型规模和任务上都有稳定提升。在较小的底座模型上,提升尤其明显,说明这种“从轨迹里提炼技能”的方式,对能力较弱的模型帮助更大。
2.实验里不光比了 GRPO,还比了不少很强的技能蒸馏、自蒸馏方法,比如 Skill-GRPO、GRPO+OPSD、Skill-SD、RLSD、SDAR 等。OPID 在不少总分指标上能追平甚至超过这些强基线。
3.Skill-GRPO 这类方法在去掉验证时技能提示后,性能明显下滑,甚至有些场景还不如普通 GRPO。OPID 即使在推理阶段完全不提供技能输入,依然能保持明显优势。
4.早期,OPID 和 GRPO 都能往上走,到了中期以后,GRPO 容易进入平台期,OPID 还会继续往前推进。同时OPID 的平均 episode length 明显变短,能更快完成任务。
5.少数据时特别有用,样本效率明显更高,数据越少,OPID 相对 GRPO 的优势越明显。用大约 60% 的数据,OPID 就已经接近 GRPO 用全量数据训练出来的效果。用到 80% 的数据时,OPID 甚至已经能超过 GRPO 的全量训练结果。
6.分层技能确实有用,少一个都不行。但是如果不做路由,而是把全局技能和局部技能直接叠在一起,效果反而更差。采用“关键点优先用步骤级、其他地方默认用轨迹级”的策略,能明显提高性能。这说明技能不是越多越好,关键是在对的地方用对粒度。
总结
GLM 5.2 解决的是长任务 compaction 后 GRPO 失效的问题——超长轨迹被切开后,不同 rollout 产生的子轨迹数量和长度都不一样,组内相对排名没法做了。
改用 critic-based PPO 做 token 级 advantage,配套两阶段反作弊(规则 + LLM 裁判),只拦具体违规动作而不中断轨迹。从 PPO 切回 GRPO 再切回 PPO,背后是同一个洞察:traj 越长,value-free 的 credit assignment 越不可靠。
Qwen 的验证系统讲了四类任务:SWE 类靠 Agentic Quality Judge 清洗"烂尾"任务(很多零解决率其实不是真难,是任务质量差),靠Trajectory Monitor把作弊率从 28.57% 打到 0.56%;前端类靠25.9项打分表+交互式裁判(模拟真实点击操作)粉碎代码堆砌式作弊;
真实世界类靠提取用户隐式反馈训练 Span-KTO,发现用户极少夸奖但骂得很准(81.8% 高置信度),丢弃差评反而让模型变笨(41.8%→37.2%);超长周期任务靠裁判智能体自己写测试,迭代五版专治各类毛病,核心point:验证器和生成器必须协同进化,固定的验证系统迟早被更强的模型攻破。
GenAC 发现传统 Critic 的问题不只是训练技巧:价值函数本身可能很复杂(某些生成 MDP 价值计算达 P-complete),而固定深度的 Transformer 受限于 TC0,根本"一口报不出数"。
生成式 Critic 让模型先 thinking 再输出整数,结合当前 Actor 的参数规模和胜率,训练后具备 Scaling Law(误差真的随模型变大而下降)和极强稳定性(换种子不崩)。
放到 RL 里,GenAC 样本效率最高,当 GRPO/RLOO/VC-PPO 全部陷入瓶颈时它仍在攀升,AIME24 和 GPQA 上误差降幅超一半。
OPID 从自己的轨迹里挖技能,分轨迹级(全局工作流)和步骤级(关键时刻局部决策),按状态路由。小模型提升更明显;去掉技能提示后依然保持优势;GRPO 中期就平台了,OPID 还继续走;用 60% 数据接近 GRPO 全量效果,80% 数据超过全量。
最反直觉的是:把两类技能简单叠加反而更差,必须按关键点路由才能发挥作用。