作者:haotian
https://zhuanlan.zhihu.com/p/2010293867208021164
目前,为了追求上限,各家都尽可能地使用onpolicy训练。对于agentic任务,往往是全异步配置,不可避免带来offpolicy的问题。offpolicy在使用合适的训练setting,也可以获得比较好的训练稳定性,如routing-replay、采样次数:梯度更新次数限制在8以内等等。
笔者去年12月份写了一个简易的proposal:如何让采样次数:梯度更新次数在大于8,甚至到256的时候,依然能稳定训练(虽然会提升收敛速度,但上限会低于小于8次的效果)。
基本的形式化如下(seq-level):

从seq-level的角度出发,
IS-ratio不是一个很稳定的训练配置:variance会随着action-space、序列长度的增加而增加(可以从ESS角度分析)。
此时,variance是一个大头,可以牺牲一定的unbias换取low-variance。一个很直观的方法:self-normalized-importance-sampling(snis):

这个方法有个几个训练配置的需求:
1.mini-batch-data必须包含一个prompt的所有rollout样本--->计算w(x,y);
2.参数更新后,需要recompute normalized weight:\tilde{w}(x, y_i);
进一步,[5]提出了


无独有偶,笔者浏览到iclr26的一篇文章[4],发现一篇类似的工作(但因为hallucinated citation被desk-reject,初始分数:6662)。
当然,性能也是不错的:([4]提供了更多关于snis的理论分析等等,但只做了lora-rl的训练)
GEPO
与之比较相关的一个工作:GEPO(训练a100,推理ascend910a)
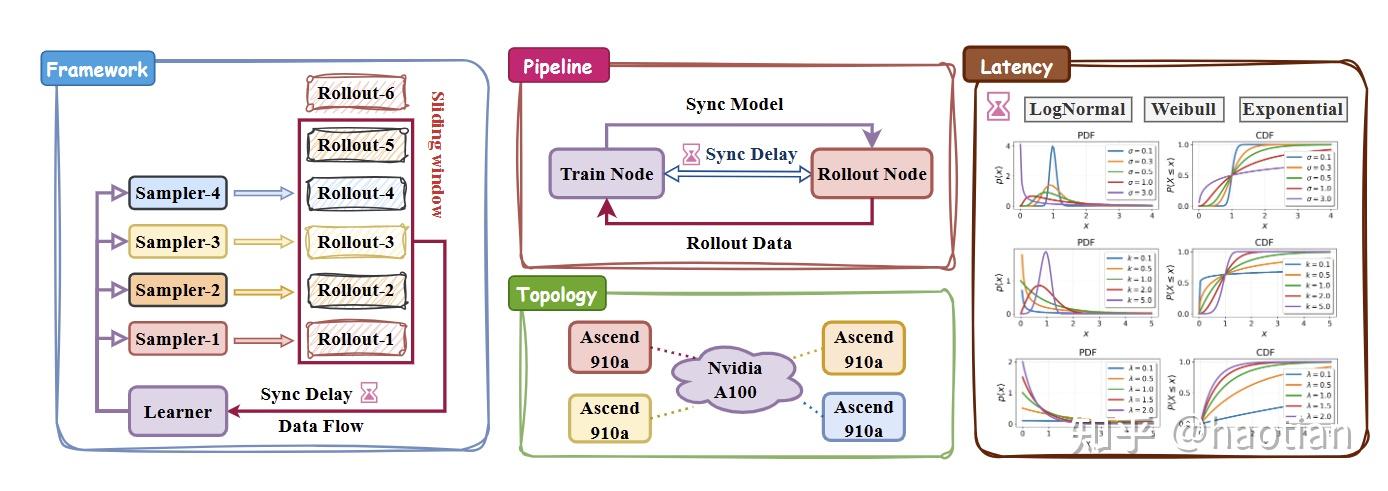
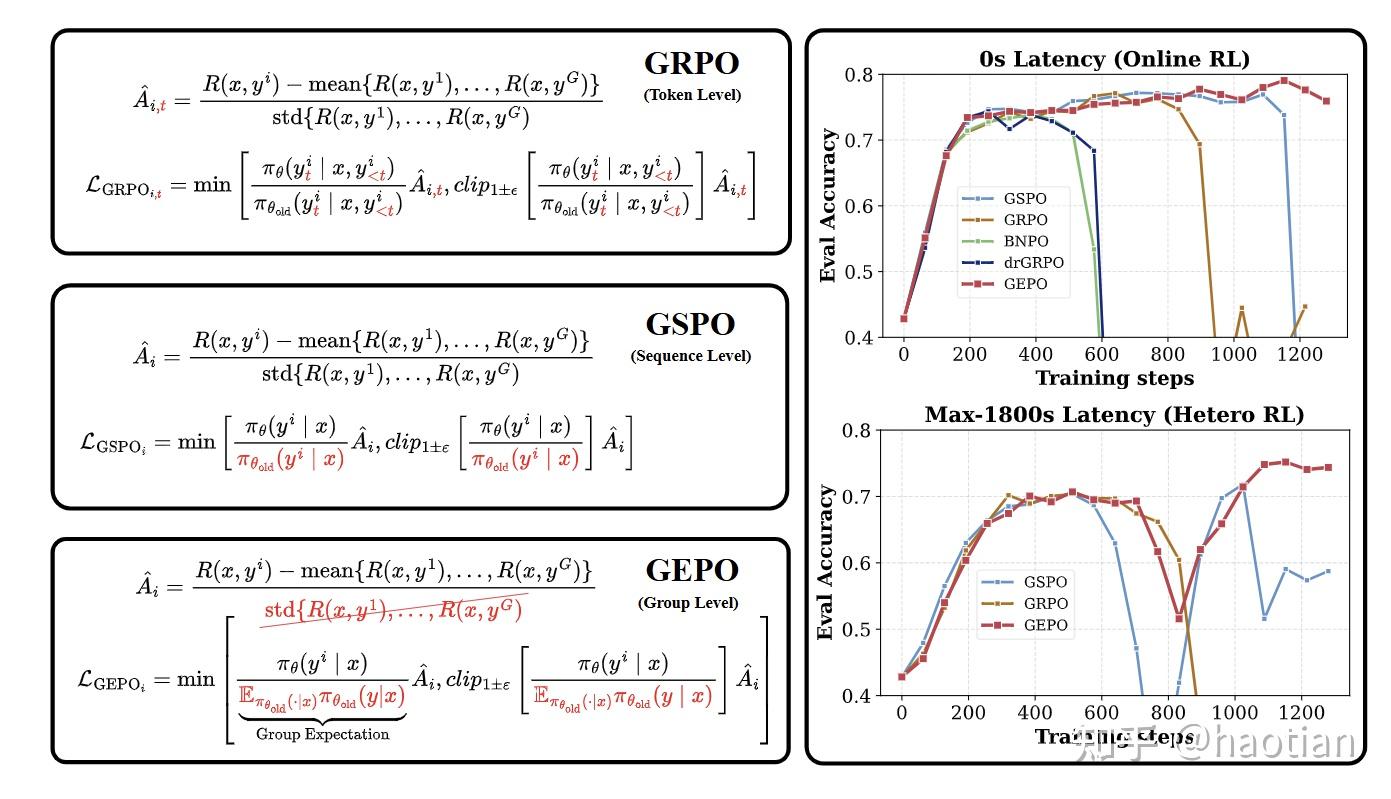
其核心公式:
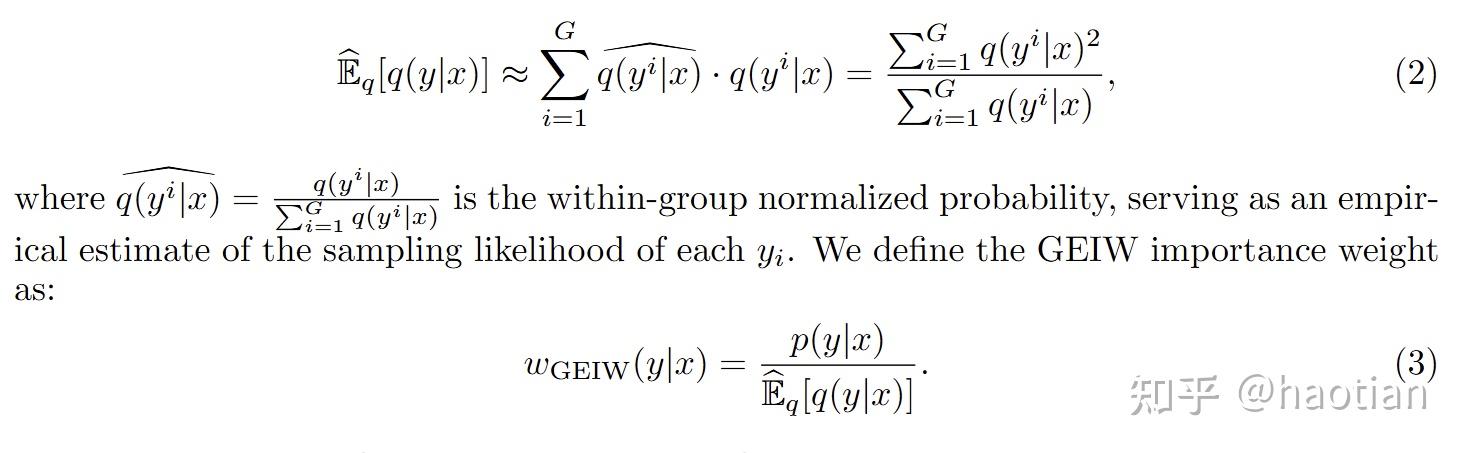
使用GEIW后,作者证明了如下定理: variance指数级下降相比朴素的P/Q
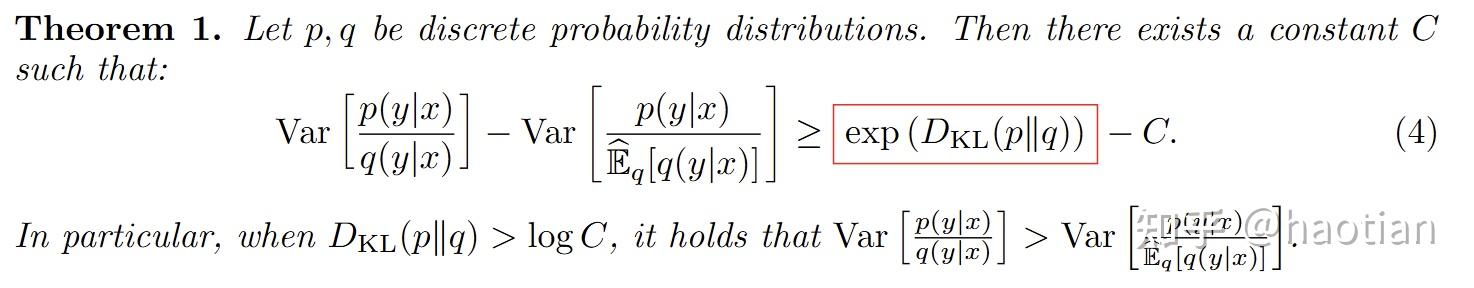
bias如果过大,也不太行,作者附录额外分析了gepo的bias:
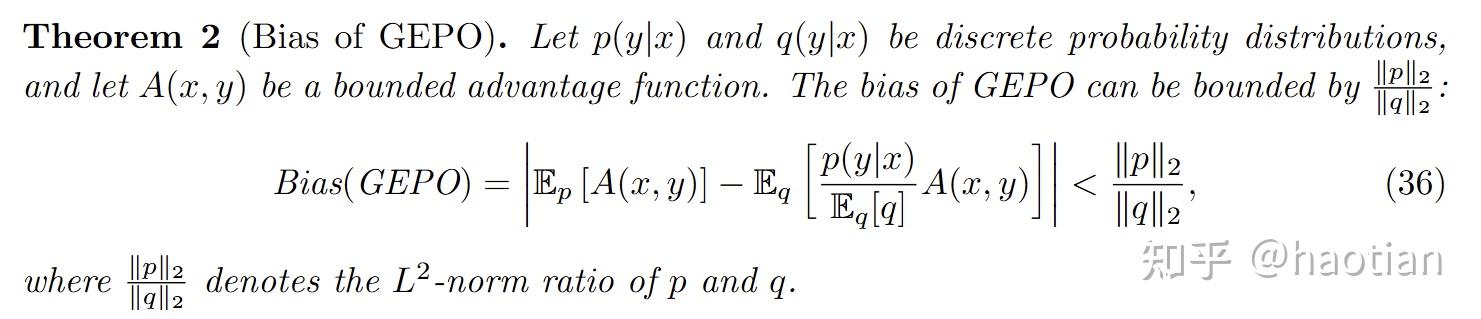
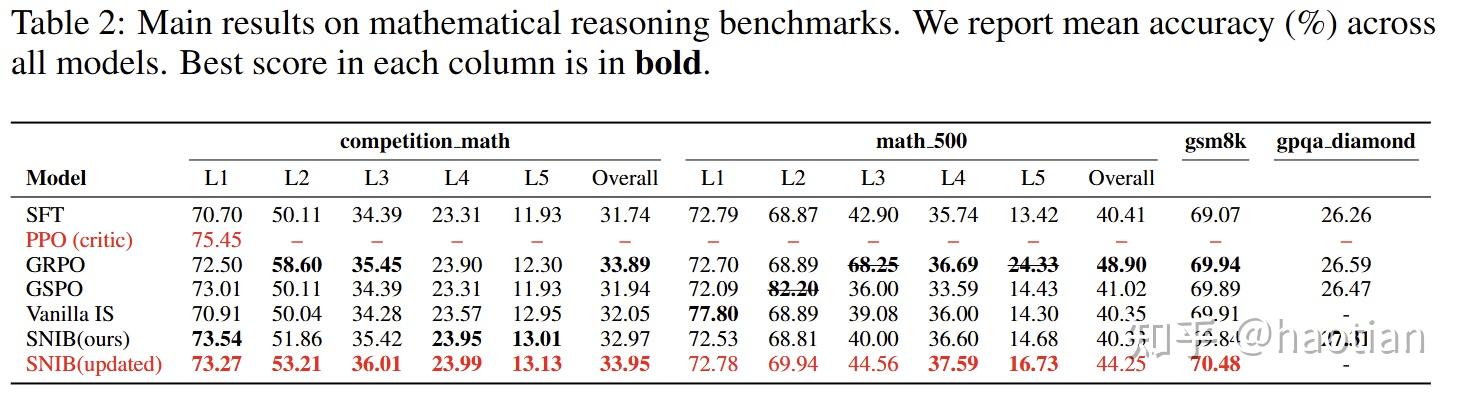
实验设置上,作者使用了math500的level3-5的数据集作为rl的训练数据,think-mode下,设置的output-length=4096。
实验结论:

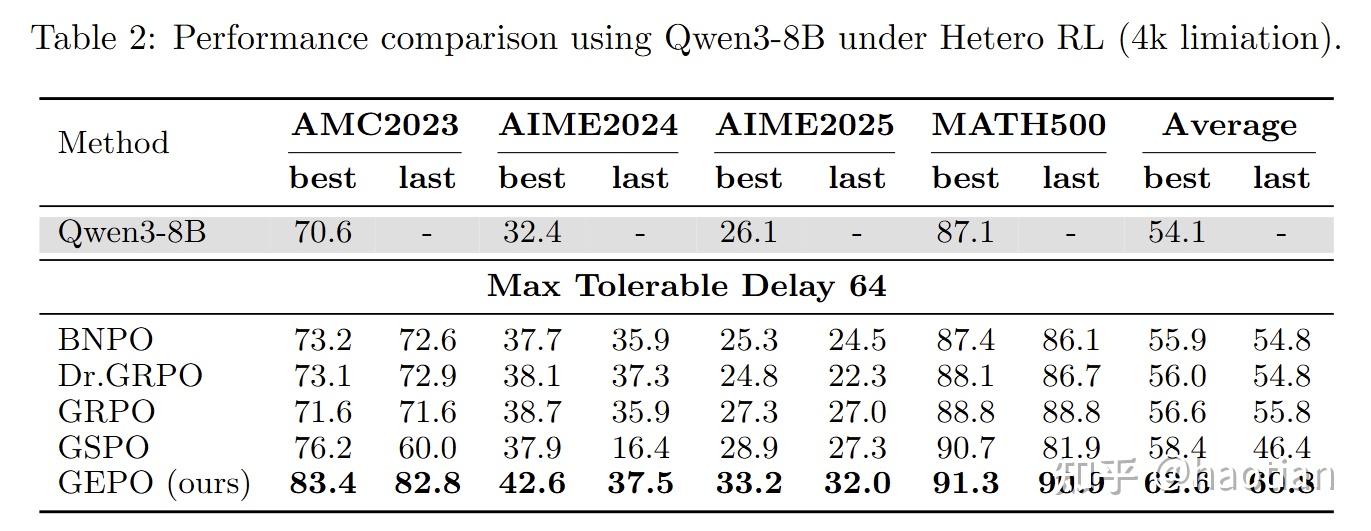
VESPO
考古AIS相关的文献,找到一篇[6],里面提到

与VESPO比较相关的是variational-representation:proposal-distribution视作weighted-sum-of-kl-divergence between two distributions。在RL场景下,则为policy-distribution和rollout-policy-distribution。
VESPO将policy-gradient with off-policy correction做了形式化的表示,对于后续的求解比较关键。
另外一篇则是来自小红书团队的VESPO。这个工作笔者觉得比较有启发性,实验结果也还不错。
首先,作者形式化并统一了不同的方法:

可以统一写成:
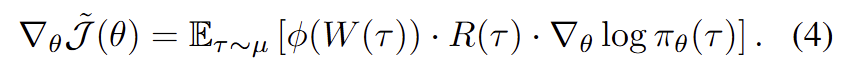
当写成上述表达式后,作者提出了 “Weight Reshaping as Measure Change”
(大白话:不同的weight-shaping诱导出了不同的proposal-distribution)
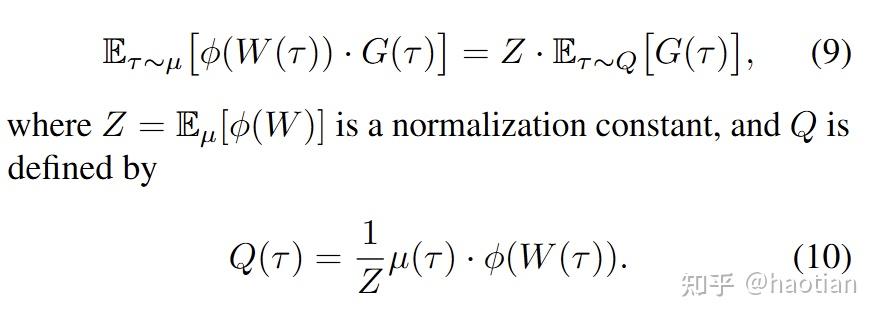
有了这个形式化,后面的推导水到渠成:通过一些约束,找到q的closed-form-solution。很直观的一个约束想法:
Q需要靠近采样分布和policy分布--->作者选用了kl-div(可以换成其他divergence):
可能有个小问题:当rollout-data相比policy过于陈旧,\mu 和 \pi的差距过大,使用如下度量方法,q也不是一个好的proposal(效果应该decay的比较严重)
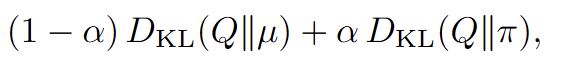
且q的variance不能太大,且q是一个合法的概率分布:
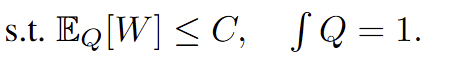
q的采样variance需要一定的近似,作者使用ess近似。
带约束的求解,使用拉格朗日即可(与带kl约束的最优分布推导过程类似),作者得到:
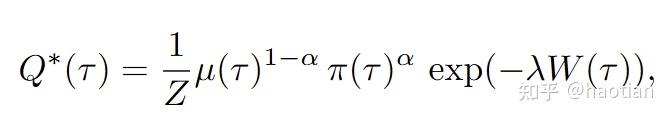
再对比公式11,即可得到Weight Reshaping\phi(W)的表达式:
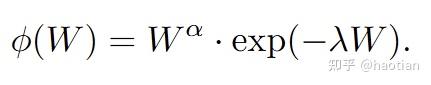
带入loss和梯度公式中,可以得到:
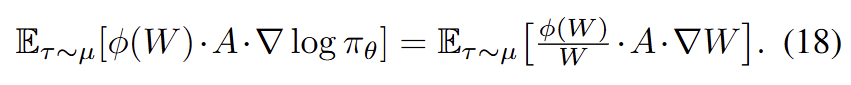
为了兼容onpolicy,

剩下的就是
当然,该工作的实验结果也是很不错的(具体实现的时候,在对数域操作,保持数值稳定性):
当N=64时(rollout一次,更新梯度64次),效果decay的很严重(很奇怪,作者没有汇报dense-model的staleness结果)
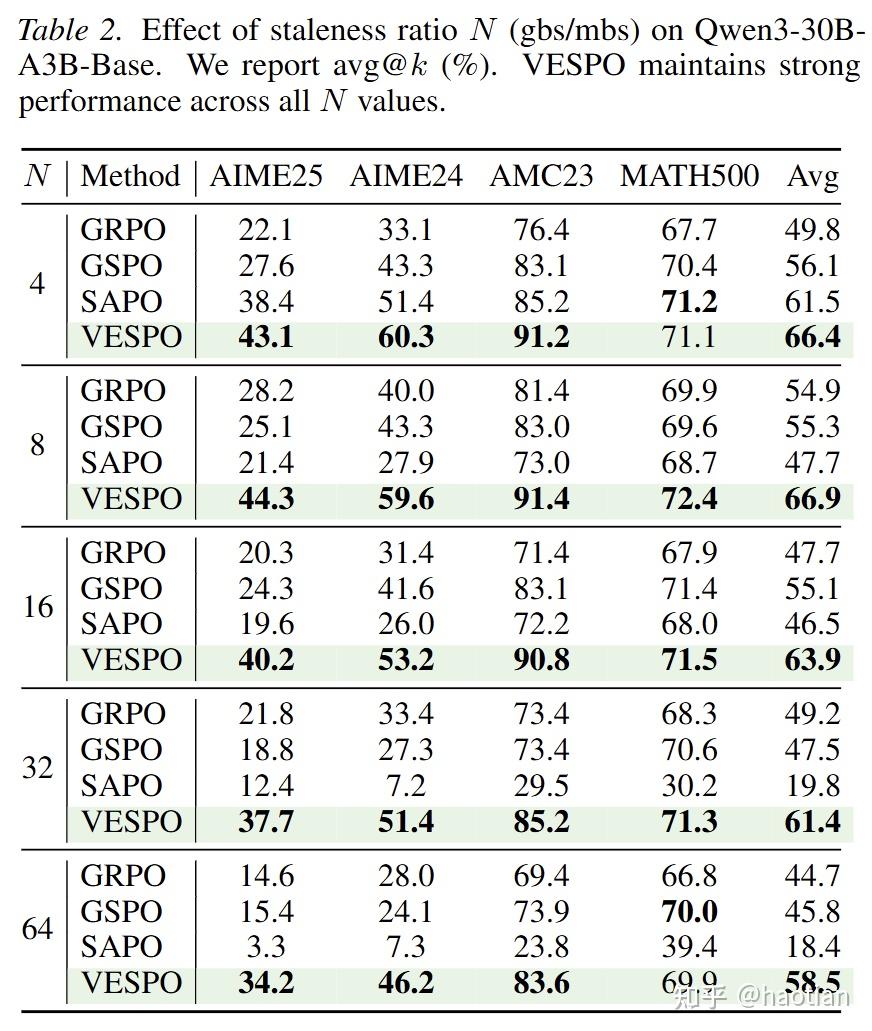
训练稳定性在不同的delay下,都保持的很稳定(不需要引入额外的routing-replay等等):
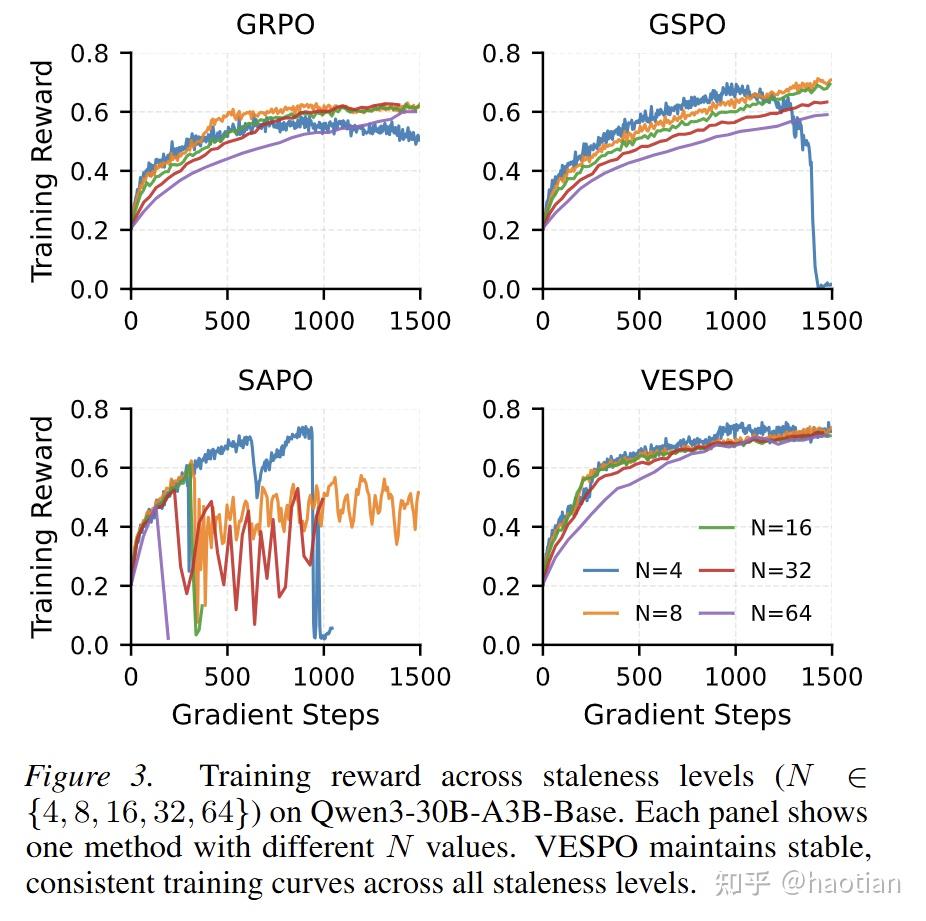
当然,由于gepo、vespo两个工作使用的数据集不相同,且gepo主要在异构芯片上的实验,两个工作相当难直接对比(需要额外跑实验)。但这两个工作都提供了比较好的视角:staleness比较大时候,如何保持训练稳定性。
当然,也需要和比如seq-mask+token-mask(所谓的“metropolis-independence-po”)这种方法对比。
最后,使用importance-sampling估计期望的时候,可能需要更复杂的proposal-distribution,诸如annealed-is、parallel-tempering等等,需要在效果和效率上折中。vespo提供了一种proposal-distribution的“自动化”寻找的方案(当staleness很大的时候,proposal-distribution可能不是很合理)。
Mask MCMC Great Again。
最后的最后,笔者觉得,即使做了weight-shaping,依然还是 sparsity的优化,比较不同方法的sparsity:更新参数比例、位置等等(参考[3],进行更详尽的分析,可能可以从optimization的角度,给出一些新思路和方法)。
参考文献
[1] GEPO: Group Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning
https://arxiv.org/abs/2508.17850
[2] VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
https://arxiv.org/abs/2602.10693
[3] The Path Not Taken: RLVR Provably Learns Off the Principals
https://arxiv.org/abs/2511.08567
[4] PRINCIPLED POLICY OPTIMIZATION FOR LLMS VIASELF-NORMALIZED IMPORTANCE SAMPLING
https://openreview.net/pdf?id=HVciz8hi1c
[5] Pareto Smoothed Importance Sampling
https://arxiv.org/abs/1507.02646
[6] Annealed Importance Sampling with q-Paths
https://arxiv.org/abs/2012.07823