直播间的观众朋友们,大家好。首先祝大家新年快乐。刚刚过完假回来,今天很高兴受邀来到青稞社区给大家做一个技术分享。主题是关于 MiniMax M2.1 的 Agent 后训练技术。
我先简单介绍一下 MiniMax M2.1。M2.1 是我们在上一代 M2 模型的基础之上,进一步做了后训练优化的模型。同时也是我们上个月开源的最新的主力模型,它是一个总参数量约为 230B、激活参数在 10B 左右的 MoE 模型。
M2.1 这个模型本身的特色,就是在整个 Agent 场景下有比较好的可用性,在激活参数很小的情况下达到了非常好的效果,同时速度也非常快。
下面就正式开始今天的分享,分享的技术内容主要分为几个方面:
- Agentic 数据合成(最核心的部分)
- Agentic RL框架与算法
- Agent 评测:(自建的评测Benchmark)
- Q&A 环节
Agentic 数据合成
那就先说数据合成。数据合成大概分为三个部分:
- 真实数据驱动的数据合成:SWE Scaling
- 专家驱动的数据合成:AppDev
- 虚拟长程任务合成:WebExplorer
前面两个其实是关于 coding 的场景,后面这个是偏通用的搜索场景。
真实数据驱动的数据合成:SWE Scaling
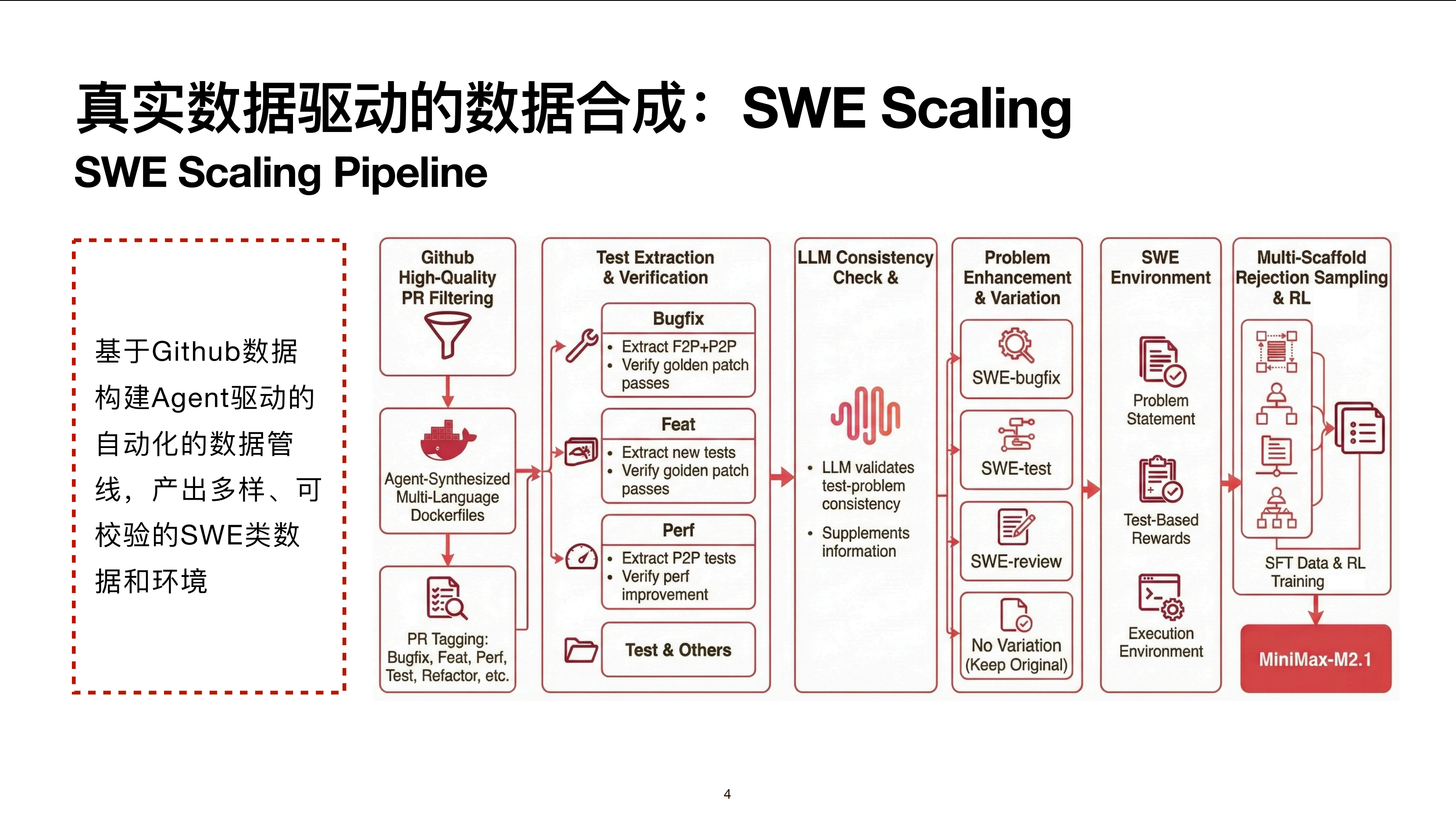
首先是一个比较核心的东西,就是整个软件工程场景下的数据 Scaling。这里有一个非常核心的点,就是要利用好 GitHub 这样一个非常庞大且结构化的数据来源,去合成各种各样 Verifiable(可校验)的任务。有了这些任务之后,无论是去做拒绝采样、构建 SFT 数据,还是去做 RL,都会有非常好的数据基础。
我大致介绍一下整体流程。最原始的数据来源是 GitHub 的 PR(Pull Request)和 Commit。这里会去做质量筛选,方法有很多,简单一点的可以筛选最终被 Merge 的 PR,当然也会有一些其他的规则,比如是否带相关的测试用例。
有了这些 PR 之后,接下来一步是相对核心的点,我们要针对这些 PR 构建一个能够运行的 Docker 镜像环境。
镜像环境的构建本身不是一件容易的事情。现在的通用做法是通过 Agent 在代码沙盒里给它一些工具,让它不断地 Build,并根据 Build 结果进行自我迭代循环,尝试把环境构建出来。
理想情况下,这个过程可以完全自动化,但目前还没有达到特别理想的状态。在特定语言或特定库的版本中,环境不一定能构建得很好,这时会需要一些有经验的专家知识来帮助优化 Agent 的执行流程,这种流程算是一种 Skill(技能)的注入。
这样,我们就针对这些 PR 构建了一个可以运行的虚拟 Docker 镜像环境。
在这一步之后,会对 PR 本身做一些 Tagging(清理)和分流。PR 本身包含很多种数据类型,比如 Bugfix、增加 Feature、性能优化、测试用例的构建与重构等,大概有几十种。
做分流的目的是因为对于不同种类的 PR 或 Commit,后续利用的方法是不太一样的。
举个最简单的例子,比如最主流的 Bugfix 场景,我们会去抽取它的一些 F2P 以及 P2P 的测试用例。有了这些测试用例之后,我们可以去校验。例如当一个 Golden Patch 能通过时,我们认为这条数据是可以通过的,那么最后让模型作为一个 Agent 在沙盒里修复这个 Bug,并用 F2P 和 P2P 的 Test Case 去校验它是否真的通过了。
这里 P2P 的主要作用是防止在修复 Bug 的过程中引入额外的 Bug。如果进入新增 Feature 的场景,上述做法可能就不一定成立。例如在新增 Feature 的情况下,写的测试用例可能会依赖新增功能本身的代码脚本(如函数签名)。
这种情况下,它在构建阶段可能就失败了,不一定会存在 F2P 或 P2P 的测试用例,而且测试用例的抽取逻辑就会不同。例如需要专注于抽取 PR 过程中新增的测试点,然后同样需要校验原始 Golden Patch 至少在这些新增测试点上是能够通过的。
再比如在性能优化上,并不存在修复 Bug 的过程,所以不一定存在 F2P 测试,这种情况下就是抽取 P2P 测试,包括定位真正做了性能改进的测试点,去验证它在修复前后确实有稳定且显著的性能差异。
这里举的是一些基础例子,不同种类的 PR 也会有不同的做法。
在这一步之后,进入第三步(列),即模型对数据做校验。校验的目的是因为,即使在基础的 Bugfix 场景下,由于使用的是原始 GitHub PR 数据,有的并不规范,或者测试用例不一定能准确涵盖原始描述的 Issue。这种情况下会出现按照问题描述永远解不了 Bug 的情况。
这时就需要通过模型对原始测试用例和问题做校验,确保其一致性。如果确实缺失关键信息,可以通过模型在原始问题描述中做补充,保证它是一个自包含的完整问题。
在这一步之后,对于同一个 PR 或 Issue,有很多种不同的利用方式。比如,可以增加额外的 Bug,或者把多个相邻的 Commit 或 PR 合并到一起,增加难度,类似于 Swiss Cheese 的做法。
还有一种做法是,Bugfix 场景和 SWE-Test场景是可以完全等价转换的。原先 Bugfix 是指在应用 Golden Patch 之前会挂掉,应用后能通过。
如果把它改造成写测试用例的任务,任务就反转过来了:要求模型写一个测试用例,使得它在应用 Patch 前的代码库状态下会 Fail,而修复后能通过。这对应到模型需要有较强的写测试用例的能力,且该任务与原先的 Bugfix 同源,并且是 Verifiable 的。
再者,可以做代码审阅类的任务。代码审阅任务与前面有些不同,它可以直接从 GitHub Filtering 这一步连线到 SWE Review,原因是本质上可以构建一些不需要完全运行环境的代码审阅任务。
比如我们平时在本地开发项目,本地环境不一定能完整运行所有测试或跑起整个代码库。这种情况下,模型需要看代码库,静态分析文件间的依赖关系并提出问题。由于不依赖环境构建,它可以做到更好的多样性。
工作原理是类似的,PR 包含修改前后的文件,如果模型能 Review 出修改前已包含的 Bug,再用一个 LLM 校验其一致性,本身也可以作为近似可校验的任务。总的来说,可以有很多问题的变形和增强方式。
最终,我们会得到一个 SWE 类的数据及其运行环境,包括原始问题描述、基于测试用例的完全 Verifiable 的 Reward,以及 Docker 运行环境。
有了数据之后,用法包括 SFT 和 RL。在 SFT 方面,我们会通过多脚手架(Multi-scaffold)去做拒绝采样,以此优化模型的泛化性。
另外在 RL 方面,使用多脚手架的原因是现在的脚手架往往包含复杂的上下文管理逻辑。如果只在一个简单的 React Agent 框架里做数据,模型很难泛化到其他脚手架的行为上。
比如在 Claude Code 里会有很多 System Reminder 或 Skill claude MD 等内容,如果模型从未见过,它就没有办法泛化到训练数据未涉及的空间。所以我们会有一套完善的工程基建,确保能在多脚手架环境中对模型做拒绝采样,生成更好的轨迹。
整个 SWE 数据核心思想的总结:基于原始 GitHub 数据构建 Agent 驱动的自动化数据管线,产出多样的、可校验的 SWE 类数据和环境。
这方面很需要创造力,比如任务的合成方法以及可校验任务的构建。目前这方面的研究很多,最近也有很多新的开源工作出来,大家可以关注。

截止到 M2.1,我们整个 SWE 数据的 Scaling 已经做到了不错的状态。覆盖了超过 10 种主流编程语言,涵盖了各种代码任务类型和编程场景。最终可用的 Repo(能直接跑 SFT)数量大于 1 万个 PR,可变任务数量超过 14 万个。
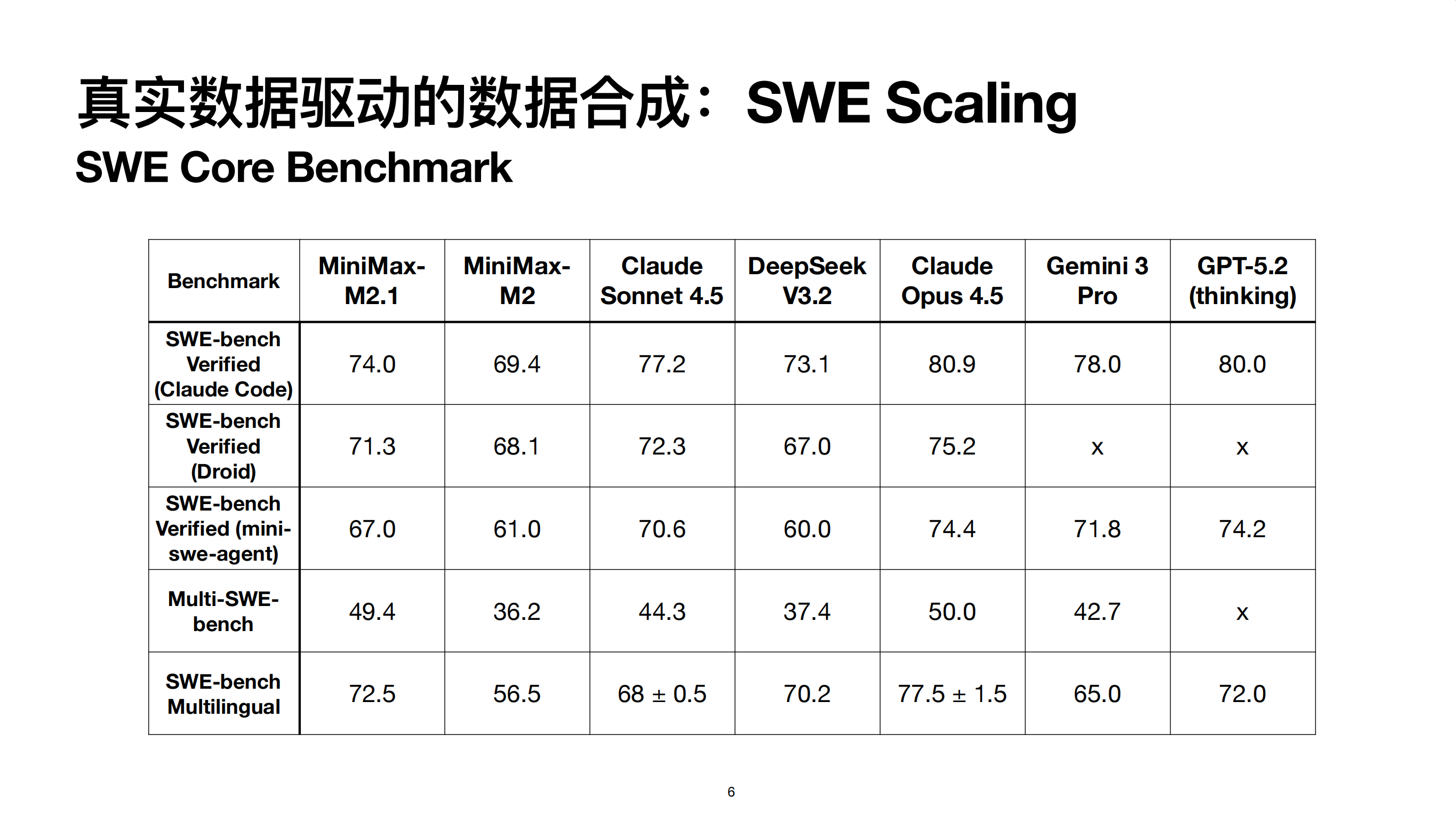
最后是在几个 SWE 类核心榜单上的指标。对比 M2.1 和 M2,尤其在 Multi-SWE、SWE-bench 等多语言场景上,由于做了更充分的 Scaling,有显著提升。
另外在不同脚手架上评测,能发现模型保持了较好的性能稳定性。不同脚手架的上限不同,比如 Claude Code 设计较好,而 Mini-SWE-agent 本质是纯 Bash 脚手架,通过 Bash 读写文件会消耗更多 Context,导致模型上限更低,这符合预期,但模型对不同脚手架展现了较好的适应性。
专家驱动的数据合成:AppDev
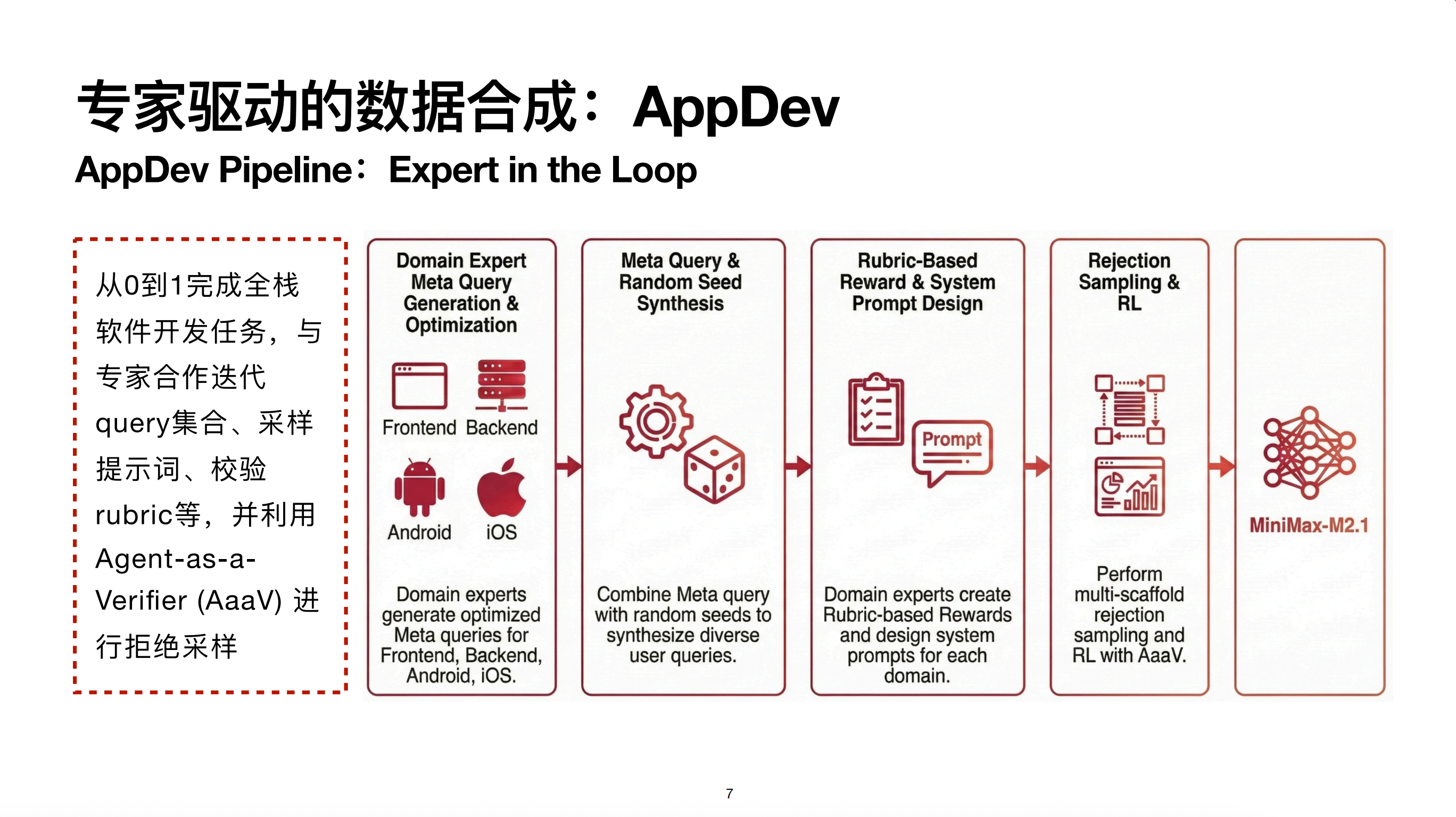
Coding 方向,我们将其分为两类:SWE 类和 APPDev 类。
我们将 APPDev 定义为从零到一完成全栈软件开发任务。将其与 SWE 区分的原因是,APPDev 开发无法预先定义一系列固定的测试用例。SWE 场景基于 GitHub,行为空间受限,是在成熟 Repo 中操作;而 AppDev 是从零到一编写,无法预先限定死测试用例,其 Reward 链路与 SWE 完全不同。
在 APPDev 场景中,会用到 Expert in the Loop,利用数据专家的经验来帮助迭代和生成数据。
目前 M2.1 重点关注前端、后端、安卓和 iOS。公司内相关场景的专业研发同学会作为数据专家加入,帮我们优化 APPDev 的数据合成。
比如最开始,专家会写一些 Prompt 或 Meta Query。这些 Meta Query 结合特定场景的 Random Seed,能合成多样化的用户 Query。有了 Query 后进行采样,采样前需要构建 Rubric-based Reward,这非常依赖专家经验,因为不同专家对不同任务的校验标准不同,无法通过全自动方法完成。
除了 Rubric,专家还可以在流程中注入经验。例如在写网页前端时,上一代模型 M2 会有一些不好的习惯,比如写出较丑的渐变色。而专家可以设计一些先验 Prompt 指导页面设计。如果模型有不错的 System Prompt 遵循能力,就能在指导下采样出更好的轨迹。有了轨迹后,可以使用类似于 Prompt Tuning 的方法,采样时带有 System 信息,但训练时去掉,这样专家的 Best Practice 就会变成模型的默认行为。
最后是在多脚手架上做拒绝采样及 RL。此外,还会利用 Agent as Verifier 来做 Reward 校验。原因是在前端等场景,仅给出一个 Rubric 很难根据静态代码做判断。我们会让模型在沙盒环境中把项目完整部署起来,通过 Playwright 等工具与界面交互,根据交互后的状态变化对照 Rubric 打分。
这与 LLM-as-a-judge 的区别在于,它需要利用工具做多轮交互才能进行判断。
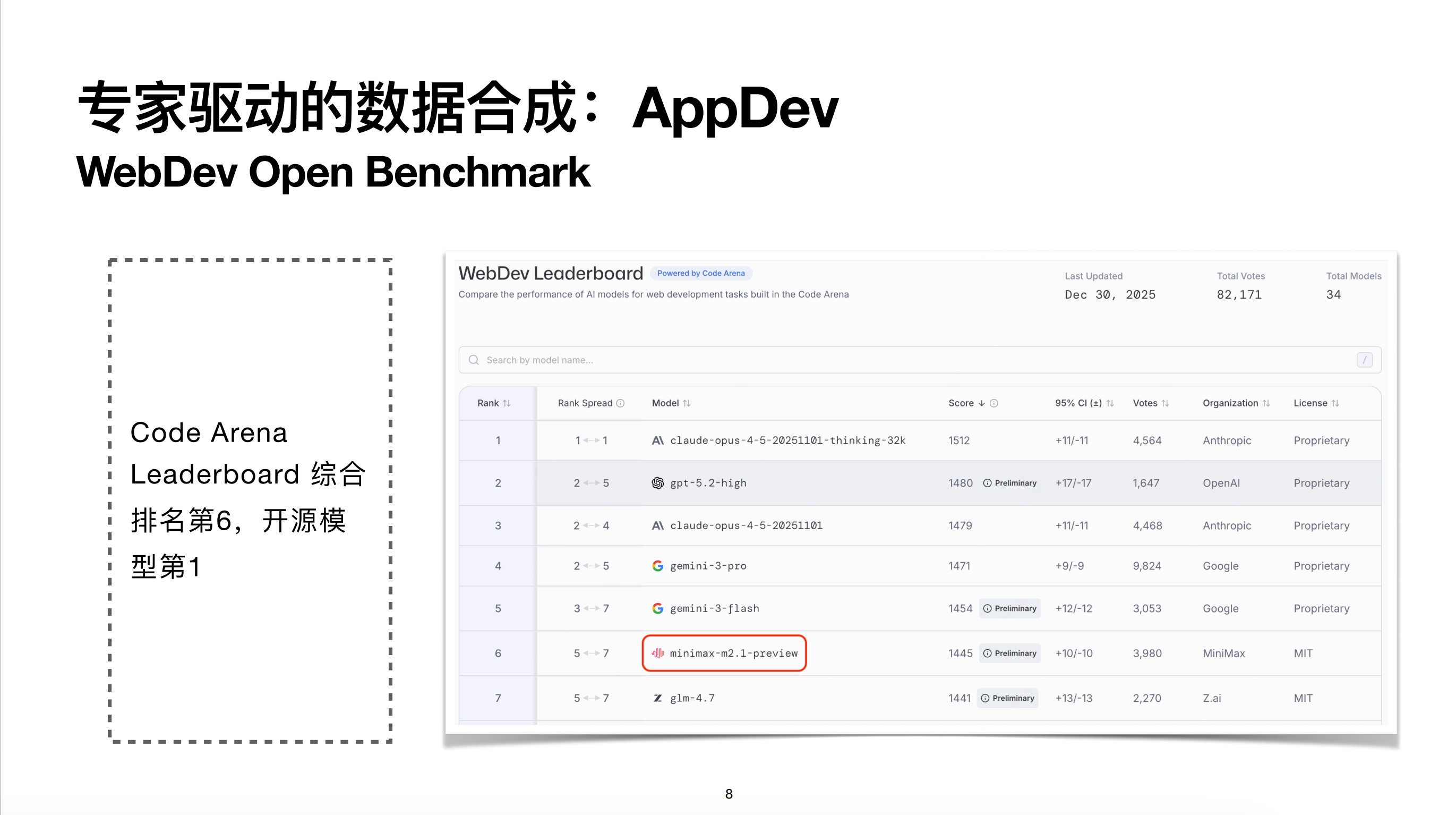
整个 AppDev 领域目前开源榜单中较受关注的是 Hot Arena,我们在上面排行开源模型第一。关于 App 我们也有自建榜单 VIBE Arena,后面会展开介绍。
虚拟长程任务合成:WebExplorer
 除了 Coding Agent 场景,我们也在投入精力做偏通用的 Agent 场景。Search(搜索)是通用场景的基础。
除了 Coding Agent 场景,我们也在投入精力做偏通用的 Agent 场景。Search(搜索)是通用场景的基础。
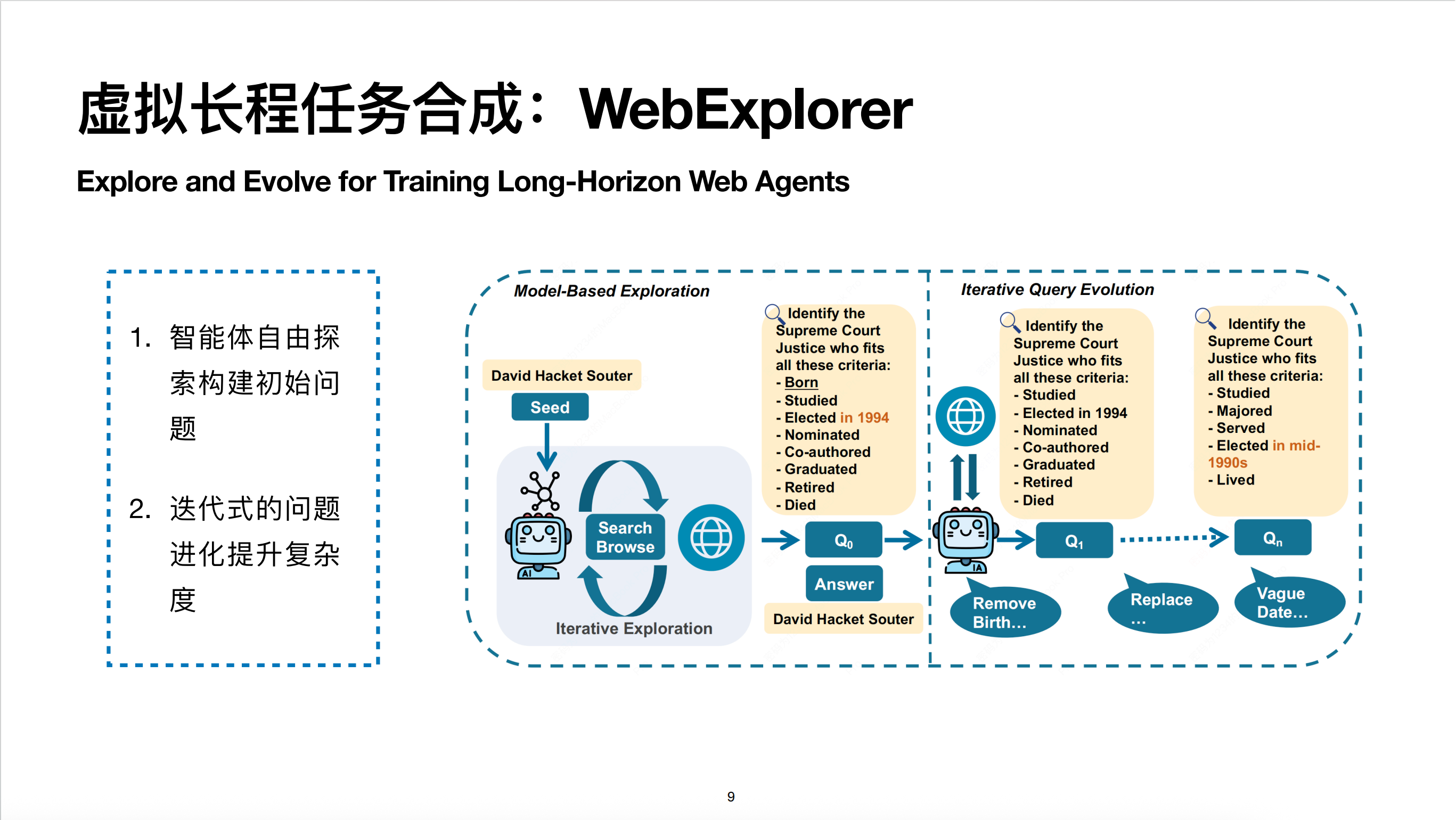
我们之前有一篇 WebExplorer 的工作: Explore and Evolve for Training Long-Horizon Web Agents,该工作目前在 arXiv 上可见。核心思想包含两部分:第一步是通过智能体自由探索构建信息丰富的种子问题;第二步是迭代式地进行 Query 进化来提升问题复杂度。

展开一个例子:对于 WebExplorer 来说,最开始只有一个随机种子,比如“巴西国家队”。模型通过搜索找到 1950 年世界杯及“马拉卡纳惨案”。比赛信息中提到裁判叫 George Reader,他多年后在英格兰俱乐部担任主席,该俱乐部在 1976 年足总杯击败曼联夺冠,制胜球由 Bobby Stokes 打进。
模型最后将搜索链路的线索综合,生成一个信息丰富的初始问题。这个问题虽然信息量大,但有明显的搜索入口。进化的策略包括移除、模糊化和替换。比如:
- 把具体的比赛信息模糊化为“赛制独特、没有淘汰赛的世界杯”;
- 把“足总杯击败曼联”这种显著信息改为“带领乙级联赛俱乐部战胜甲级豪门”,增加搜索难度;
- 把球员去世年龄等容易在 Wiki 搜到的信息移除。
最终进化出的 Query 相比初始问题复杂得多,没有明显的搜索入口,模型必须根据线索一步步探索。
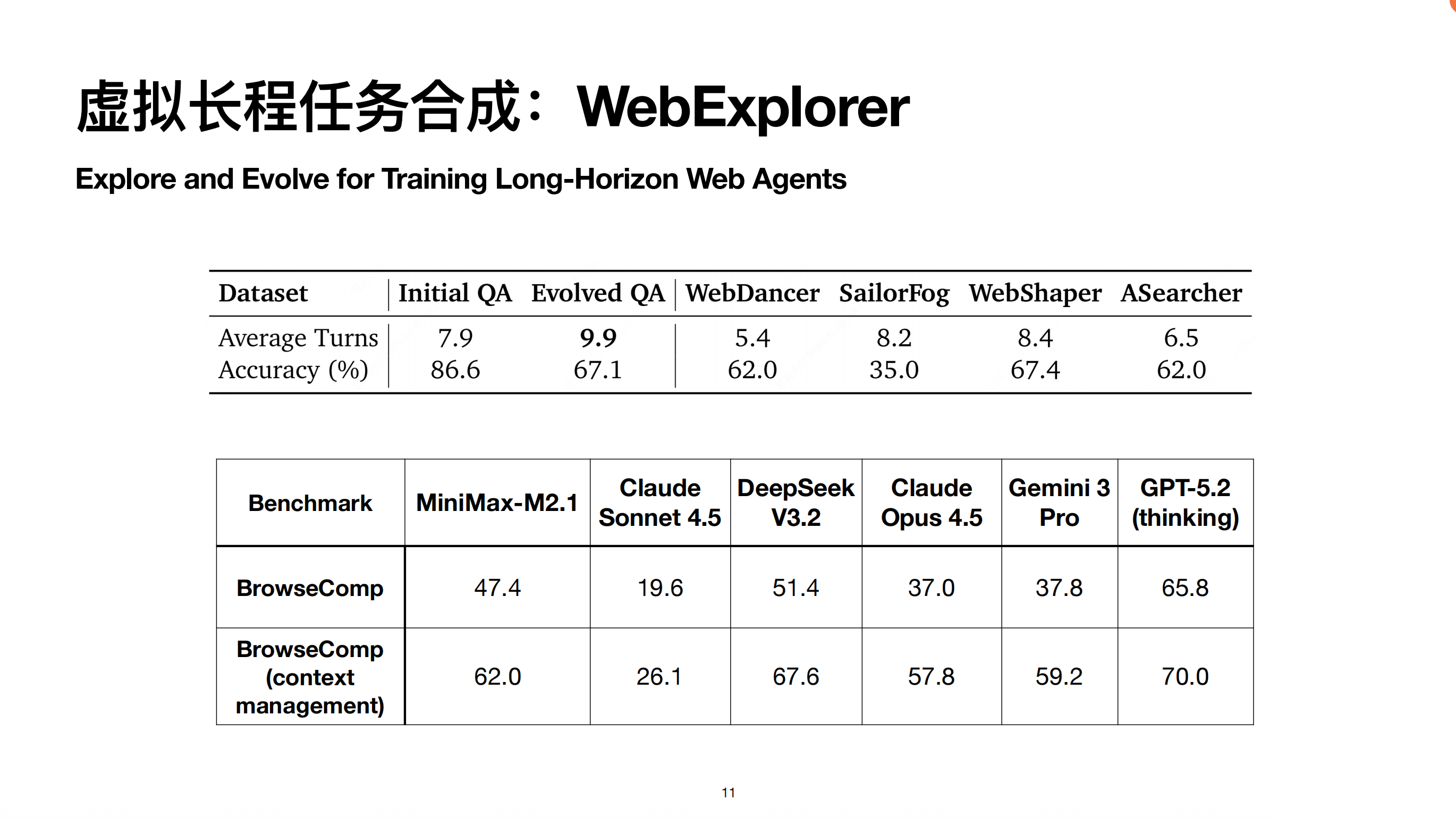
这种长程任务合成的标准是解决问题的平均轮次。初始问题约 7.9 轮解决,进化后达到 9.9 轮。该策略已上线 M2.1。最终 M2.1 在 BrowsComp 榜单上,尤其在带有 Context Management(上下文管理)的情况下,表现接近 GPT-4.5 的 SOTA 指标。上下文管理是目前 Search Agent 的主流做法,即在评测过程中不断清空上下文,保持其清晰干净,使模型能持续进行 Test-time Scaling。
Agentic RL 框架和算法
接下来介绍 RL 框架和算法。
Forge
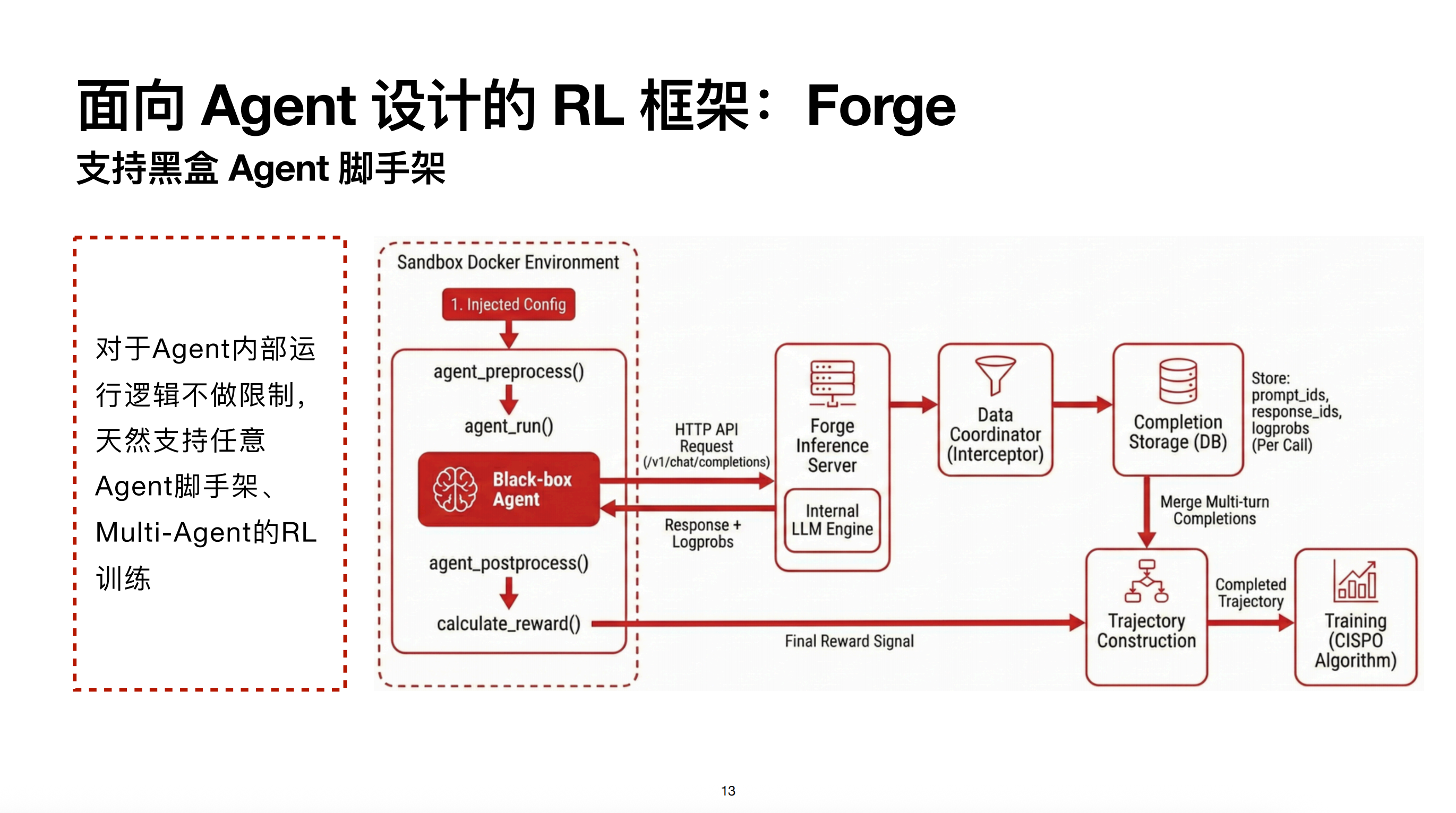
我们使用的是内部自研框架 Forge,它在 M2 研发之初就是面向 Agent 场景设计的。Forge 的一个重要 Feature 是支持任意 Agent 脚手架运行 RL。接入 Forge 只需实现四种接口:
- agent_ reprocess:预处理(初始化)
- agent_run:运行
- agent_ ostprocess:后处理
- calculate_reward:计算 Reward
例如,即使是只有二进制程序的黑盒 Agent 也可以接入。在 Agent 运行时,将其 Base URL 替换为 Forge 内部的推理引擎服务。目前该引擎已支持内部推理框架及 SGLang。替换后,Agent 运行循环中的所有日志都会在推理服务器端落盘。Data Coordinator 会对日志做后处理,提取 Sub-agent 的轨迹。为了提升训练效率,框架还会对 Trajectory 做智能的前缀合并。
CISPO
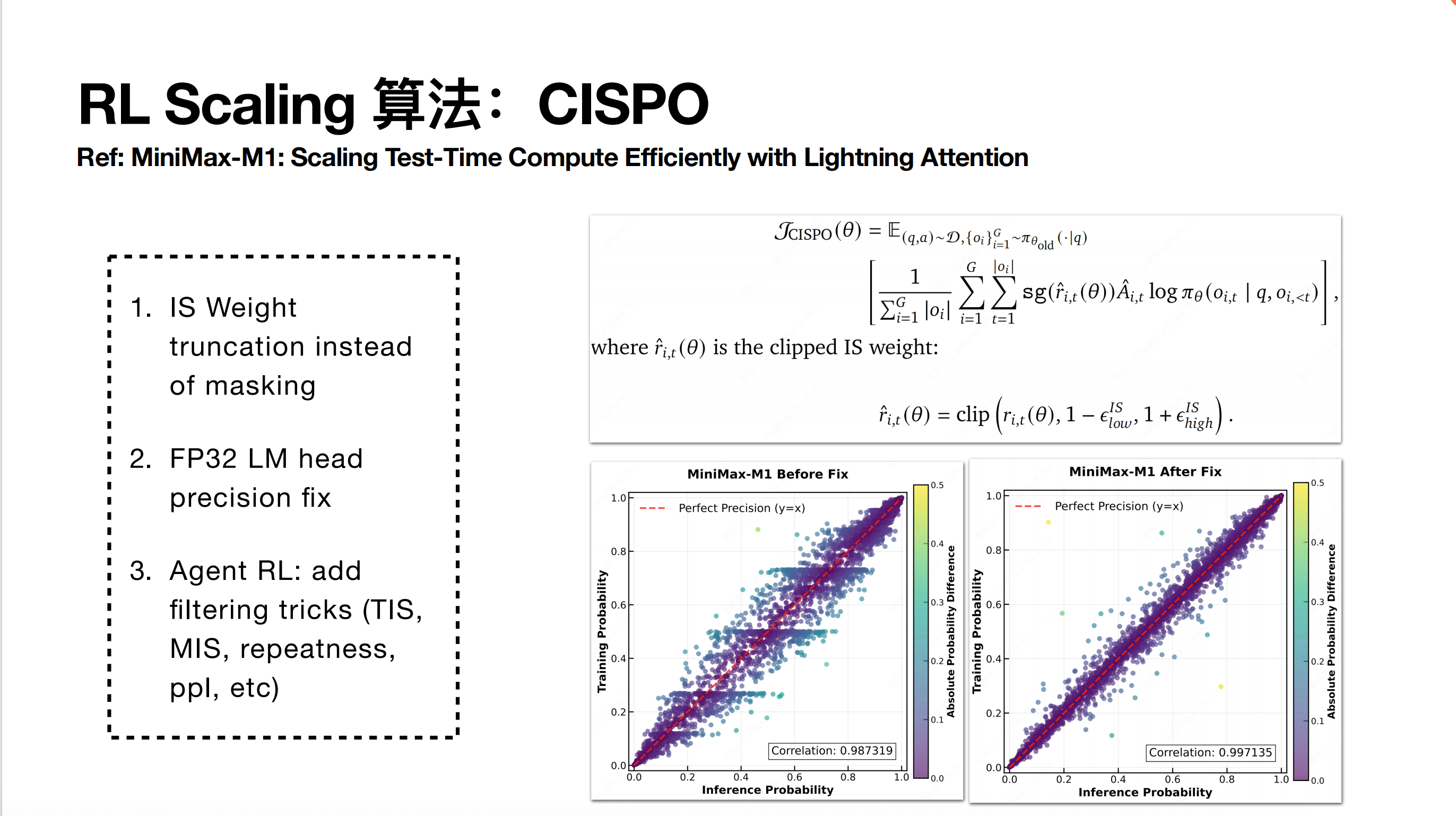
算法方面,其实我们截止到 M2.1 时代,整个 RL(强化学习)算法的核心仍然沿用了原先在 MiniMax M1 论文中所提出的 CISP 算法。当时在 M1 里面提到了两个比较核心的点:一个是 CISP 本身的重要性采样截断(Importance Sampling Truncation)设计,另一个是当时针对 FP32 精度做的修复。
第一部分是 CISPO 的目标函数。你可以将其理解为:它与 Reinforce 的目标函数非常相似。如果你把重要性采样比率(Importance Sampling Ratio)这一项去掉,它本质上就是一个 Reinforce 在 Off-policy 场景下做了重要性采样修正的目标函数。CISPO 改变的点在于,它会对重要性采样的权重——也就是标量加权的量——进行 Clip(裁剪)。在实践中,这个 Clip 通常是指限制其上限,从而确保梯度不会过大,本质上是在控制梯度的运行幅度。
CISPO 算法最初设计是在大家都在复现 RZERO 那套东西(包括我们自己的 DAPO)的时候。当时我们在复现过程中有一个核心观察:在整个 RL 运行过程中,有一些 Token 会一直被 PPO 的 Clip 机制过滤掉。一旦被 Clip,这些 Token 就永远失去了梯度。统计发现,这些 Token 往往是类似于 “wait” 这种转折词。这意味着 PPO 的裁剪机制会导致很多 Token 无法通过训练涌现出来。
在这种情况下,DAPO 的做法是提高 PPO Clip 的上界。而我们 CISPO 的想法是让所有的 Token 都可以计算梯度,只是我们需要控制梯度重要性采样的加权系数。通过这种方式,我们虽然引入了一些 Bias(偏差),但减少了整体优化的方差。
当时我们在前期完成小模型实验并迁移到 MiniMax M1 这个更大的模型做 RL 时,发现整体 Reward 几乎不增长。我们将训练概率和推理概率打印出来后发现,它们出现了一些明显的分段横线,且相关系数相比 Dense 模型低很多。后来推理同学进行逐层排查,最终发现预测层 LLM_head 的精度至关重要。将该层精度修复到 FP32 之后,整个训推一致性得到了显著加强,从而实现了稳定的训练提升。
再到 M2 这一代,主要的变化在于它进入了 Agentic RL 的场景,涉及多轮工具调用。这些工具调用本质上会引入来自外界环境的噪声注入,导致运行轨迹变得更加极端、更加 Off-policy,或者出现统计值异常的情况。
在这种情况下,我们吸收了社区提出的一些主要方法,包括 MIS(重要性采样修正)以及基于 PPO 的轨迹过滤。这里的核心思想是过滤掉统计值偏离异常、处于长尾分布的轨迹,防止梯度出现巨大波动,从而保障整体 RL 训练的稳定性。
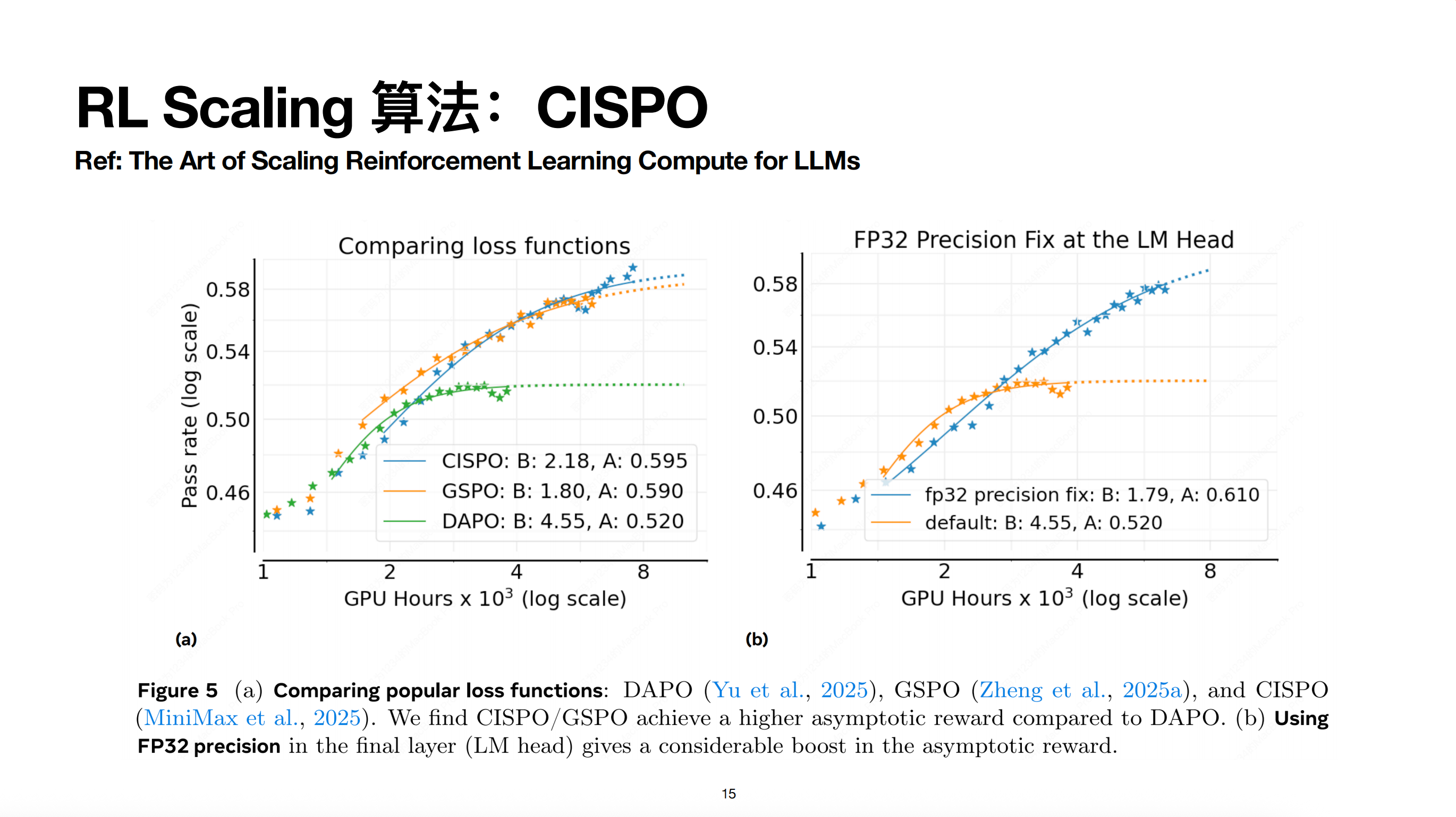
这个图引用了 Meta 论文《The Art of Scaling Reinforcement Learning Compute for LLMs》里的一张图。当时他们其实做了一个比较系统的实验对比,他们的实验结论与我们也是比较一致的。
实验发现,整个 CISPO 算法无论从收敛速度还是收敛上限来看,在整个 Scaling 的过程中表现都非常出色。图中左侧部分刻画的是 CISPO 的重要性采样(Importance Sampling Trick)的效果,右侧部分则刻画了 FP32 精度修复带来的收益。
总的来说,这篇文章的实验做得非常充分。如果对强化学习(RL)感兴趣的同学,我建议并推荐大家可以去看一看。
Agent 评测
接下来分享一下我们在 M2.1 时代同步推出的三个评测。
- VIBE: Visual & Interactive Benchmark for Execution in Application Development
- SWE-Review
- OctoCodingBench
目前 VIBE 评测的数据已经在 Hugging Face 上开源了,不过它的基建现在还没有完全就绪,我们也在紧锣密鼓地推进中。
VIBE
首先说 VIBE,它对应的是 AppDev(应用开发)场景。由于市面上缺乏衡量此类效果的榜单,我们自建了该评测,涵盖了前端、模拟安卓、iOS 和后端。M2.1 相比 M2 在这方面有长足进步。

在校验逻辑上,我们采用了 Agent as Verifier 的方案,即利用智能体在真实环境中执行。其 Reward(奖励)包含三个维度:
1、 执行层:验证代码是否编译成功;
2、交互层:使用工具与界面进行交互,判断业务逻辑是否正确;
3、 视觉层:基于美学标准打分,虽然这带有主观性,但我们会关注一致性较高的标准。

相比传统的 LLM-as-a-judge仅通过静态截图进行评估,Agent 验证能够通过动态交互,更全面地反映 Bug 和实现上的缺陷。
SWE-Revier & OctoBench
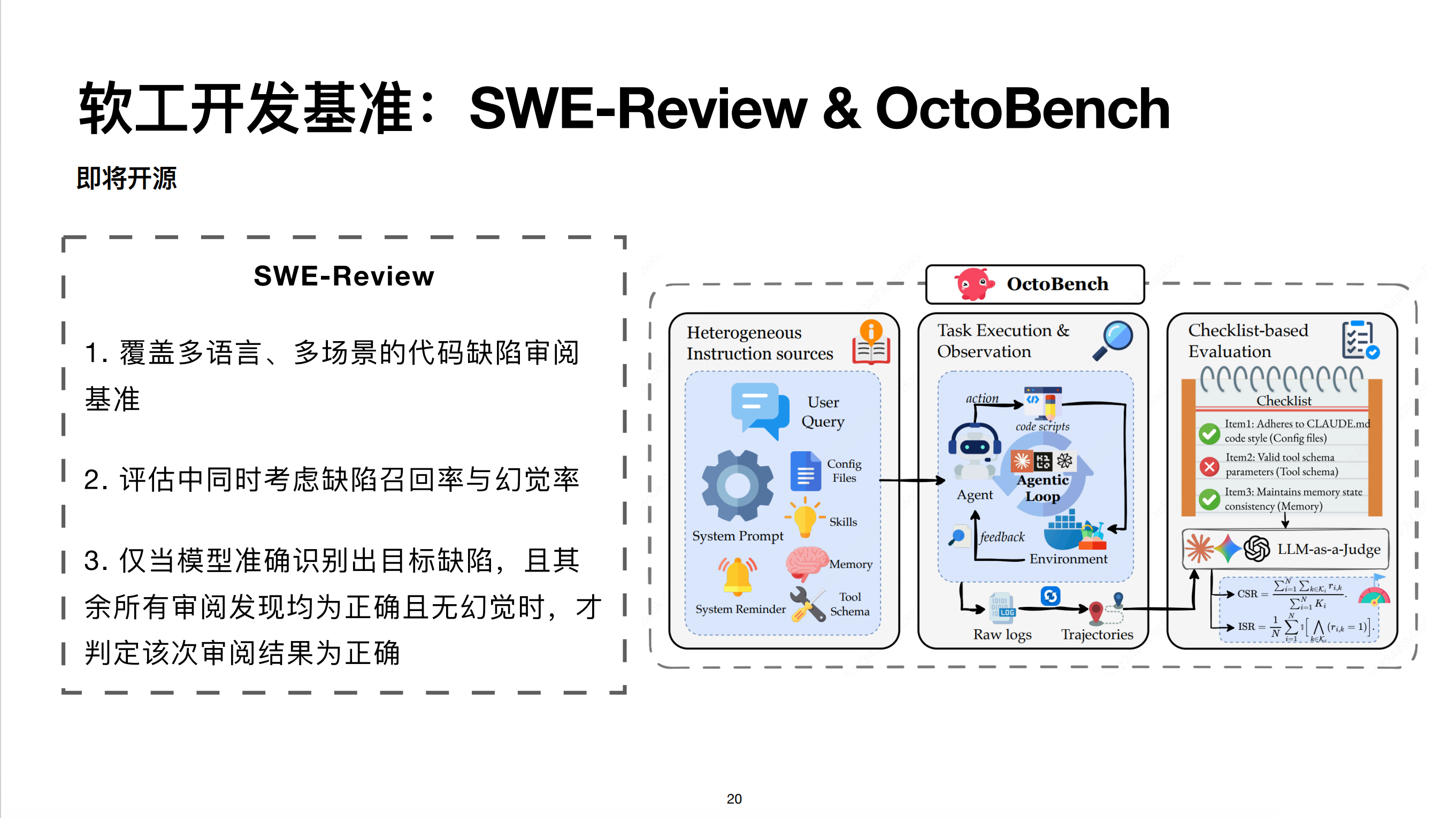
另外两个是 SWE Review 和 OctoBench。SWE Review 对应管线中的审阅场景,设计了覆盖多语言、多场景的评测集,指标同时考虑召回率和幻觉率。OctoBench 评估 Agent 场景下的指令遵循能力。
与传统的 IF 榜单不同,Agent 场景中的指令不只来自 User 或 System Prompt,还可能来自 System Reminder、Cloud.md 或工具 Schema。OctoBench 同步自研,通过 Checklist 进行 Rubric-based 打分。
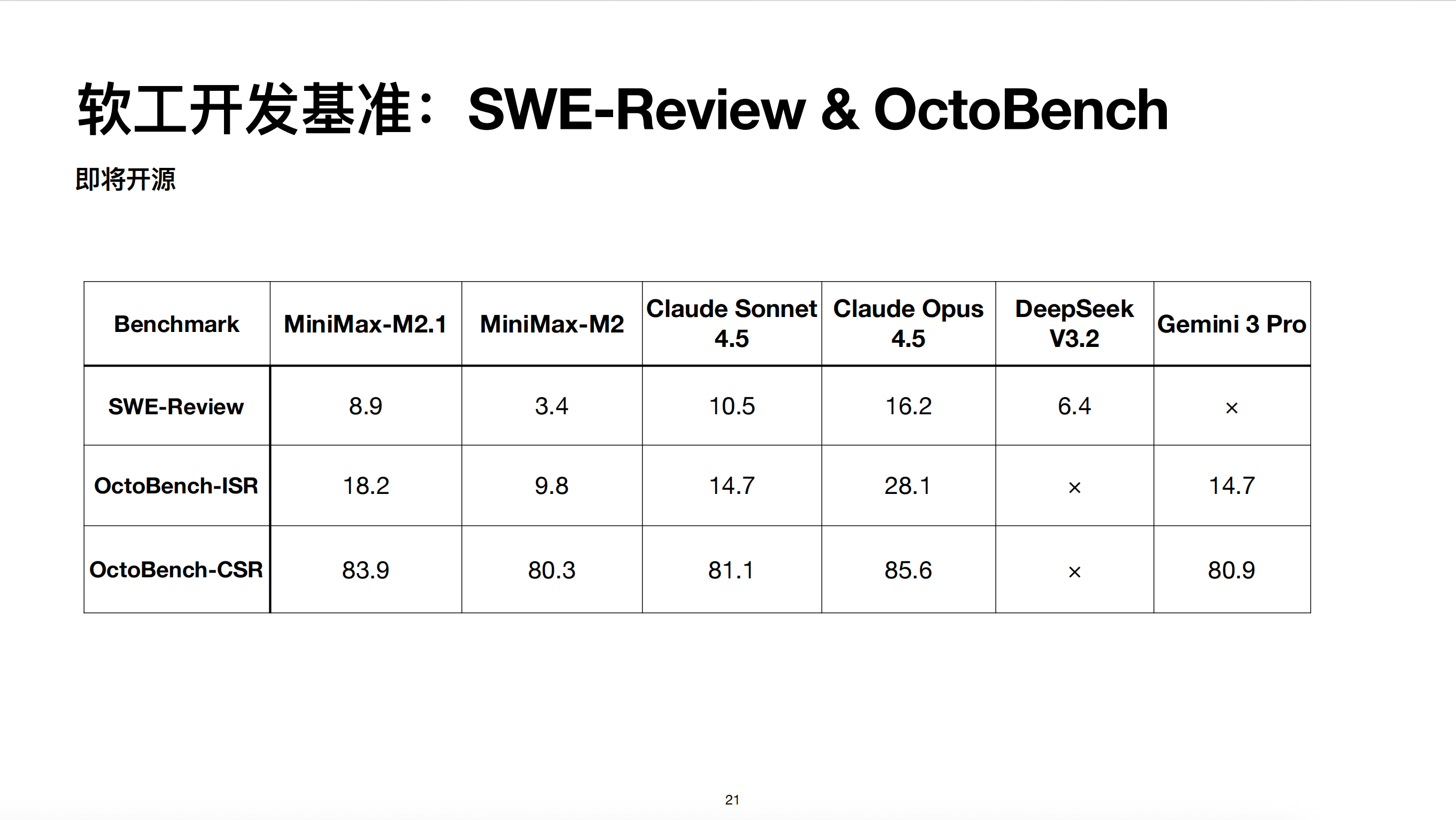
最后是这个指标。M2.1相比于 M2,因为我们在这方面做了一些优化,所以其实整体提升还是比较显著的,包括 SWE review、OctoBench 的这个指令遵从的效果。
我这边的分享的主要内容就大概到这里,下面进入问答环节。
Q&A
Q1:Base 模型完整后训练到 Instruct 模型,数据配比怎么确定?
比较坦率地说,我们现在在进行整个数据混合的时候,其实不会提前特别先验地去拍定一些数据的占比。我们其实是让各个数据方向自己去做一些 Scaling(扩展)实验。包括观察该方向在整个扩充数据的过程中,其性能到多少时会出现饱和。
如果某个方向在达到一定数据量后已经出现了饱和,就不再增加。最后在正常合板(数据合并)的时候,用的就是这么多数据。所以,我们最终数据的整体混合占比,其实是由不同数据方向的同学通过 Scaling 实验得出的结论,来最终导出合板时的数据占比的。
Q2:如何确保 SWE-test 阶段 LLM 生成的测试用例是正确、合乎规格的?
O这个其实在 SWE 管线里面有提到。对于一个特定的 PR(Pull Request)来说,它其实包含了修复之前的 Repo 状态、修复之后的 Repo 状态,以及测试用例的一些更新。
如果我们把它变形成了一个 SWE-test 的任务,那你其实可以要求它写的用例同时在修复前(即 Apply 这个 Golden Patch 之前)去运行,以及在 Apply 这个 Golden Patch 之后去运行。
如果该用例在 Apply Golden Patch 之前会 Fail 掉,而在 Apply Golden Patch 之后能够通过,那就说明你写的测试用例能够正常检测出原始代码中的 Bug,也能够在 Bug 正确修复之后顺利运行。通过这种方式校验,就是一个正确的、合乎规格的测试用例了。
Q3:有MultiAgent、Agentic RL入门项目推荐吗
让我想一下,其实现在 Coding Agent 领域有很多开源且做得很好的项目,大家都可以去关注。比如最近比较火的 OpenCode,我们公司最近也开始在关注这个项目,它是完全开源的,建议大家去关注一下。
关于 Agentic RL,目前主流的框架中,大家使用比较多的是 verl,slime 。除此之外,微软有一个叫 Agent Lightning 的项目,它的框架设计思路与我们 MiniMax 内部的 Forge 其实非常相似,它也支持一些偏黑盒(Black-box)的 Agent 训练。所以那个项目大家也可以重点关注一下。
Q4:SFT的拒绝采样有哪些判断标准?
OK,其实拒绝采样的成功与否,主要取决于具体的任务类型。
如果是完全可验证(Verifiable)的任务,判断的主要标准就是它的校验(Verification)有没有通过。比如传统的推理(Reasoning)任务,像数学题、逻辑推理题,以及算法编程题,这些都是完全可验证的。
而在 Agent 场景下,比如 SWE-bench(软件工程)或者 BrowsComp(网页搜索),这些任务的结果同样可以直接通过规则进行校验。
当然,在规则校验的基础之上,你还可以额外增加一些维度来判断整个执行轨迹(Trajectory)的质量。例如:
- 工具调用失败率:如果模型在过程中出现了过多无效或错误的工具调用,即使最后撞了大运把题解出来了,你也可以认为这是一个低质量的轨迹,从而把它扔掉。
- 逻辑冗余度:判断模型是否在反复执行无效的重复操作。
总的来说,拒绝采样的标准设计,本质上就是为数据构建了一套 Reward(奖励)机制,只有高 Reward 的数据才会被留下来用于微调。
Q5:Agent 的 Scaling 是什么意思?
这个我不知道是不是指在 SWE(软件工程)的场景下。如果是指 SWE 场景,我们指的就是整个 SWE 数据管线的 Scaling,也就是通过自动化手段让我们获得更多可以运行的 SWE 环境,以及更多可校验的 Reward(奖励信号),这本质上是数据的 Scaling。
另外,如果是指 RL(强化学习)的 Scaling,它其实是指模型能够在更大的算力规模下持续增长,性能能够平稳地随着训练量提升,且训练过程保持稳定、不崩溃。大概就是这个意思。
Q6:这里分享中提到的“脚手架”是什么意思?
我在整个分享过程中提到的“脚手架”(Scaffold),其实就是指现在的一些 Coding Agent 的运行逻辑,或者你也可以理解为它就是一个 Agent 运行的循环逻辑是什么。
例如,最简单的脚手架就是 ReAct 这种框架:调用工具、观察结果,一直循环到某一次不再调用工具并输出结果为止,这是一个最简单的 Simple Agent 的运行循环。
而现在很多像 Claude Code、OpenCode 等项目,它们会在脚手架中注入很多相对更复杂的功能,包括:
- 上下文管理(Context Management) :如何清理冗余信息。
- 记忆管理(Memory Management):如何长期存储相关信息。
- 工具调用管理:如何处理并发调用或复杂的工具依赖。
- 额外规则:针对特定任务注入的约束或策略。
这些复杂的运行逻辑,我们通称为脚手架。
Q7:general function-call场景的环境合成是怎么做的?(类似于tau/tau2-bench的场景)
对,其实这个问题很好。因为刚刚提到的通用场景我只提到了 WebExplorer,其实 VIBE Explorer 的思路总的来说是可以进一步泛化的。目前学术界也有一些做法,例如你可以基于 Random Walk(随机游走) 去采样出一些轨迹,然后再基于这些轨迹去翻译(Translation)成一些 Query。
在此基础之上,如果我们借鉴 VIBE Explorer 的思想,你其实也可以对最终轨迹的目标增加一些 Evolve(进化) 策略来增加它的难度。
关于这块内容,我们最近还有一篇论文正在撰写中,写完之后也会开源出来。
Q8:请问训练时的沙箱环境是如何设计的,考虑到训练时的高负载/并发场景,且需要不同的代码环境
OK,我们整个沙箱环境是基于 Docker 的,并运行在一个 K8S(Kubernetes) 集群上面。目前我们整体沙箱的并发能力最大能够达到 10 万左右的级别。这里的并发指的是它“同时运行”的数量,当然它“同时启动”的瞬时数量会比这个稍微小一点。
Q9:题目模糊化之后,如何确保答案唯一性,或者确保答案正确性?
OK,这个问题涉及的是 WebExplorer 的工作。
首先,模糊化是在模型已经看过完整轨迹(Trajectory)和所有信息的情况下进行的。在构建数据时,我们会有专门的 Prompt 设计,要求模型在进行模糊化处理时,必须确保核心答案是不变的且具有唯一性。
当然,即使有了这些 Prompt 设计,也无法百分之百保证模型不会改错。针对这一点,我们主要通过拒绝采样(Rejection Sampling)来解决:
1、 预筛选:在进入 RL(强化学习)阶段之前,我们会通过前期的拒绝采样过程,验证模糊化后的题目是否依然可解。
2、 过滤不可解题目:如果一个题目经过模糊化后,连模型多次采样都无法得到正确答案,说明它可能已经变成了不可解的“废题”,我们会直接将其剔除。
虽然这会消耗一定的拒绝采样算力,但它能确保最终进入 RL 训练的数据至少是能够跑通的,从而为模型提供正确的学习信号。
Q10:请问 Agent as Verifier 场景下,交互轮次多导致效率低下的问题是如何解决的?此外,每个开发场景大约需要多少人次交互?
关于交互人次的问题,其实在不同场景下区别很大,这主要取决于工具本身的设计和任务的复杂度。
而对于“交互轮次多、效率低下”的问题,坦率说,目前行业内确实还没有特别完美的解决方案。这主要是因为现阶段模型在 Computer Use(计算机使用,如模拟点击、操作 UI)方面的整体能力还不够强。
不过,一个潜在的优化方向是:当 Computer Use 本身的能力增强后,模型可以更成熟地进行工具的并发调用。如果 Agent 能够一次性、准确地规划并并行执行多个子任务,而不是机械地进行一问一答式的顺序交互,整体的交互轮次就会大幅减少,效率也会得到显著提升。
Q11:Context Management(上下文管理)怎么做?主要是针对 Tool Output(工具输出)还是 Reasoning(推理过程)?
OK,这个主要指的是 BrowsComp(网页搜索评测)中的上下文管理。具体做法在我们 M2.1 的 Hugging Face 评测配置(Config)文件里有详细说明,感兴趣的话可以去翻阅。
简单来说,它会对 Tool Output 和 Reasoning 过程都进行清理。因为在长程的网页浏览中,如果不加干预,上下文会迅速堆积大量的冗余信息(如重复的搜索结果或中间思考过程),这会干扰模型后续的判断。所以我们的逻辑是双管齐下,对这两部分都做精简和管理。
Q12:RL 阶段的数据是否比 SFT 阶段更难、更少?这些数据也是合成的吗?难度如何评价?
首先,关于来源:我们整体上 RL 和 SFT 的数据是比较同源的。这意味着 RL 阶段的大部分数据同样也是通过管线合成出来的。当然,也会包含一部分自然数据,比如非 Agent 场景下的纯 Reasoning 任务(如数学竞赛题 AIME 等),这类数据本身质量很高,并不需要额外合成。
关于难度评价:我们有一个比较自然且高效的做法:在模型完成 SFT 之后,我们会用这个 SFT 后的模型把候选的 RL 数据全部跑一遍,记录它们的 Pass Rate(通过率)。
- 评价标准:Pass Rate 就是最直接的难度指标。
- 为什么这么做:这是一种 On-policy(同分布) 的评价方式。通过 SFT 模型的表现,我们可以精准地筛选出那些“模型目前能解出来、但解得不够稳”或者“刚好处于模型能力边界”的题目。
这种基于 Pass Rate 筛选出的数据,最适合喂给 RL 阶段进行强化,从而通过大量采样和 Reward 反馈,把这些“中高难度”题目的表现从“偶尔能对”提升到“稳如泰山”。
Q13:claude code RL训练前缀合并会出现训推不一致的问题吗
不会出现训推不一致的问题。
因为我们落盘的日志记录的是原始黑盒 Agent 框架的状态,这些日志是在推理服务端(Server 端)直接捕获的。这样我们就能确保记录下的数据一定是模型在推理当时的真实状态。
在进行前缀合并时,我们执行的是完全严格的匹配。并不是说只要第一个 Query 相同就盲目合并。如果只是简单合并,确实会出现顺序或逻辑不一致的问题,因为在实际运行中,Agent 往往会根据策略在达到一定轮次后,清除掉中间的一些工具调用结果或冗余信息。
如果在这种上下文被动态清理过的情况下直接做前缀合并,必然会导致训练数据与推理逻辑的脱节。但由于我们是基于推理端实时请求的“快照”来进行严格合并,所以能完美规避这种不一致性。
Q14:你们做出的agentic能力到具身领域有多大的迁移性,看了你们和维他动力的机器狗视频,agentic能真正作为大脑吗
维他动力的机器狗确实还蛮有意思的。其实那个场景我们是完全没有专门训练过的。
既然我们只是训练了一些相对通用的工具调用能力,它就能泛化到真实的物理具身场景中,这说明我们模型底层的逻辑推理和指令遵循能力具备不错的泛化性。
当然,如果要问现在的模型是否能完全胜任“大脑”的角色,我认为还是存在一些局限性。比如目前的纯文本模型在 多模态理解(Multimodal Understanding)上还需要进一步提升,才能在复杂的现实环境中做出更精准的指挥和决策。
Q15:为什么不去选择GSPO或者GRPO呢?CISPO对于MOE的适配很好吗?是不是如果换了RL算法之后要重构整体的架构呢?
GSPO 也是一个比较同期的工作,GRPO 的话则相对更早一点。我们不用 GRPO 的原因之前也提到过,就是我们最开始在复现 R1-Zero 的时候,用的就是 GRPO,但其实会发现它是复现不出来的。因为它的那个 PPO Clip 机制会导致一些 Token 的梯度消失。
而 GSPO 算是一些偏同期的工作,你可以针对特定场景去做一些选择。在刚才提到的 Meta 那篇论文里面,也对不同方案做了一些比较,那篇论文大家可以再看看。
CISPO 对于 MoE 的适配很好吗?目前我们观察下来,这个层面的算法对于 MoE 还是 Dense 模型来说,差别并不大。
换了 RL 算法之后要重构整体架构吗?按照我们目前的理解是不需要的。它跟整个模型的架构关联不大。当然,MoE 本身在做 RL 时,确实会跟 Dense 模型存在一些差异,比如因为它引入了 Router(路由)。最近好像也有一些方案,比如 R3 这种固定路由的算法去增强 MoE 的稳定性。
但是,这些底层的实现对于更上层的、像 CISP 这种去做 Bias(偏差) 和 Variance(方差)Trade-off 的算法来说,其实没有一个很本质的区别。
Q16:rubrics-based rewards更趋向于「按维度打分」或「具体定义某维度是否完成(True/False)」呢?
这个其实不同的方法我们都有尝试过。从模型最终打分的稳定性上来说,还是去定义一些它能够明确判断的标准(比如 True/False 这种二元判断)会相对更好一些。
Q17:下一版模型有计划继续扩大模型参数吗
这个是有计划的,仍然在我们的整体规划中。
Q18:请问在RL训练MoE模型时有使用expert的路由replay技术吗
OK,这个技术我们也是有关注的,但是目前来说我们暂时没有用到。因为在我们的实验中,还没有出现说因为没用 Replay 就导致模型崩溃、无法解决的现象。当然,这个 Replay 本身从原理上来说肯定是没有问题的,主要还是看一个计算效率上的 Trade-off。
Q19:rubric是怎么生成的呀,人标的吗
Rubric 主要还是得靠人标。在这个地方还是需要有一些专家知识的注入,才能确保打分的准确性和专业性。
Q20:RL 训练的 Reward 有什么建议?
RL 训练的 Reward 核心还是确保它不要被 Hack(奖励作弊)。
其实最近尤其是在 SWE-bench(文中音译为 switch)场景下,大家发现这种现象非常普遍。其实更早的时候就有相关工作提出了,但最近好像又有模型在踩这个坑。
它的 Reward 是被 Hack 掉的:具体表现为模型在执行整个 SWE 任务(如修复 Bug)时,直接去读取了沙盒里没有被删干净的 Commit 信息。模型在环境探索中发现了这些本该属于未来的 Commit 记录,相当于它提前看到了标准答案,然后就直接根据这个信息完成了任务。
所以我理解,设计 Reward 的核心,除了正确性这个大前提外,最关键的就是要确保它不会被 Hack。必须在物理环境和信息链路上做彻底的隔离,防止模型通过这种“偷看答案”的方式来刷高奖励信号。
Q21:请问forge是如何把一个样本的所有llm交互轨迹合并成一条轨迹的?
其实我们并不会把它简单地合并成一条轨迹。
比如在 Multi-agent(多智能体)场景下,如果有多个搜索子任务(Search),那么每个 Search 对应的就是一条独立的轨迹。
在这种情况下,处理逻辑通常有两种:
1、 共享 Reward:你可以认为这多条轨迹共享同一个最终的 Final Reward。只要任务最终成功了,就认为这些轨迹都是对的;反之则都是错的。当然,你也可以针对 Multi-agent RL 做一些更复杂的 Reward 分配设计。
2、训练效率优化(前缀合并):我们提到的“合并”,更多是指将具有相同前缀的采样数据在训练时进行合并处理。
这种合并的核心目的是为了提升整个训练过程的计算效率。通过共享相同前缀的计算结果(KV Cache 等),可以避免重复计算,从而在处理大规模采样数据时显著节省算力。
Q22:agent评测那部分, swe任务里会评估对于工具调用的trajectory么?
其实在你构建 SFT 数据并做具体采样的时候,是可以去做轨迹评估的。这和前面提到的一个问题比较类似。
因为除了最终答案(Ground Truth)的校验之外,你还可以定义一些规则,或者利用 Rubric(评分细则)对轨迹本身的正确性和质量进行校验。
就比如,如果一条轨迹中出现了过多无效的工具调用尝试,或者频繁的工具执行失败,那么即便它最后撞大运得到了正确答案,你其实也可以判定这条轨迹质量不佳,从而直接把它扔掉,不作为高质量的训练数据。
Q23:这个M2.1模型和哪个ai cli或ide配合使用 比较好啊?
从目前社区的很多反馈来看,M2.1 在主流的 Coding 工具上表现都还不错。
具体来说,包括 Claude Code 以及和它同源的一些框架,还有 OpenCode。另外在 Cursor和 Zed这类比较主流的 IDE 或编辑器上,配套使用效果也都很可以。
Q24:Agent RL 与通用 RL 的区别和难点?
这个主要区别在于 Agent 场景需要一个相对多轮的交互。
传统的、通用 Reasoning 的 RL,它其实往往是单轮或者逻辑路径较短的。整体的流程设计会相对简单,包括在环境泛化(Environment Generalization)的设计上,你需要涉及的东西也比较少。
但在 Agent 场景下,它是一个长程多轮交互的过程。这里其实会有一些工程和算法上的“坑”:
1、信用分配(Credit Assignment):在多轮交互中,最终的成功可能取决于中间某一步的关键工具调用。如何将最后的 Reward 准确回传给中间步骤,比单轮推理要难得多。
2、 状态漂移:随着交互轮次增加,环境状态的变化会积累误差。
3、 工程复杂度:Agent 需要频繁与沙盒、API 等外部环境互动,整个训练链路的延迟管理和稳定性要求极高。
Q25:RL 训练完,长上下文容易输出重复内容怎么办?
我理解,长上下文下容易输出重复内容,可能跟你本身整个后训练(Post-training)的数据分布有关系。假如说你后训练数据本身就集中在偏短的情况下,模型到了长上下文场景会比较陌生(Out-of-distribution),就容易输出一些重复的循环。
如果是 RL本身过程中碰到了这些问题,你其实是可以提前去做一些过滤的。就比如说刚才 PPT 里面有提到,你在做的过程中,如果已经因为一些重复的轨迹导致训练不稳定,其实可以算一些 Repeatness(重复率) 相关的量化指标,直接去做过滤就 OK。
Q26:请问 Rubric(评分细则)是算法工程师写的吗?
不尽然是算法工程师写的。就比如说刚才提到的 APP 领域,我们很重要的还是需要 Expert-in-the-loop,也就是说需要相关场景下的研发专家同学来写判定标准。
Q27:现在search agent用了prm嘛?还是就是orm?
现在的社区 Agent 主流还是以 ORM 为主。就比如典型的 BrowsComp(音误为 blosscom)这一类任务。虽然也有一些偏回溯搜索(White search)的尝试,但总的来说,目前还是用最终答案去做校验(Outcome-based)为主。
-AXSE.PNG)