





回顾刚过去的2025年,AI领域最引人注目的范式转移正在悄然发生。
如果说大语言模型的"顿悟时刻"是让机器学会了思考,那么Agent自进化的"镜像时刻",则让AI第一次拥有了"从经验中成长"的能力。
它不再是静态的工具,而是一个能够与环境持续交互、从失败中学习、在任务中迭代策略的数字生命体。
这不是科幻。从Meta FAIR实验室的SPiCE框架到腾讯AI西雅图实验室的R-Zero系统,从上海交通大学的SEAgent到Google DeepMind的Evo-Memory评测体系...
2025年涌现的数十项顶会研究共同指向一个事实:Agent的自我进化,已经从理论猜想走向了技术现实。
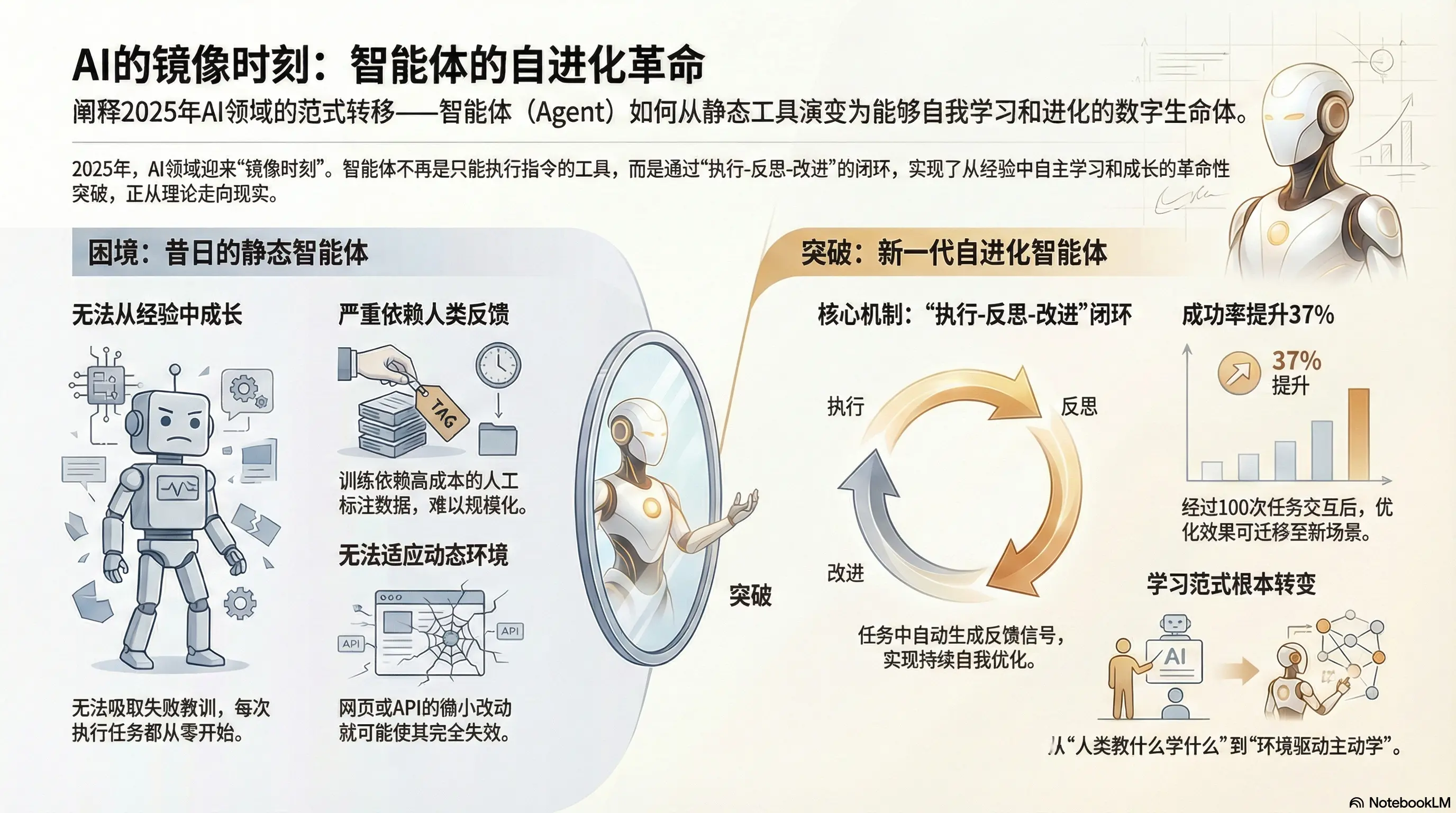
2024年,我们见证了Agent在工具调用、任务规划上的初步成熟。但一个根本性瓶颈始终存在:如何让Agent像人类专家一样,在持续实践中积累经验、优化策略,而非每次都从零开始?
传统方案依赖人类标注的SFT数据或RLHF反馈,成本高昂且难以规模化。更严重的是,静态训练的模型无法适应动态变化的数字环境——网页结构改版、API接口更新、业务流程调整,都会让精心调优的Agent一夜回到解放前。
自进化(Self-Evolving) 正是为破解这一困局而生。它允许Agent在任务执行过程中自动生成反馈信号,通过"执行-反思-改进"的闭环持续优化自身。
根据Meta与俄亥俄州立大学合作的《Agent Learning via Early Experience》研究,这种机制能让Agent在100次任务交互后,成功率提升37%,且优化效果可迁移至全新任务场景。这不仅是性能的提升,更是学习范式的根本转变——从"人类教什么学什么"到"环境驱动主动学"。
但机遇与争议并存。当前学界对“自进化”的理解仍未统一,有人聚焦于模型权重的持续更新,通过任务自举或自奖励强化学习,让 Agent 在真实交互中直接调整参数,实现能力的内生提升;有人则关注记忆与上下文层面的进化,让 Agent 在长期实践中积累、重组和利用经验,而不依赖频繁的权重改动。两种路径如何选择,是否存在融合可能?
AI AMA是由魔搭社区、青稞社区、机智流、知乎联合发起的AI前沿技术对话栏目。每期邀请领域学者、开发者、KOL围绕热点技术主题展开"多视角群聊",以深度对谈的形式,打破信息茧房,拆解技术细节、碰撞前沿观点、探讨落地实践。
AI AMA首期将于 2026 年 2 月 5 日(周四)14:00-15:30,聚焦“Agent自进化”专场,邀请 6位在该领域做出标杆性工作的青年学者,展开一场多视角的深度对谈直播。
青稞
翟云鹏,阿里巴巴通义实验室研究员,魔搭社区AgentEvolver项目负责人,研究兴趣包括: 自我进化的智能体学习系统、复杂场景下的智能体强化学习、大语言模型后训练技术等。24年于北京大学获得计算机博士学位,在AI领域累计发表Top期刊和会议论文二十余篇。
陈兆润,芝加哥大学计算机科学专业博士二年级,Scaling Agent Learning via Experience Synthesis 一作,师从 UIUC 的 Bo Li 教授和 UC Berkeley 的 Dawn Song 教授。他的研究聚焦于约束条件下的 AI 智能体强化学习与自进化,以及智能体安全问题,包括自主化的 red-teaming 与 guardrail 机制设计。其研究成果曾多次发表于 NeurIPS、ICML、ICLR、NAACL、EMNLP 等计算机领域顶级会议,并获得 Oral 与 Spotlight 报告。
黄呈松,圣路易斯华盛顿大学博士生三年级,R-Zero: Self-Evolving Reasoning LLM from Zero Data 一作,本科毕业于复旦大学,研究方向集中于模型自提升,代表作包括LoraHub,R-Zero, Benchmark^2。
刘博,新加坡国立大学计算机科学系博士生,SPICE : Self-Play In Corpus Environments Improves Reasoning 一作,研究兴趣主要集中在强化学习、推理与机器学习系统及其在复杂真实环境中的应用。
近期在Meta FAIR担任Research Scientist Intern,与Jason Weston以及华盛顿大学的Natasha Jaques教授合作,研究大语言模型的可扩展自我改进与自博弈方法,发表了SPIRAL和SPICE系列工作。此前,在DeepSeek担任Student Researcher,参与了DeepSeek-LLM、DeepSeek-V2、DeepSeek-VL和DeepSeek-Prover等基础模型的研发工作。研究目标是探索可扩展的自我改进方法,构建能够在任何未知环境中智能行动的自主决策系统。
在此之前,曾在汪军教授指导下担任研究助理,并有幸与杨耀东老师密切合作。于2020年获得北京大学智能科学与技术专业和经济学专业的双学士学位,师从卢宗青老师。
孙泽一,上海交通大学博士三年级,SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience 一作,研究方向为多摸态LLM强化学习,Agent后训练。以第一/共同第一作者身份在NeurIPS, CVPR, ICCV等学术会议上发表7篇论文。Google scholar citation 700多次,github项目3k+ star。其中SEAgent作为Computer Use Agent的早期自主进化的探索得到学术界较高关注。
张凯,美国俄亥俄州立大学博士四年级,Agent Learning via Early Experience一作,师从苏煜和孙欢教授,研究方向聚焦于数据在基础模型与智能体中的作用。他已在顶级NLP/CV/ML会议发表多篇论文,其中多篇论文获得或入围Best Paper Award(3篇),或者被选为Oral(8次)和Spotlight(3次)。代表作包括MMMU, MagicLens, MagicBrush, Early Experience等。他曾在Microsoft Research、Meta Superintelligence Labs以及Google DeepMind 实习。
直播时间
2026 年 2 月 5 日(周四)14:00-15:30
核心议题
本期圆桌将不设边界地探讨 Agent 自进化的核心逻辑与实践挑战:
- 如何定义“自进化”?其核心判据与理解框架应如何建立?
- 自进化系统真正学到的是什么?能力提升更倾向于环境适应性,还是可泛化的通用策略?
- 关于反馈系统,自进化应该靠什么信号驱动?
- 如何评估自进化的实现程度?是否需要建立新的评价体系与测试场景?
- 不同学习范式(如SFT、RL与训练之外的进化机制)之间应如何协同与定位?
- 具备规划、调用子智能体、文件系统与长程状态等能力的Deep Agent,是否显著增加了自进化的实现难度?
- 在工业实践中,自进化如何被可控地转化为业务价值?
......
互动参与
扫描下方二维码,加入"Agent自进化"专属交流群,欢迎提交想和嘉宾深度互动的问题,我们将抽取5位精彩提问观众,赠送社区精美周边一份
