作者:钱泽中,西安交通大学少年班本科大三
原文:http://xhslink.com/o/4JTOFucqnmw
之前的相关工作
其实从最早期的一派以Q-learning为基础,以及更加倾向于offline RL的真机强化学习算法就可以展现出整个具身社区对RL这一块的态度了,也就是online RL其实并不是最有效的方式。
像比较早期的ConRFT,分了三个阶段,将创新点和工程重心放在了前两个offline阶段,强调在线Rollout是一个收集数据的过程,并且在第三阶段的在线RL引入了人类干预等trick。
以及后续的论文甚至证明了online负责收集数据+offline回放SFT在真机上面的效果大于PPO/GRPO。但是这个时候肯定会有疑问:最近新出的 pi_RL/RLinf仓库把libero的点都刷爆了,还是没有用吗?
pi_RL 鼓舞人心,适合真机吗?
作为一个复现RLinf(pi0.5)并且尝试将它放在真机上的人来说,pi_RL的算法对模拟器来说是非常友好的,但是对于真机来说,我的复现发现以下问题:
1、 相比于模拟器动辄16、64的环境并行,真机上如果想要达到GRPO/PPO的效果,可能要动辄收集30分钟的数据才能训练1个rl step,这样的,这样让很多工作把重心转向了“如何并行化真机RL”,但是我觉得本质上还是不划算的。
2、 “无用数据问题”,在VLA policy失败时,他在一个OOD的情况下做随机探索,此时毫无疑问它的advantage是低的,但是从概率学角度上,PPO/GRPO算法会让OOD的随机布朗运动沿着切线方向的概率减少,本质上是把一个正向的布朗运动变成了反向布朗运动,可能是有效,但是得堆数据,非常低效。
所以这一套在仿真器上可以接受,因为模拟资源是冗余的,但是如果在真机上,可能就需要接受“30min数据只有5min对提升成功率有用”的问题。
3、 “假探索”,基于Diffusion/Flow Matching Actor的算法为了搞出一个动作概率来,使用了flow-noise和flow-sde来向轨迹去噪过程额外加噪,但是这样的行为不能导致“模型偶然想到一个别的偏好并且尝试”,只会导致“在原来的轨迹上多了一些抖动”。
其实可以理解到原本算法设计者的思想,觉得diffusion/flow matching在解决例如推T块任务下面有比较强的多峰分布,想通过高噪期间的额外噪声引诱噪声空间分布的"温度"随之提升,但是实际上在绝大多数task下面,多峰分布导致的成功率差异是不存在的,导致任务失败的原因往往是"bias问题"。
也就是可能模型夹某一个东西的时候会固定往左/往右偏移,或者干脆找不到这个东西(语义层面崩塌),或者OOD场景下无法恢复,一直乱动。而bias问题通过这样方式的解决效率是极低的。
具身智能 v.s. LLM
为什么GRPO/PPO可以在LLM里面获得良好的效果呢?
1、 LLM作为一个next-token-prediction,有显式的概率分布,并且对于LLM优化问题,往往是“多峰分布偏好选择”,这一点从模型架构/分布建模上就明显优于pi系列的噪声流形建模(对于GRPO/PPO算法)。
2、 LLM的rollout是高度并行、廉价的,可以用多张卡同时进行推理,这个比较像libero这种模拟器,但是对于具身RL来说,一放到真机上面就很难以满足这个条件。
3、 (extra):LLM的介入是很贵的,如果要由人类来纠正的话,需要人类手敲上千字的“ref action”,但是对于真机RL来说,本身就需要有个人守在旁边,介入也只需要按照高效数采(主从臂、VR等)的方式进行打断+遥操。
所以假如LLM领域人类纠正很便宜的话,可能现在整个LLM领域的强化学习算法也会截然不同了。所以对于真机来说,照抄LLM领域算法是不合算的。
性价比之王:critic-guided-offlineRL + 人类介入
回到一开始那篇论文,证明了利用online探索的数据进行offline SFT效果更好的那个,其实做的很朴素:
只按照traj-level的颗粒度进行了数据集筛选,但是在长程任务上,这样其实也是低效的,一个长的轨迹rollout过程中可能一些动作是“好的,该学的”,一些动作是“不好的,要被筛选掉的”,那么像经典的算法就会训练一个critic(tip:一般是训练value分布而不是回归),然后精细化筛选“该学的数据”,像pi*0.6的RECAP,则是通过一个标志位的方式也尝试去学习“不好的(Advantage<x)”的数据。
以及Kai0,通过一些方案来对齐收集的数据和遥操作的数据集,并且在“数据混合”上面下了一些功夫。
.webp)
那么对于人类介入来说,前文从性价比上面来谈论了为什么人类介入在真机RL是高效的,那么如何做?目前比较火的有那么几种方法:
1、 Offline-RL based,RECAP(pi*0.6),把人类介入标记为high advantage,GR-RL在此基础上对人类示范数据也进行了advantage标注,只学习好的部分。
2、 HG-DAgger(DAgger以及其衍生),在快失败时人类介入完成轨迹,做SFT;或者不纠正到完成任务,只纠正到In Domain的state
(欢迎补充更多的)
迈向工程化:该并行的不是GRPO/PPO,而是离线学习算法
其实激发我写这一篇文章是智元最近偏工程向的一篇工作SOP。
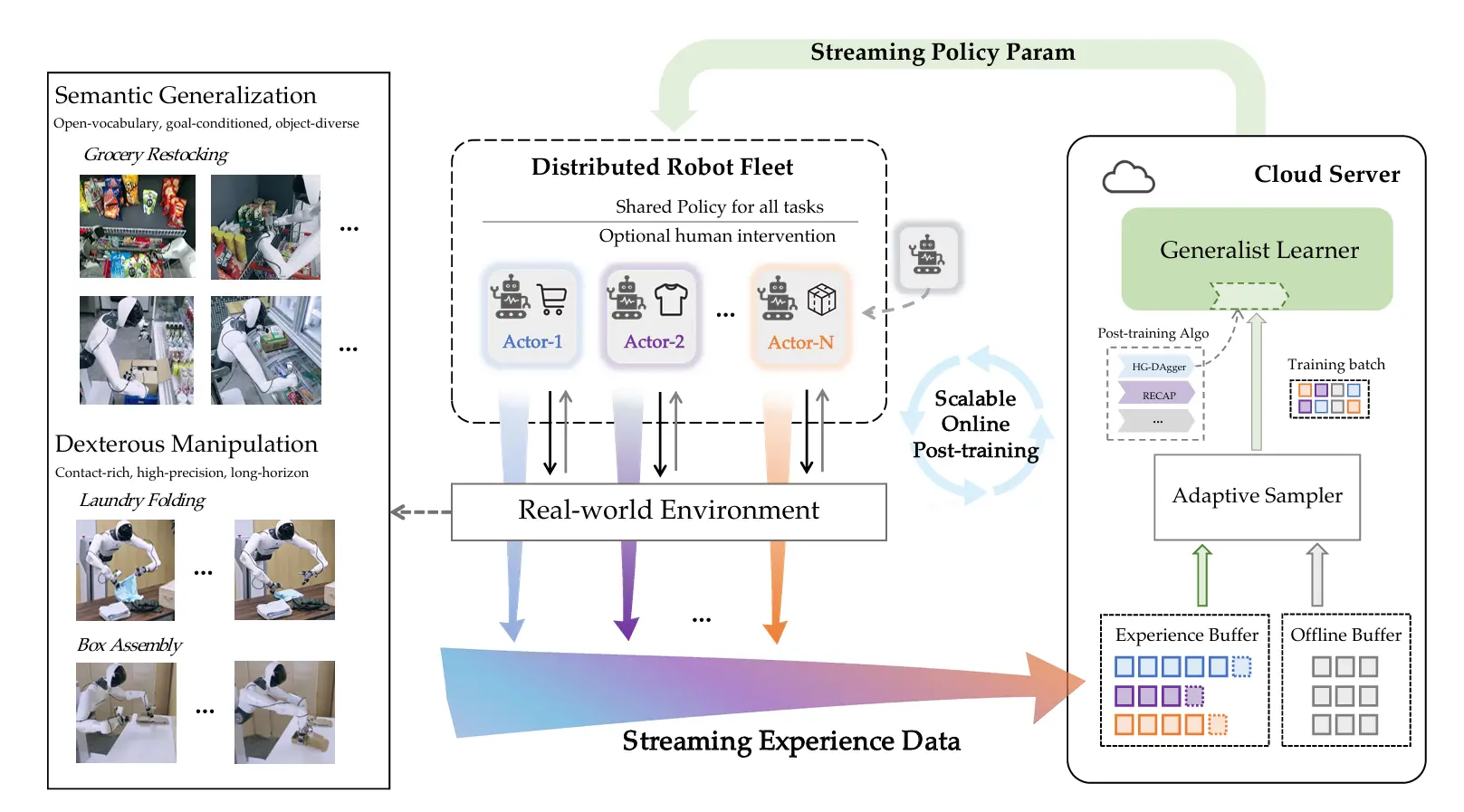
相比于之前争相着想把GRPO/PPO堆量堆并行的工作来说,我觉得SOP至少是找到了真机RL该走的路,然后通过并行部署的方式来探索这一方案的极致。