
在大型语言模型(LLM)的强化学习(RL)阶段,特别是人类反馈强化学习(RLHF)中,我们追求策略 \pi_\theta 的持续优化。
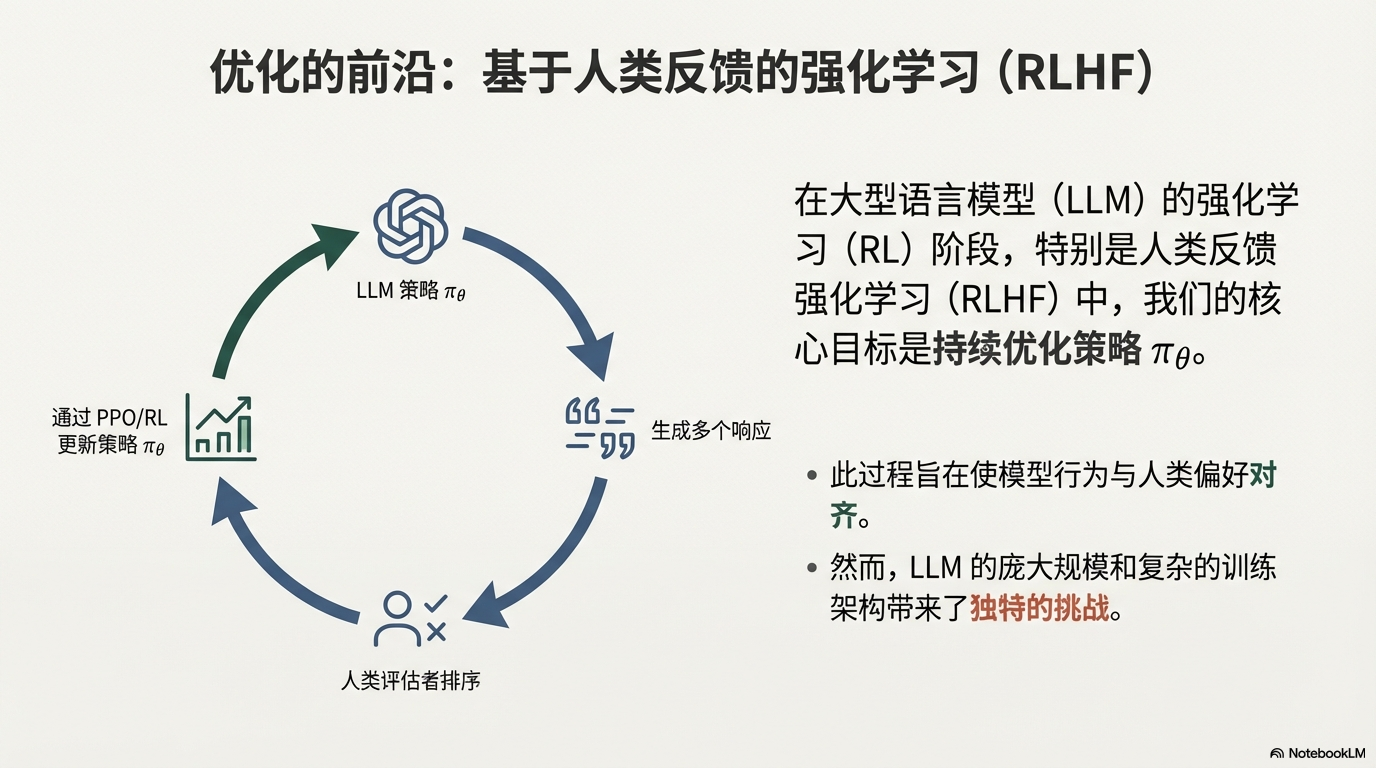
然而,LLM 的复杂性和分布式训练特性,带来了一系列独特挑战,这些挑战在数学上可以统一归结为一个核心问题:策略部署(rollout)与策略更新(\pi_\theta)之间存在不匹配,即 \pi_\text{rollout} \neq \pi_\theta。

这种策略差异是典型的 Off-Policy 现象,具体表现在以下几个方面:
1、训练-推理不匹配 (Deployment Mismatch)
在 LLM 的部署环境中,训练使用的浮点精度(如 FP32/BF16)、后端库(Backend)和硬件内核(Kernel)往往与实际推理环境存在差异。

这导致即使参数 \theta 相同,在不同环境下的实际策略 \pi_\text{rollout} 也会与理论策略 \pi_\theta 产生偏离。
2、MoE 路由不稳定 (MoE Routing Instability)
对于采用专家混合(MoE)架构的 LLM,其路由(Router)通常采用 Top-K 离散选择机制。
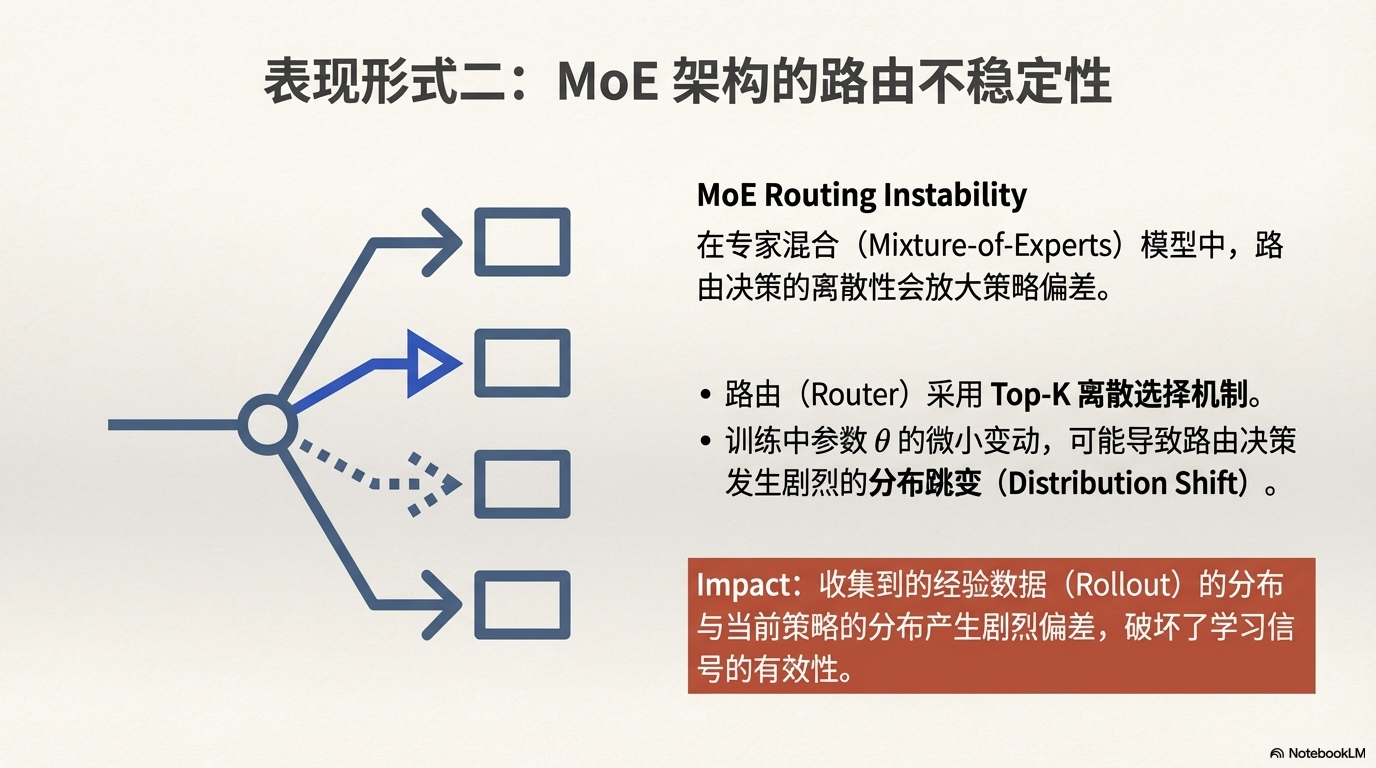
在训练过程中,参数的微小变动可能导致路由决策产生分布跳变(Distribution Shift),使得收集到的经验数据(Rollout)的分布与当前策略的分布产生剧烈偏差。
3、异步训练的时序偏差 (Stale Rollout)
在分布式和异步训练系统中,经验数据的收集(Rollout)与策略的参数更新通常不同步。

当 Rollout 数据返回给学习器时,策略参数 \theta 可能已经经过了多次更新(n \to n+k),导致经验数据是基于一个 过时(stale) 的策略生成的。
为了解决 Off-Policy 带来的策略不稳定问题,信任域策略优化(TRPO)理论提供了核心的解决方案框架。

TRPO 的核心洞察是:必须保证新策略 \pi_{\theta'} 相对于旧策略 \pi_\theta 的改进是可信赖的。它通过引入一个代理目标函数来近似策略的性能提升,并同时施加一个至关重要的信任域约束。

该约束通常使用 KL 散度来限制新旧策略之间的距离,确保更新幅度始终在一个预设的阈值内:\mathbb{E}_t [D_{KL}(\pi_{\theta} || \pi_{\theta'})] \le \delta。
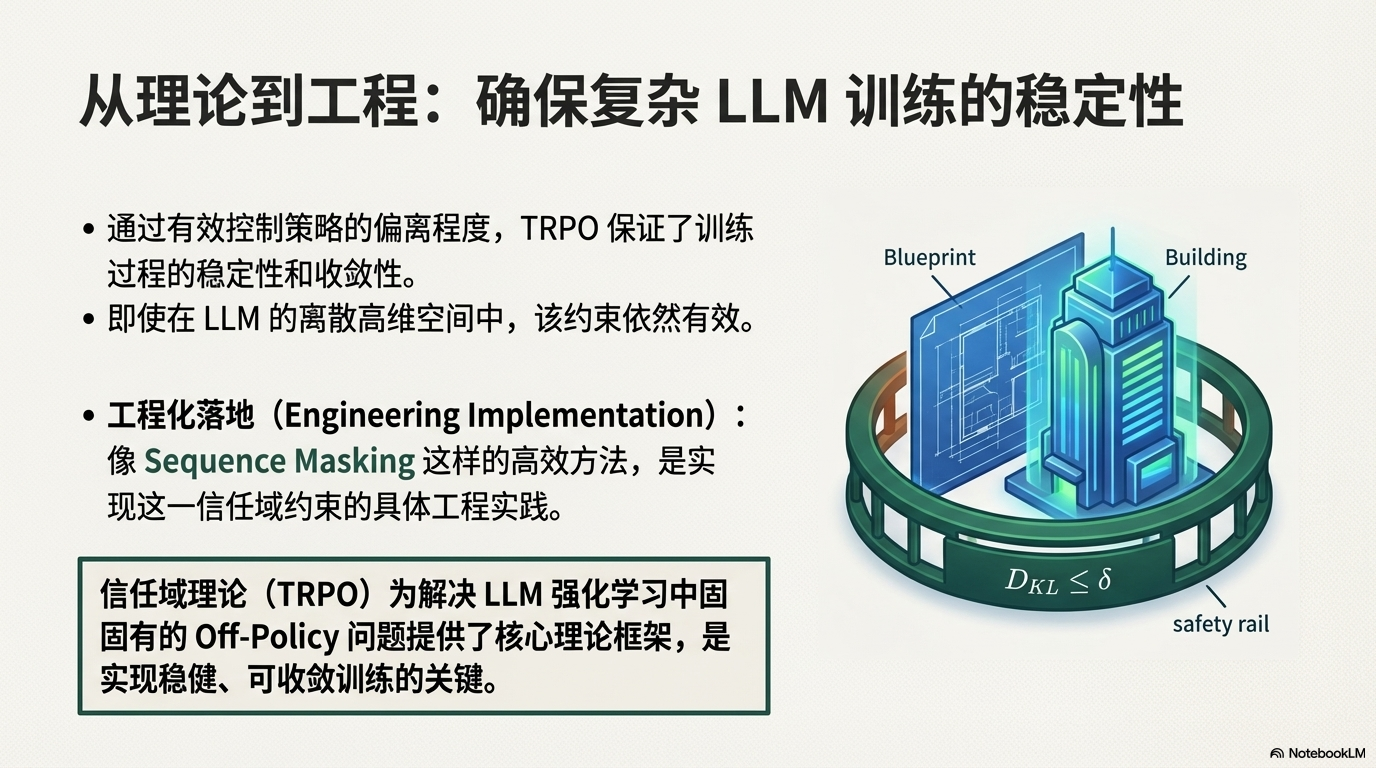
通过这种方式,TRPO 能够有效控制策略的偏离程度,即便在复杂的 LLM 离散高维空间中,也能保证训练过程的稳定性和收敛性,而基于 Sequence Masking 等高效方法则进一步实现了这一信任域约束的工程化落地。
12月20日上午10点,青稞Talk 99期,青稞社区邀请到某大厂研究科学家Yingru Li,来直播分享《TRPO 重生:大模型时代的信任域策略优化》。
主题提纲
TRPO重生:大模型时代的信任域策略优化
1、大模型RL特有的Off-Policy挑战
2、TRPO理论基础:代理目标与信任域
3、基于序列掩码的信任域优化
4、AMA (Ask Me Anything)环节
直播时间
12月20日(周六)10:00 - 11:00