生成式视频模型正以前所未有的速度进化,从数秒短片拓展至长时段叙事,从模糊低清跃升至逼真4K。然而,随着视频时长和空间分辨率的提升,序列长度急剧增加,二次复杂度的注意力计算量随之飙升,即便采用 FlashAttention 等高效优化,推理延时仍然难以遏制。以生成一段 720p、5 秒的视频为例,单是注意力计算就需要耗时数十分钟。炫目的生成质量因此被漫长的等待所拖累,限制了真实应用的落地。
为此,中科院自动化所研究团队提出了Rectified SpaAttn校正式稀疏注意力,它从理论上揭示了传统稀疏注意力存在的系统性偏差,并据此构建出一种更快、更稳的稀疏注意力新范式。通过校正稀疏注意力,使其分布更贴近真实注意力,Rectified SpaAttn能在更高稀疏率下依然保持卓越的生成质量,将视频生成中注意力稀疏化加速的潜能进一步推向极限。

论文地址:https://arxiv.org/abs/2511.19835
项目地址:https://github.com/BienLuky/Rectified-SpaAttn
为什么稀疏注意力做不好?不是“不够精确”,而是“存在偏差”
为了加速注意力计算,稀疏注意力通常只保留少量关键 tokens 的运算,忽略大部分非关键 tokens,以此降低计算量。为了让稀疏注意力更接近真实注意力,传统方法大多从重排序或重要性评估入手,力图更精准地挑选应当保留的关键 tokens,从而最大化信息保留。然而,理论分析表明,这类以“精确选择”为核心的稀疏注意力方法存在两类系统性偏差,如下图所示。
- 关键 tokens 的注意力被系统性放大:稀疏后 softmax 只在少量被保留的 tokens 上归一化,相比真实注意力,这些关键 tokens 的权重被显著推高。
- 非关键 tokens 的注意力完全丢失:未被保留的 tokens 不再参与任何计算,其注意力贡献被彻底抹除。

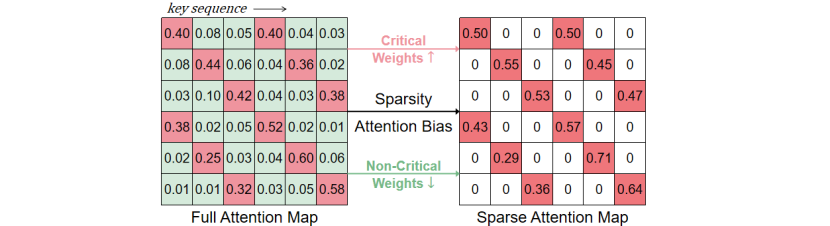
更重要的是,随着稀疏率提高,这两种偏差都会进一步加剧。因此,即便传统稀疏注意力方法在挑选重要 tokens 方面再精确,它们仍然难以在高稀疏率下保持生成质量。
Rectified SpaAttn:不是“精确选择”,而是“偏差校正”
研究团队提出了一个关键洞察:对均匀池化后的 Q 和 K 进行注意力计算,可得到一种“隐式全注意力”,其分布与真实全注意力高度一致。基于这一发现,Rectified SpaAttn 并不再执着于挑选哪些 tokens 更重要,而是以“隐式全注意力”为参考,对稀疏注意力进行系统校正,让其分布重新对齐真实注意力,如下图所示。
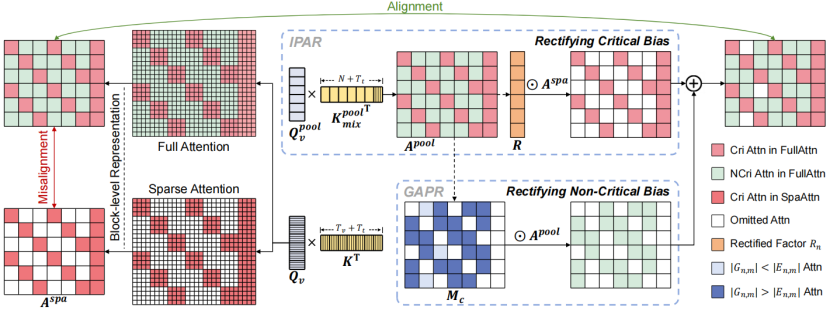 隔离池化的注意力重分配: 理论推导表明,关键 tokens 在稀疏注意力中出现的偏差,与其在真实全注意力中的权重总和严格成正比。因此,可以通过“隐式全注意力”估计这一权重和,从而对偏差进行有效校正。然而,由于文本 tokens 缺乏块内同质性,直接对完整序列的 Q 和 K 进行池化,会导致“隐式全注意力”产生显著误差。
隔离池化的注意力重分配: 理论推导表明,关键 tokens 在稀疏注意力中出现的偏差,与其在真实全注意力中的权重总和严格成正比。因此,可以通过“隐式全注意力”估计这一权重和,从而对偏差进行有效校正。然而,由于文本 tokens 缺乏块内同质性,直接对完整序列的 Q 和 K 进行池化,会导致“隐式全注意力”产生显著误差。
为此,研究者提出隔离池化的注意力重分配(IPAR):
① 隔离文本 tokens,仅对视觉 tokens 进行池化,得到混合粒度的池化注意力;
② 根据粒度差异进行重加权与归一化,重构与真实注意力高度一致的“隐式全注意力”。
以此确保关键 tokens 的注意力偏差能够被准确校正。
收益感知的池化校正: 池化得到的“隐式全注意力”只具备块粒度的信息,用它来近似非关键 tokens 的 token 粒度注意力权重,既会带来注意力信息收益,也会引入块池化带来的近似误差。因此,盲目的使用“隐式全注意力”对所有非关键tokens进行补偿,可能导致校正不稳定甚至失效。
为此,研究者提出收益感知的池化校正(GAPR):
① 分别建模校正带来的注意力收益与池化误差,在块维度上对两者进行量化估计;
② 设定校正条件,仅当补偿收益大于近似误差时,才对对应的非关键 token 块执行校正。
以此确保对非关键 tokens 的注意力偏差校正既可靠又稳健。
整体效果:更快、更稳
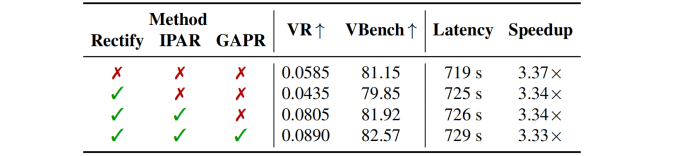
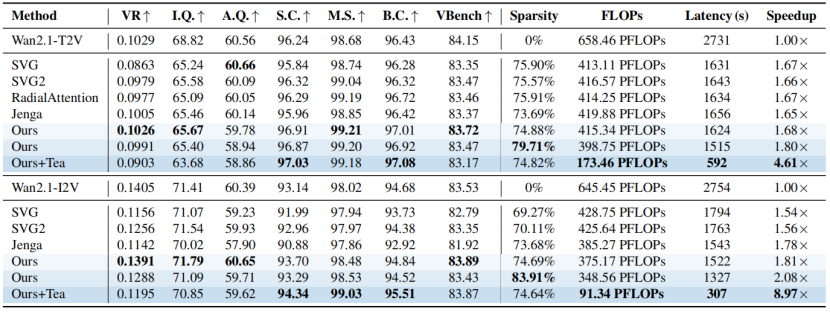
对比实验: 下表显示了在视频生成模型 HunyuanVideo 和 Wan 2.1 上的评估结果,相较当前 SoTA 的传统稀疏注意力方法,Rectified SpaAttn 能在更高稀疏率下依然保持更优的视觉质量。同时,与模型缓存技术结合,Rectified SpaAttn 能进一步实现 4–9 倍的端到端加速,在加速与性能之间取得双重突破。


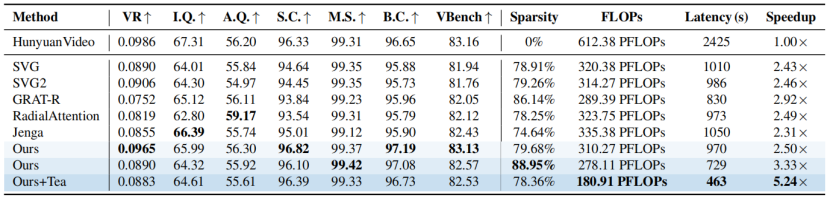
消融实验: 在 HunyuanVideo 上的消融结果表明,使用直接池化得到的“隐式全注意力”对所有 tokens 进行盲目校正,不仅无法提升性能,反而因错误校正导致生成质量下降。相比之下,引入 IPAR 与 GAPR 后,对关键与非关键 tokens 进行分别、精准的偏差校正,模型性能显著提升。此外,由于校正操作均基于池化张量完成,额外开销极小,因而在提升质量的同时,依然保持了高稀疏加速效率。