在通往AGI的道路上,世界模型(World Model)被视为让AI真正理解并预测物理世界的关键拼图。英伟达近期重磅发布的世界动作模型(WAM)DreamZero 一经发布就在两项机器人基准测试RoboArena,MolmoSpaces上双双登顶,在具身智能领域获得极大关注。
与传统VLA等模型不同,WAM将视频这一具备完整时空信息的载体当作自己的核心学习材料,并以一种“先理解世界如何变化,再决定自己如何行动”的模式,使模型天然获得互联网视频所蕴含的海量物理经验。
它不再需要大量重复演示来学习单一动作,而是能从多样化的数据中学习世界的物理规律,从而在从未见过的环境和任务中依然保持稳定执行能力。
| VLA模型 π0.5 | DreamZero世界模型 | 效果 | |
|---|---|---|---|
| 在见过任务中的成功率 | 27.4% | 62.2% | 更高的成功率 |
| 在未见过任务中Zeroshot的成功率 | 16.3% | 39.5% | 更强的任务泛化性 |
| 下游任务Post-training后的成功率 | 79.8% | 90.5% | 更强的后训练微调能力 |
| 跨真机本体的迁移效果 | - | 仅需30min新本体数据 | 更强的跨本体泛化性 |
当前最优的VLA模型与DreamZero世界模型在任务成功率、泛化性、跨本体等方面的直观对比
上面的表格直观的展示出 DreamZero 模型相比开源最优的 VLA 模型 π0.5,在任务成功率、任务泛化性、后训练对成功率的提升效果、以及跨真机本体的泛化性等方面具有明显的优势,实现了超过 2x 的成功率提升。它的范式革新不仅大幅降低了学习成本,也让机器人的形态适配与技能拓展不再受限于大量专属数据,为多机型协同、快速部署与低成本迭代提供了可行路径。
然而,以 Diffusion 架构为主体的 WAM 多模态模型,也给算力和显存带来了巨大的挑战。参考官方开源的 DreamZero 训练代码,采用 8 台 H100 训练 24750 万帧数据,完整训练周期长达 25 天,高昂的训练成本和耗时成为行业复现的主要门槛。
为助力前沿研究更高效地落地,无问芯穹与清华大学等联合推出的大规模强化学习框架RLinf 已正式上线了对 DreamZero 训练的深度支持。在实现功能适配的基础之上更进一步,依托 RLinf 强大的底层系统优化能力,对 DreamZero 的训练管线进行了深度的重构与加速。相比 DreamZero 官方提供的基线训练脚本,RLinf 成功实现了近 4 倍的训练吞吐加速,且具有更好的收敛效果。
RLinf 是如何极致榨干 GPU 的每一滴算力,达成 4 倍训练加速的?接下来将为您一文拆解背后的核心优化思路与逻辑。
代码链接:https://github.com/RLinf/RLinf
Hugging Face链接:https://huggingface.co/RLinf
使用文档链接:https://rlinf.readthedocs.io/zh-cn/latest/rst\_source/examples/embodied/sft\_dreamzero.html
01 核心揭秘:近 4 倍加速背后的 3 大优化维度
为了打破官方脚本的性能瓶颈,RLinf 系统优化团队从计算图、FSDP2并行优化与全局参数调优、数据处理管线进行了深度优化。
.png)
极致的算子/计算图优化:Torch Compile + CUDA Graph
Python层面的算子与调度开销往往是限制GPU峰值性能的“隐形杀手”。在 RLinf中,我们深度融合了 torch.compile和 CUDA Graph 技术:
- Torch Compile:通过底层编译优化,对算子进行深度融合(Kernel Fusion),包括 WanRMSNorm、adaLN-zero 等 Diffusion 架构中的低效算子。
- CUDA Graph:将计算图固化,消除GPU launch的CPU调度瓶颈,在DreamZero的训练中,CausalWanSelfAttention部分的kernel launch较为密集,CUDA Graph 可以做到有效优化。
通过该项优化技术,DreamZero 5B 和 14B 模型在不改变原有mbs=1(此处 mbs 指 mbs per gpu,下同)的配置下分别获得 50%(从1.8s/step降到1.2s/step)和 34%(从9s/step降到6.7s/step)的训练加速。
计算与显存的联合优化:解锁全方位性能调优
支持任意 Microbatch Size、并行方式的参数调优以及Recompute(激活重计算),是业界训练大模型时必不可少的性能调优手段。然而,在DreamZero官方的 baseline中,存在着明显的工程局限,例如默认使用DeepSpeed的zero2 offload并行方法、image encoder不拼batch 逐样本执行等,大大降低了性能的调优空间。
RLinf团队从底层夯实了工程底座,彻底修复了这些痛点,交付了一套健壮且高度可配的调优矩阵:
稳定适配FSDP2:FSDP2是 PyTorch官方团队推出的最新ZeRO实现,也是RLinf面向中等规模大模型的默认并行方案。此前,在DreamZero官方代码中使用的DeepSpeed方案存在一定的局限性:由于 ZeRO3与VAE模块中causal conv的上下文维护机制存在兼容性冲突,开发者往往被迫回退至性能较低的ZeRO2 offload模式。
此外,DeepSpeed在反向传播阶段的 post backward hook 产生了较高的 CPU 侧开销,制约了整体训练吞吐。通过向 FSDP2 训练后端的迁移,我们彻底解决了上述架构冲突与性能瓶颈。用户现在可以根据显存配置需求,在不同的分片策略间灵活切换,确保训练过程的高效与稳定。
灵活的 Microbatch 设置:在 FSDP2 支持 DreamZero 模型训练的初始版本中,Microbatch Size (mbs)、Recompute(激活重计算)与 FSDP2 的策略组合往往会触发复杂的底层计算图冲突,而且 image encoder 不拼 batch 会吞掉一部分开大 mbs 的加速收益。RLinf 通过工程上的努力,彻底解决了 mbs > 1 时与上述特性共存的不兼容问题,并且使得 image encoder 能够高效地拼 batch 执行。
这一改进使训练系统具备了更高的灵活性:用户可以不受约束地配置任意 mbs,从而根据硬件资源的显存水位与计算吞吐需求,进行精细化的参数调优,在显存占用与执行效率之间达成更优的工程平衡。
举例来说,对 DreamZero 5B 模型的训练,在不开启 Recompute 的情况下,mbs 开到2,相比于原来的 mbs 只能开到1,单步耗时几乎没有变化,1.2s/step 变到 1.3s/step,吞吐增加 85%。
Recompute机制与加速算子的深度协同:针对 PyTorch 原生框架在复杂并行策略下的兼容性局限,RLinf 通过深度的底层工程优化,实现了 Recompute(激活重计算)与 CUDA Graph、FSDP2 的稳定解耦与协同。这一改进将 Recompute 转化为一个高可靠、可量化的性能调优维度。
在显存受限的硬件环境下,系统能够以微小的计算耗时为代价,换取显著的显存空间释放,从而支持更大规模的并行任务,大幅提升整体训练吞吐。
在DreamZero 5B的训练中,在不开启 Recompute 情况下,单卡mbs只能开到2,最佳速度约 1.2s/step,即1.7samples/sec/gpu,有 Recompute 情况下,单卡mbs开到32可获得7.2 s/step,即 4.4 samples/sec/gpu,同等算力下吞吐提升 158%。可以看到,开启 Recompute 使 mbs 得以大幅增加,从而大大提升算子效率。
通过以上FSDP2、mbs、Recompute 的全局参数调优,在 DreamZero 5B 模型训练上,我们在第一项算子优化的基础上(即 1.2 samples/sec/gpu)将训练性能进一步提升了 266%,达到 4.4 samples/sec/gpu。
突破 I/O 吞吐瓶颈:高效视频数据处理管线
随着计算密度(即上述两项优化)的显著提升,数据加载效率逐渐成为制约整体训练吞吐的新瓶颈。在 DreamZero 的训练实践中,视频数据的解码与预处理过程极其消耗 CPU 资源。
传统的方案(如 PyAV)在解码性能上难以支撑高频的吞吐需求;而单纯通过增加 dataset的 num_workers 来尝试“通过数量换速度”往往治标不治本——过多的数据读取进程会剧烈抢占 CPU 资源,进而导致训练主线程的内核下发(Kernel Launch)出现延迟,反而拖慢了 GPU 的执行节奏。
为了在“解码速度”与“系统资源开销”之间寻找最优解,RLinf 团队对主流的视频处理库进行了深度的性能 Benchmark:
| 解码方案 | 单视频平均解码耗时 | 系统资源占用(CPU/Mem) |
|---|---|---|
| PyAV | 816 ms | 较高(资源消耗多但很慢) |
| Decord | 435 ms | 高(瞬时负载波动大) |
| Torchcodec | 446 ms | 低(资源消耗曲线平稳) |
虽然 Decord 在纯解码速度上略胜一筹,但 Torchcodec 在保持同梯队性能的同时,表现出了更优的 CPU 占用稳定性。这使得我们能够预留出足够的计算余量给训练主线程,并支持开启更多的 num_workers 来并发处理数据。
相比原生的 PyAV 方案,单个视频的解码时间缩短了近 400ms。在 DreamZero 多视角(左视角、右视角、腕部视角三个视频)的训练场景下,视频解码时间累计节省了 1.2s。这一 I/O 端的性能提升,为后续进一步压榨 GPU 计算潜力提供了充足的数据“弹药”。
02 性能实测:从“能跑通”到“极致高效”的端到端跃迁
为了验证上述多维优化的综合成效,我们在 Droid 数据集(单样本含左、右、腕部三个视角,视频规格33\text{frames}\times480\times640)上,对DreamZero不同规模的模型进行了严格的端到端测试。
DreamZero-14B:大参数量下的吞吐飞跃
在 14B 大模型上,由于显存压力巨大,官方基线通常被迫采用 DeepSpeed ZeRO-offload 方案,这导致了严重的计算/通信浪费与CPU换入换出开销。
在14B 模型上,RLinf 相比原生 DeepSpeed 方案实现了2.7倍的加速;即便相比于未经优化的 FSDP2,吞吐量也进一步提升了 35%。
DreamZero-5B:算力密度的极致压榨
对于5B中等规模模型,RLinf 的优势在于能够通过高效率的重计算逻辑稳定开启更大的 Microbatch Size (mbs),并配合其他计算图调优,彻底释放GPU算力。通过 RLinf调优,训练吞吐从官方代码的1.1 samples/sec/gpu飙升至 4.44 samples/sec/gpu,相比于有诸多限制的 FSDP2 Base 更是实现了惊人的 5.84 倍 性能飞跃。
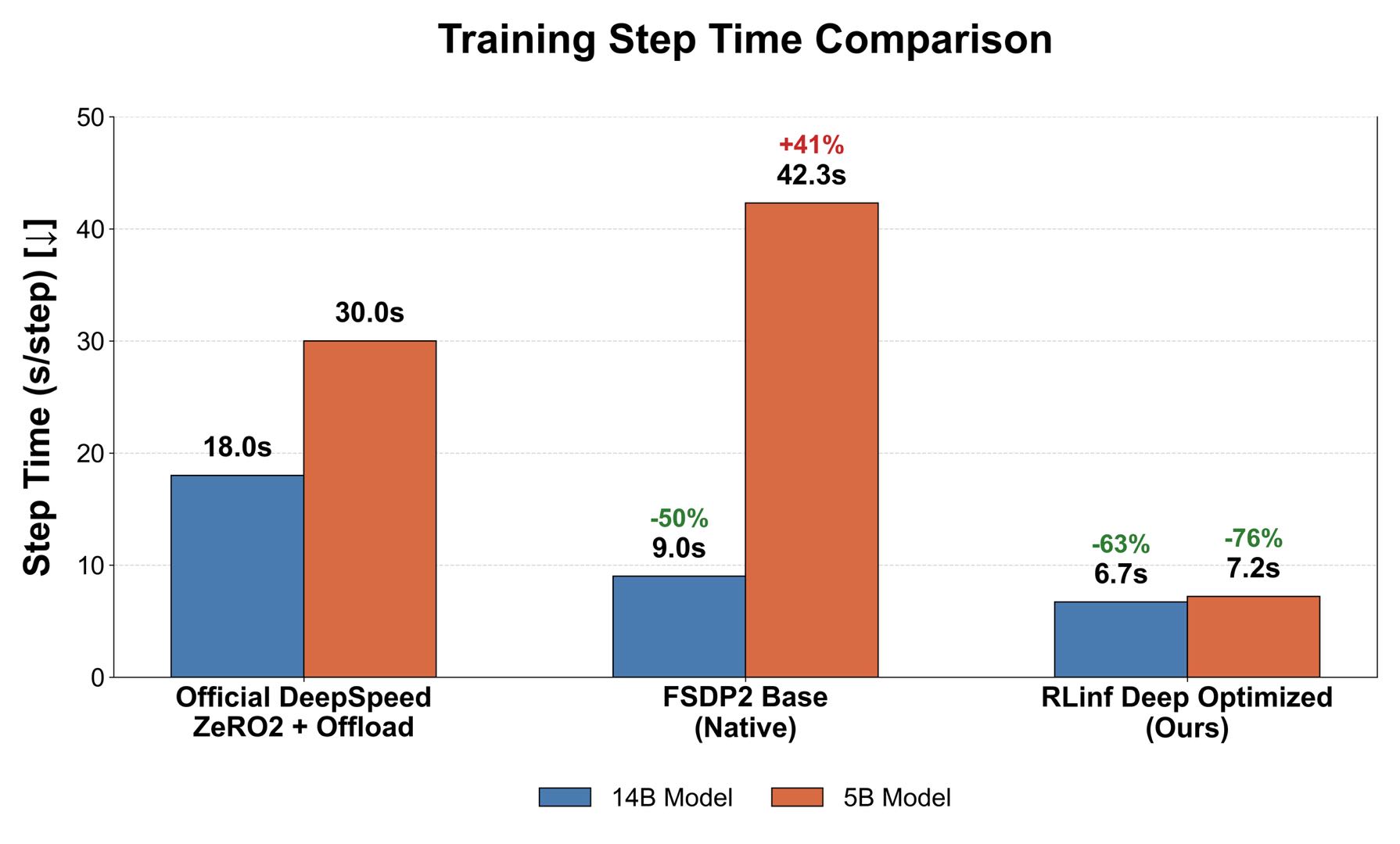
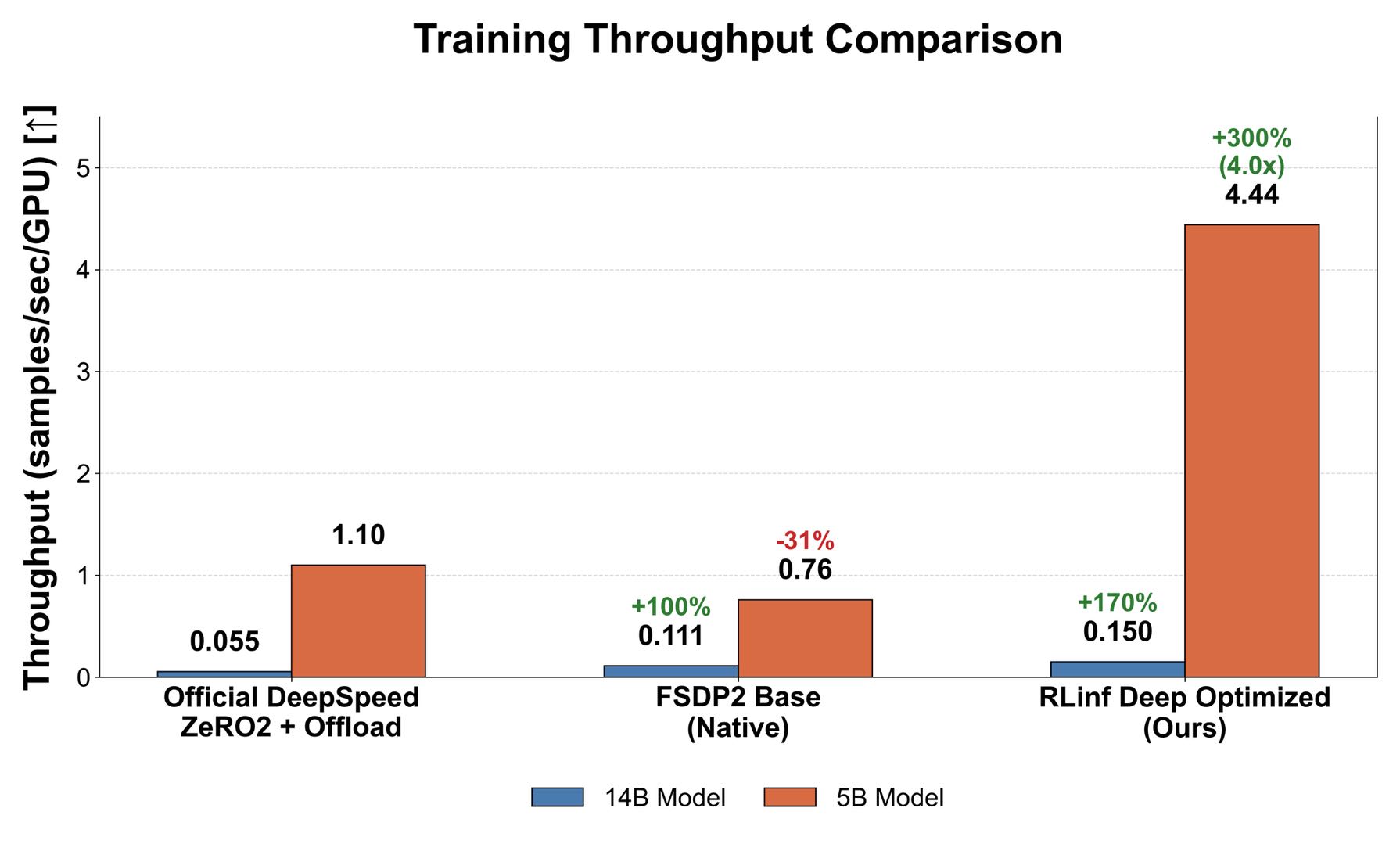
FSDP2 Base版本由于一些PyTorch的bug不能开大MBS,导致吞吐受限,这主要是因为小MBS下算子效率不高、CPU开销显著以及FSDP2通信不能被掩盖;我们解决了这些问题,并且取得了较大的吞吐增长。
训练收敛效果测试:追求速度,更要保证精度
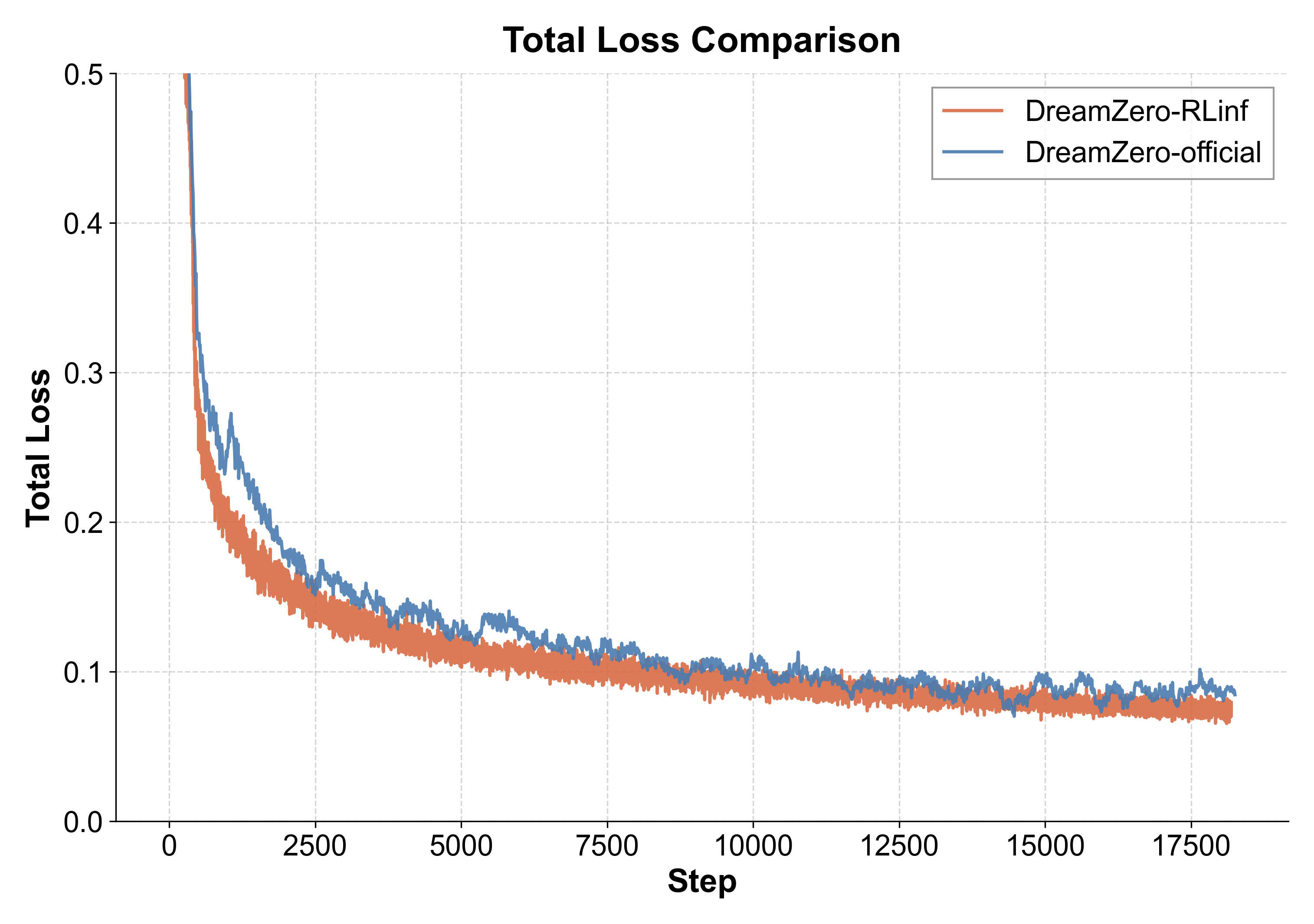
在极致的性能优化之外,确保训练的正确性与收敛稳定性是框架落地的基石。我们对 RLinf 版本的DreamZero进行了严格的收敛性验证。下图展示了DreamZero 5B模型在LIBERO数据集上的Loss曲线对比(配置:LR = 1e-5,Global Batch Size = 256,8卡H100,训练38小时)。
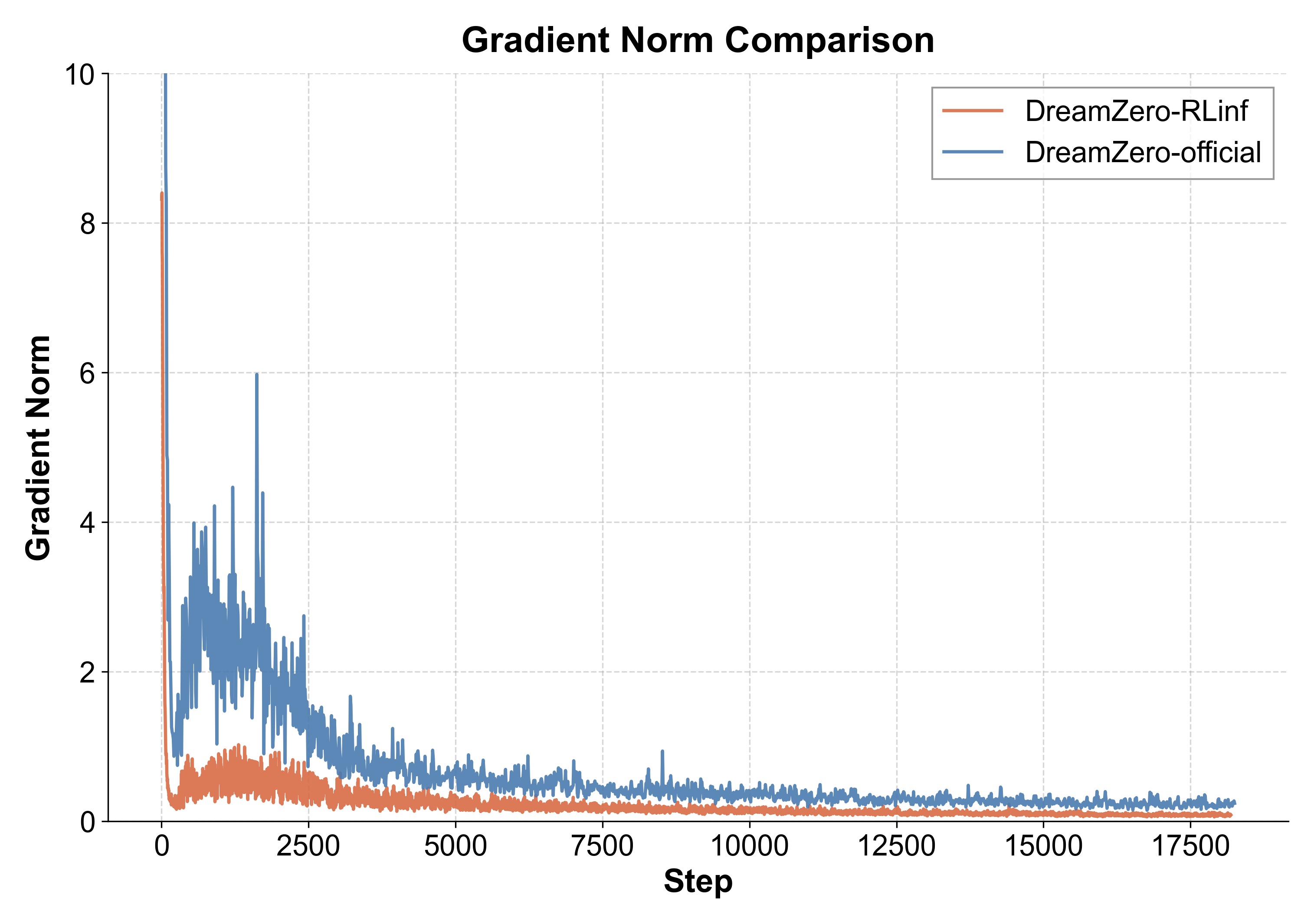
Loss 曲线对比分析:图中橙线(RLinf)与蓝线(官方 Baseline)呈现一致的收敛趋势。值得注意的是,官方代码在训练过程中 Loss 波动较为剧烈,这源于其以 Episode 为粒度进行数据读取;而 RLinf 通过底层重构,实现了 Episode 内部的 Step 粒度随机采样,有效平滑了训练过程中的噪声,提升了梯度更新的稳定性。
.png)
.png)
为了进一步验证性能优化的有效性,我们对 RLinf 训练的9k到21k Step 的 Checkpoint 在 LIBERO 仿真器的 Spatial Benchmark 上进行了端到端测评(每个 Checkpoint 执行 512 条轨迹,单 Episode 最大长度 480 步),具体成功率如下表所示:
| step 9k | step 12k | step 15k | step 18k | step 21k | |
|---|---|---|---|---|---|
| 成功率 | 89.06% | 88.48% | 66.60% | 96.68% | 90.43% |
实验结果显示,模型在 18k Step 处达到了最优的 96.68% 成功率,证明 RLinf 在大幅缩短训练耗时的同时,完全保持了模型原有的训练效果与收敛质量。
模型权重获取:https://huggingface.co/RLinf/RLinf-DreamZero-WAN2.2-5B-LIBERO-SFT-Step18000
03 总结:让世界模型迭代跑在“快车道”
从算子融合到 I/O 调优,从并行策略的纠偏到 mbs 自由度的释放,RLinf 对 DreamZero 的深度支持并非简单的参数微调,而是系统级的重构。
近 4 倍的吞吐提升,意味着算法研究人员在同等硬件资源下,可以将原本需要 1 个月的实验缩短至 1 周内完成。 RLinf 不仅仅是一个工具库,更是具身智能领域高效迭代的加速器。
想要亲身感受 4 倍提速的强大效能? 欢迎使用 RLinf 工具,开启您的 DreamZero 世界模型训练加速之旅!
代码链接:https://github.com/RLinf/RLinf
Hugging Face链接:https://huggingface.co/RLinf
使用文档链接:https://rlinf.readthedocs.io/zh-cn/latest/rst\_source/examples/embodied/sft\_dreamzero.html
若大家在使用 RLinf 时遇到任何问题与疑惑,可扫描下方二维码加入交流答疑群,随时在线探讨、咨询解惑。
