
论文标题:OmniShow: Unifying Multimodal Conditions for Human-Object Interaction Video Generation
论文链接:https://arxiv.org/pdf/2604.11804
项目主页:https://correr-zhou.github.io/OmniShow
合作机构:The Chinese University of Hong Kong、ByteDance、Monash University、The University of Hong Kong
录用情况:ICML 2026
想象一台调音台:每一路推子各管一种信号,人物身份一路、商品外观一路、声音一路、动作一路,而最终它们要混成同一段连贯的画面。难的不是单独推起任意一路,而是四路同时上、还得彼此不打架。
这恰好就是 OmniShow 想做的事——把 text、reference images、audio、pose 四类条件汇进同一个 end-to-end 模型,让它们像调音台上的推子那样被精确调度,而不是各装一台机器再勉强拼接。这项工作已被 ICML 2026 接收。
和市面上把方法切成方向的写法不同,本文打算顺着"四道命令如何进入同一个模型、又如何被验证"的链条走一遍:从任务谈起,依次拆开视觉、音频、训练三条技术路线,再看评测尺子怎么立、实验数字怎么落、应用怎么长出来。

图:一张全景图,先把"能接什么、能产什么"摆清楚
一、命题:四道命令必须「同时成立」
真实的内容生产,从来不是"一句话生成一段差不多的视频",而是"照单表演":人物要像 reference images 里的那个人,商品要保住外观与细节,audio 不只驱动嘴型、还要带动表情与身体节奏,pose 则把逐帧动作钉死,text prompt 在最上层锚定全局语义与场景。四道命令,缺一不可,且彼此牵动。
可现有路线偏偏各占一角、难以贯通:R2V 守得住外观却对声音无动于衷;A2V 能被音频驱动,却常常只认首帧、难以同时指定人与物;pose-guided 方法擅长控动作,却在复杂交互下保不住身份与音画同步;一些HOI方法还要额外喂 mask、trajectory、depth、bounding box,使用门槛陡增。把这些子系统级联起来,臃肿之外更容易在交界处崩坏。OmniShow 的取舍很干脆:不做拼装,而让单一模型在一个统一框架里学会协同。
这套框架建在 Waver 1.0(一个 12B MMDiT 视频生成模型)之上,贯穿始终的只有一条原则——不破坏 base model 的生成先验,把每一种条件放到它最合适的位置。
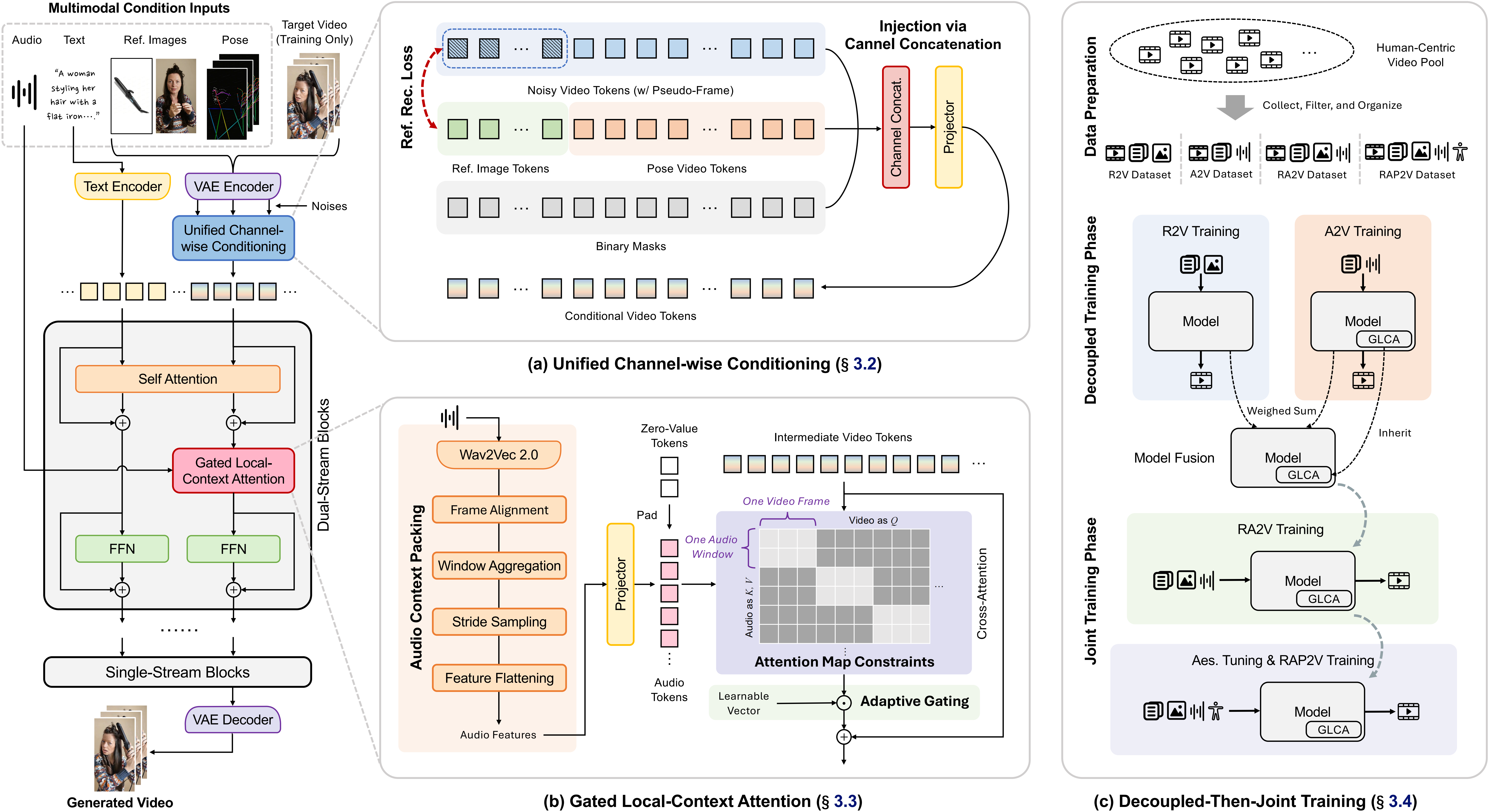
图:流水线总览,三条路线各走各的接口,最终汇到同一段生成
二、第一路推子:视觉条件,贴着原生接口接进来
reference images 与 pose 同属视觉信号,分工却不同——前者是外观的锚点,后者是逐帧的运动约束。OmniShow 没有为它们另起炉灶,而是复用 Waver 1.0 原生的 channel-concat 机制:经 VAE 编码后,在 temporal 维度新增 pseudo-frame tokens 专门承载 reference,pose 则与 noisy video tokens 对齐。
这样一来,模型看到的输入形式与原生 I2V 几乎一致,task adaptation gap 被压到极小。
在此之上还补了一道 Reference Reconstruction Loss:pseudo-frame tokens 由同 timestep 加噪的 reference tokens 初始化,并被要求重建其语义细节——"保真"由此从被动约束变成模型主动追求的显式目标。

图:视觉条件以"低改动"姿态进入,base model 的生成先验被完整守住
三、第二路推子:音频条件,让声音长在节奏上
声音是连续且含节奏的模态,硬塞进 channel 必然丢同步。OmniShow 为它单配一套 Gated Local-Context Attention:先用 Wav2Vec 2.0 融合多层特征,再以 sliding window(window=5、stride=4)对齐到视频 fps,masked attention 约束每个 latent frame 只 attend 对应的局部 audio tokens,从而建立严格的 frame-wise 音画对应。
配套的 Adaptive Gating 把 gating vector 初始化为 near-zero,让音频的影响稳健生长,而不会一上来就扰乱画面。
有意思的是,gating vector 还顺手当了一回"探针":通过观察 gate norm,团队发现音频影响集中在 dual-stream blocks,于是只在这些层注入。
代价极低——模型仅增约 2.5%、合计 12.3B;作为对照,HuMo 为支持音频付出了 +21.4%、整机达 17B。
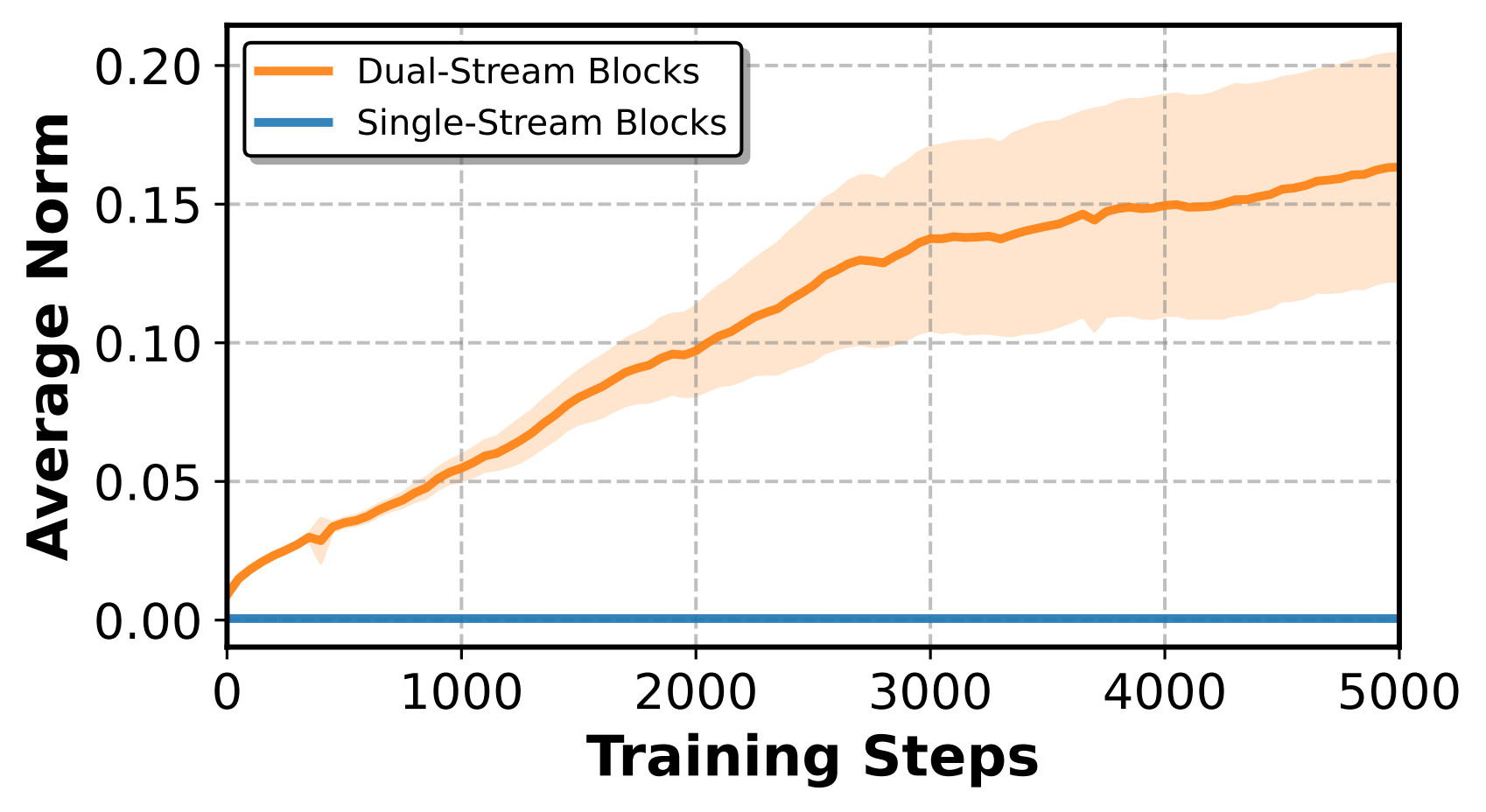
图:门控既稳住训练,又用强弱分布"告诉"团队音频的落点
四、第三路推子:训练,让「专才」先成形再合体
完整的四条件样本极其稀缺——一条数据要同时满足 text、reference images、audio、pose 与目标视频的质量,几乎可遇不可求。
OmniShow 因此搭建多层异构数据流程,把 R2V、A2V、RA2V、RAP2V 等碎片数据都盘活:从大规模 human-centric 视频池出发,经 shot segmentation 切分,再按分辨率、美学、运动强度、OCR 等维度层层过滤。
图:分层的数据构建,为分阶段训练备足不同粒度的"原料"
训练采用 Decoupled-Then-Joint Training:先分别训练 R2V 与 A2V 两个 specialists,再用 weight interpolation 合并(audio 模块取自 A2V,其余按 A2V/R2V = 0.6/0.4 融合),随后在完整 RA2V 上继续训练,pose 留到最后引入。
最出人意料的一幕是:仅靠权重合并,模型在尚未显式训练 RA2V 之前,就已涌现出 joint reference-audio 能力——可控性竟可以通过 weight merging 自发出现,这正是"三路推子能混进同一台调音台"的有力旁证。
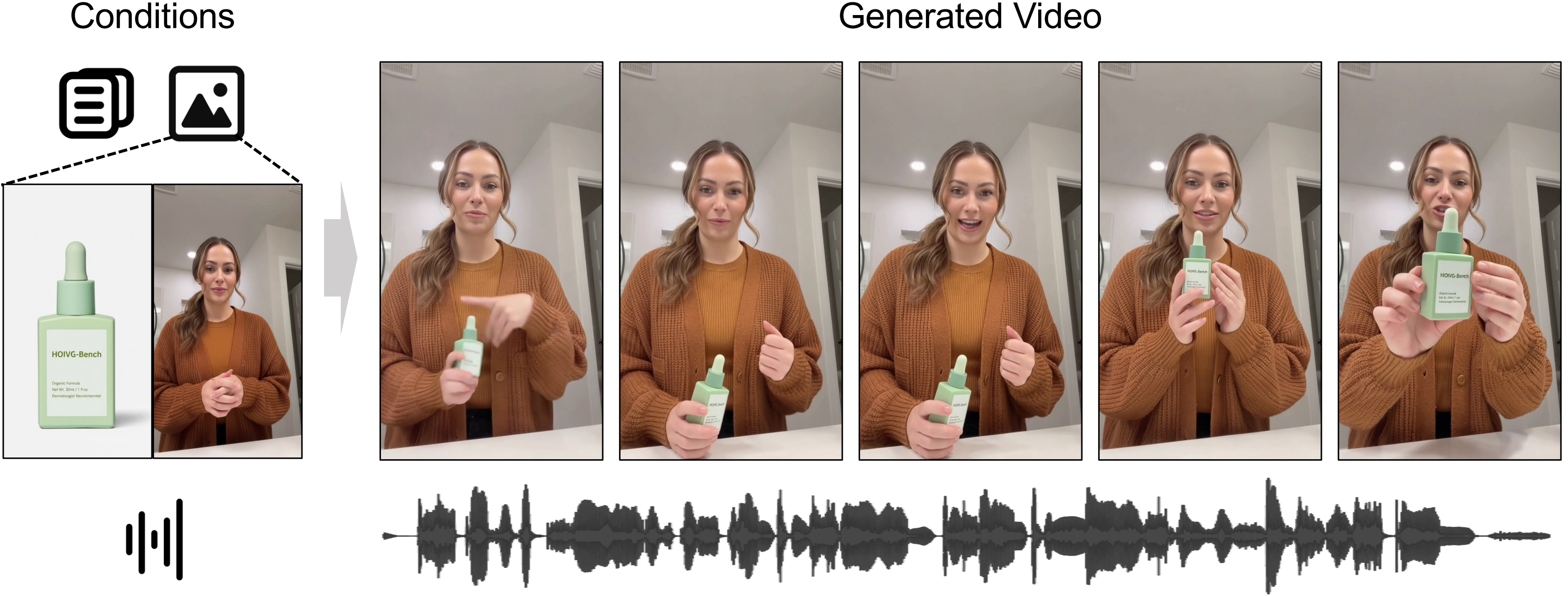
图:合并瞬间冒出的 zero-shot RA2V 能力,说明统一路线确实成立
五、立尺子:HOIVG-Bench 让协同变得可比
要证明三路推子是协同而非互相拖累,得有一把统一的尺子。团队为此构建了 HOIVG-Bench:135 个精选样本,每个都配齐 detailed caption、人物与物体 reference、语义对齐的 audio 与 coherent pose,从 Text Alignment、Reference Consistency、Pose Accuracy、Audio-Visual Synchronization、Video Quality 五个维度打分,专门照出"pose 准但身份漂、嘴型对但商品变形"这类偏科。所有横向对比都在这一基准上完成,保证可比。

图:统一的评测口径,让"多条件协同到底好不好"有了同一把尺
六、画面先说话:定性与并排对比
数字之前,先看画面。在各种条件组合下,OmniShow 都能保持稳定的形象、自然的动作与贴合的音画:R2V 下不会像部分基线把物体以不合常理的尺寸"硬贴"上身,而是兼顾保真与构图合理;RA2V 下自然肢体动作与精准口型并存,避开"反应过度"与"身体僵直";RP2V 下手部接触与物体外观都能准确生成。

图:换不同条件搭配,人物一致性、运动表现与音画同步都站得住
更直接的是 side-by-side 并排对比。团队针对最看重观感的 RA2V 与 RP2V 设定,组织了 side-by-side 人类偏好评测(分别招募 30 人、33 人,对 20 个样本子集评判)。
结论一致:即便某些客观分相当,评估者在多数情况下仍更偏爱 OmniShow——团队将其归因于更平滑的时间动态与更丰富的视觉细节,而这恰是帧级指标容易漏掉、却对"感知真实感"至关重要的部分。
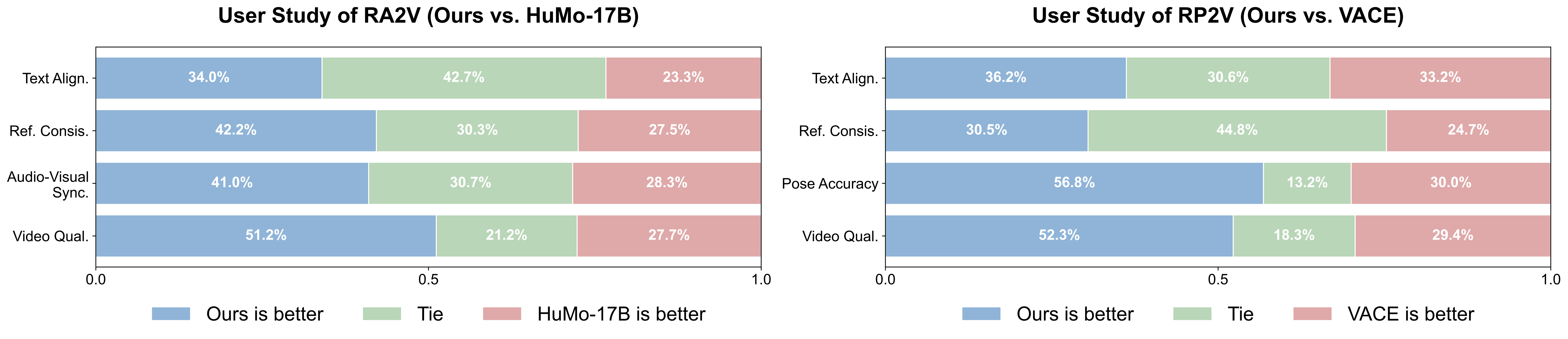
图:并排比对之下,OmniShow 在动态平滑度与细节上更受偏爱
七、数字落地:三种设定逐项拆开看
定量评测把对比对象都摆在同一张台上:HunyuanCustom(13B)、HuMo(17B/1.7B)、VACE(14B)、Phantom(14B/1.3B)、AnchorCrafter(1.5B)。由于这些方法都不支持完整四类输入,实验分别在 R2V、RA2V、RP2V 等设定下展开,以对齐各基线的能力边界。
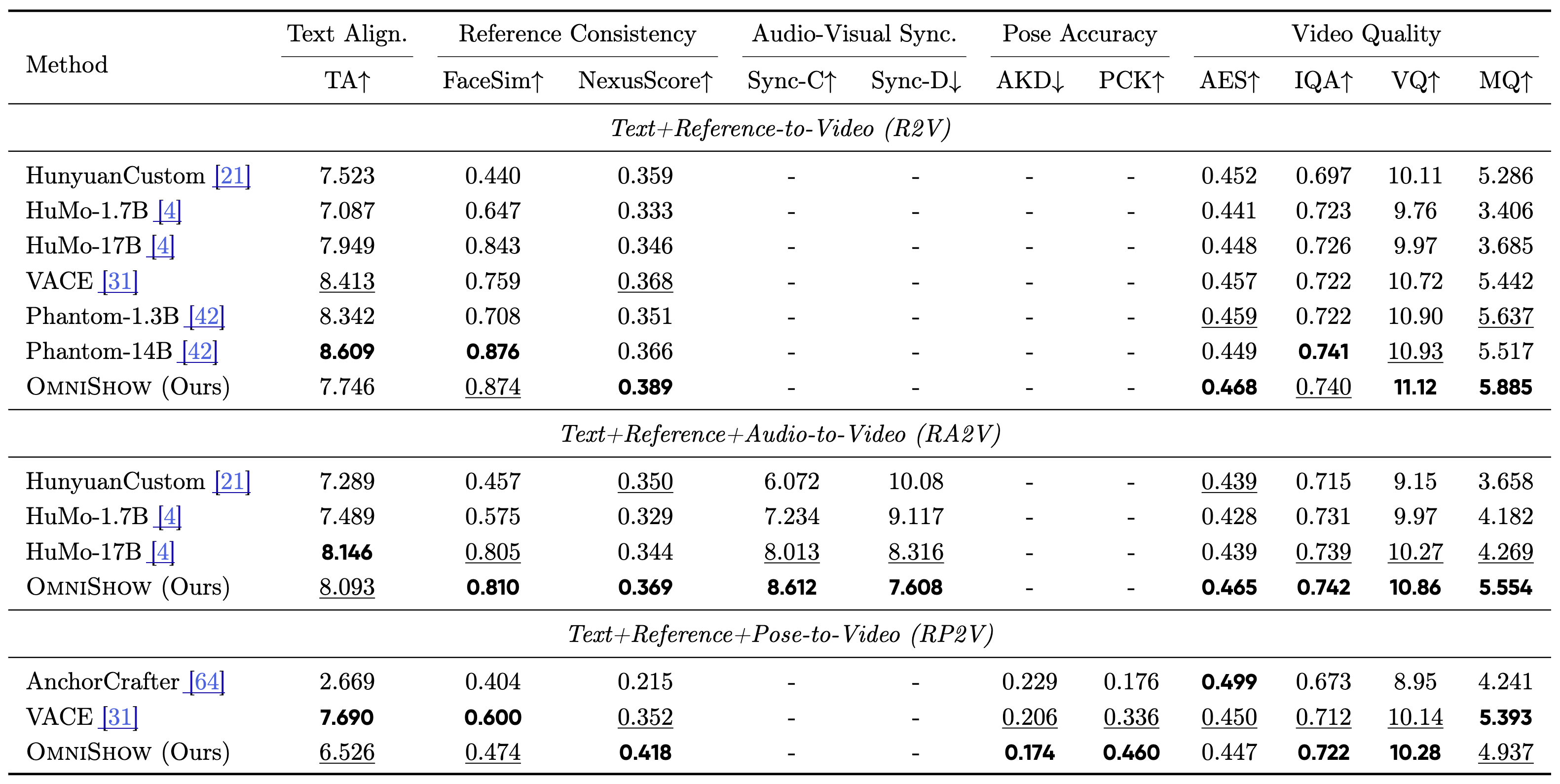
图:在多种条件设定下,整体取得领先或高度竞争的成绩
R2V(reference 到 video)。 在参考保持这一专精方法的传统强项上,OmniShow 的 NexusScore 做到 0.389,反超 VACE(0.368)与 Phantom-14B(0.366)居首;FaceSim 0.874 紧贴体量更大的 Phantom-14B(0.876),几乎打平;AES 0.468、VQ 11.12、MQ 5.885 三项更是直接拿下第一。也就是说,在专精模型最拿手的设定里,它已不落下风甚至反超。
RA2V(再加 audio)。 这是"参考图 + 音频"的复杂场景,也是 OmniShow 拉开差距的地方。Sync-C 8.612、Sync-D 7.608 双双领先 HuMo-17B 的 8.013/8.316,音画同步更准;FaceSim 0.810、NexusScore 0.369、AES 0.465、VQ 10.86、MQ 5.554 全面占优。
越是条件叠加、越接近真实带货与口播需求的场景,OmniShow 越能把专精基线甩在身后——加入音频后,同步、身份一致与画质同时上扬,而非此消彼长。
RP2V(再加 pose)。 动作控制设定下,AKD 降至 0.174、PCK 升到 0.460,动作精度明显优于 VACE(0.206/0.336),相较 AnchorCrafter 也更稳;NexusScore 0.418、VQ 10.28 同样保持领先,意味着复杂动作之下既跟得住 pose,又守得住外观与画质。
把这些拼起来看:所有成绩都来自一个仅 12.3B 的模型,其中音频模块只增加约 2.5%——对照 HuMo 为支持音频付出 +21.4%、整机达 17B,OmniShow 的"协同性价比"几乎一目了然。
八、统一框架 对阵 级联:交界处不再崩坏
一个自然的质疑是:既然单项能力都强,干脆把现成专才级联起来,是不是也能代替统一训练?团队专门做了与 cascaded baseline 的对比,答案是否定的。级联系统在子模块交界处容易累积误差——前一段保住了身份,下一段又在音画或动作上失真,整体既不稳定也难调和。
相比之下,OmniShow 的 end-to-end 统一框架让四类条件在同一空间内协同优化,规避了拼接处的相互打架,画面在身份、同步与动作上更连贯一致。这正说明:把能力"接到一起"远不如把它们"训到一起"。

图:后处理级联易在交界处出错,统一框架则整体协同更稳
九、专才回炉:A2V 单拎出来也能打
作为统一框架基石之一的 A2V 专家,单项能力同样硬核。在专评音频驱动的 EMTD benchmark 上,OmniShow-A2V 取得 Sync-C 6.49,领先 OmniAvatar 的 5.40 与 HunyuanVideo-Avatar 的 4.89;AES 1.51 为全场最高,IQA 2.26 仅次于 Hallo3。
这说明"先把专才做强、再纳入统一框架",并没有牺牲音频驱动本身的质量。
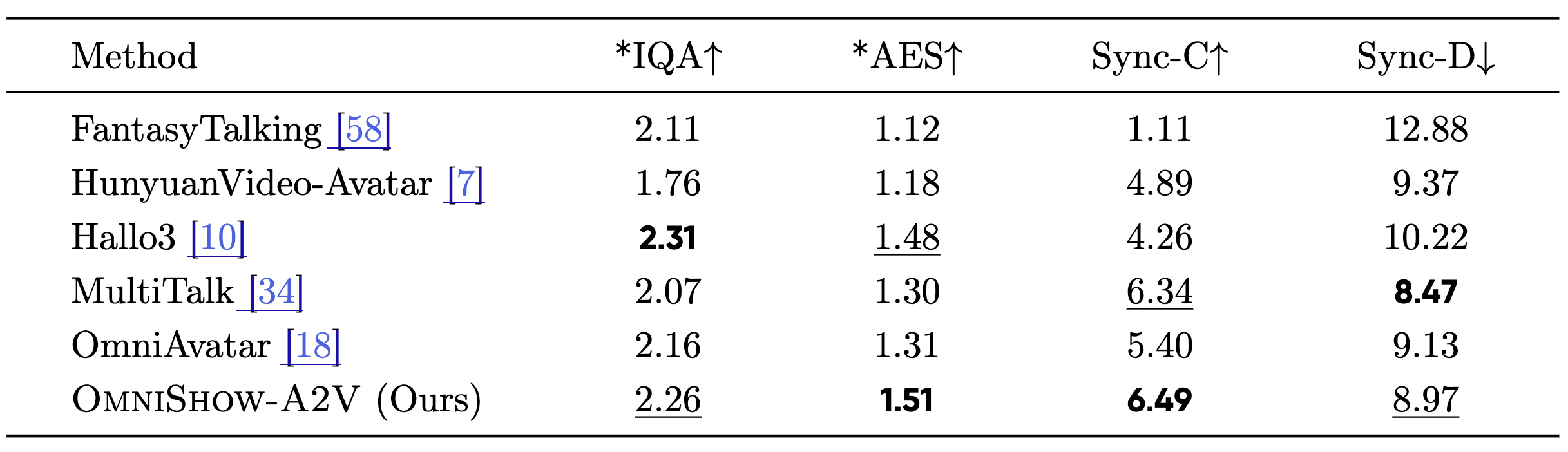
图:放到专用基准上检验,单项音频驱动依然处在一线
十、长出应用:四道命令自由重组
当四类条件被收进同一框架且互不打架,它们便能像调音台上的推子那样自由组合:人物 reference 配 audio,做成 audio-driven avatar;修改物体 reference ,实现 object swapping;把人、物、声、动作重新拼装,则得到 video remixing。
多模态可控视频生成由此从"能生成"走向"能控制、能组合、能复用",直接对应电商带货、短视频口播、数字人讲解与互动娱乐等真实场景。

图:能力一旦统一,应用便可自由排列组合
回看全篇,OmniShow 真正推进的并非某个单点取巧,而是把"四道命令同时成立"这件难事当成一项系统工程来做:视觉条件贴着原生接口注入,音频条件单配局部对齐并用门控自我探针,训练则让专才先成形再合体、甚至涌现出未训练过的联合能力,最后用统一的 HOIVG-Bench 把协同效果量化。
当多模态可控视频生成从"加分项"变成内容生产的刚需,稀缺的从来不是又一个单点模型,而是一台能把人、物、声、动作同时接住、并让它们协同运转的"调音台"——OmniShow 给出的,正是这样一份完整且高效的系统答卷。