
随着大模型能力的不断提升,越来越多的研究开始在RL(强化学习)训练中同时优化多种偏好(如正确性、格式、长度、bug ratio等)。
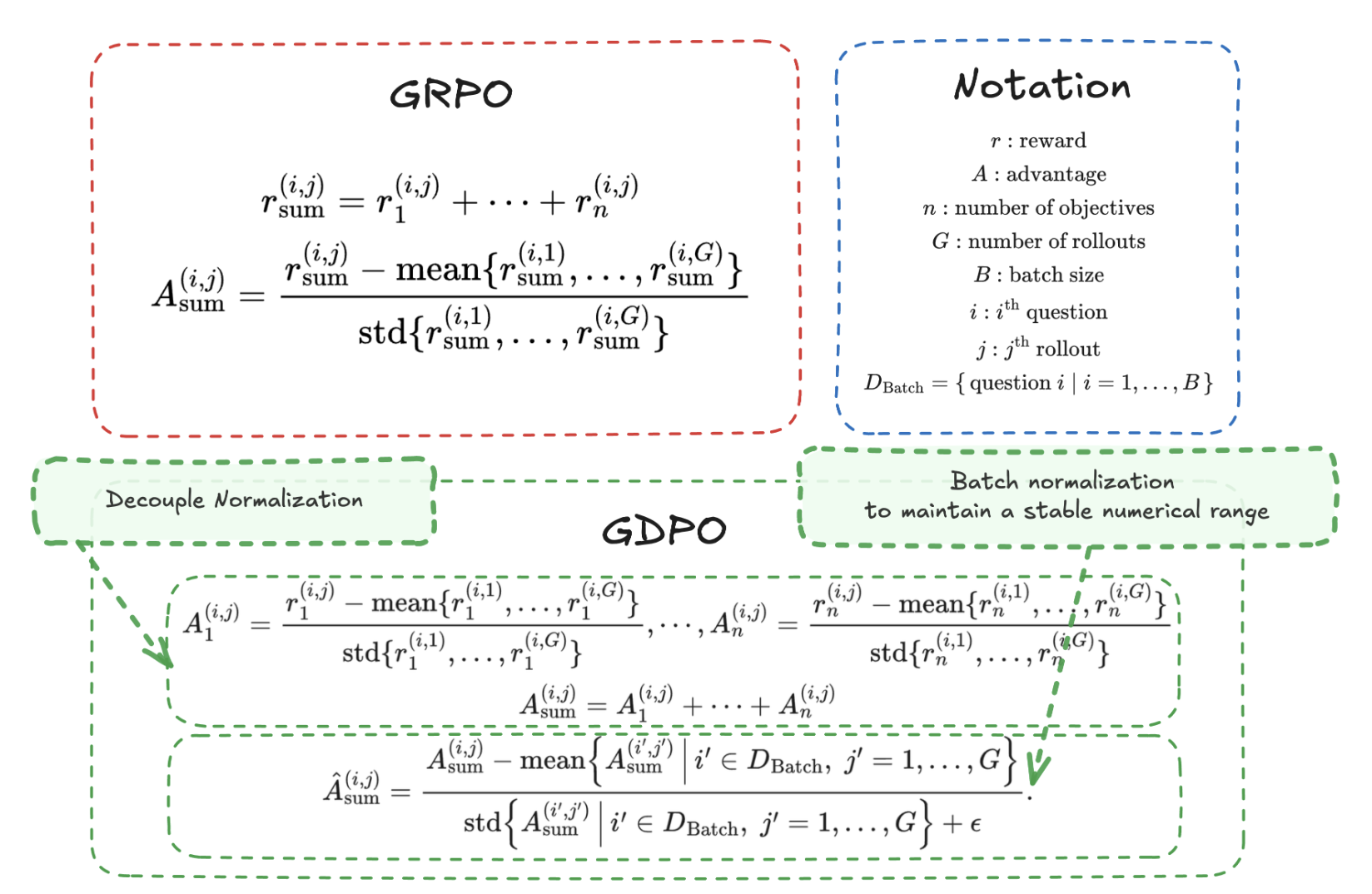
我们发现多奖励强化学习(multi-reward RL)中经常会遇到训练不稳定的问题,并非主要源于奖励设计或权重冲突,而是优势信号在归一化过程中被“压扁”,导致分辨率下降,提出“advantage collapse”这一关键问题。

传统 GRPO 在多奖励场景下的 group-wise normalization 会使不同奖励组合的样本难以区分,削弱学习方向。
为此,研究提出 GDPO,通过逐奖励解耦归一化保留细粒度优势差异,并在聚合后进行 batch 归一化以稳定尺度。实验表明,GDPO 在工具调用、数学推理和代码推理任务中显著提升了训练稳定性与最终性能。
替代 GRPO!英伟达最新成果GDPO,解决多奖励 RL 训练的优势崩溃
该工作指出,多目标 RL 的核心在于保持训练信号清晰度,为推理模型与智能体训练提供了更可诊断、可复用的方法论。
1月30日(周五)上午9点,青稞社区和减论平台将组织青稞Talk 第106期,香港科技大学博士候选人、 NVIDIA 研究实习生刘诗扬,直播分享《GDPO:解决 GRPO 在多奖励 RL 训练中的"优势崩溃"问题》。

分享嘉宾
刘诗扬 (Shih-Yang "Sean" Liu) 现为香港科技大学博士候选人及 NVIDIA 研究实习生。他致力于研究如何减少 AI 模型的训练以及部署开销,研究范畴涵盖参数高效微调(PEFT)与模型优化(Quantization)和利用RL训练模型学习如何减少输出长度。
主题提纲
GDPO:解决 GRPO 在多奖励 RL 训练中的"优势崩溃"问题
1、多奖励 RL 训练挑战与传统 GRPO 算法的局限性
2、通过逐奖励解耦归一化的 GDPO
3、GDPO 的性能验证与多目标 RL 讨论
4、AMA (Ask Me Anything)环节
直播时间
1月30日(周二)9:00 - 10:00