

如果有人说:不用分阶段训练、不搞课程学习、不动态调参,只用最基础的 RL 配方也能达到不错的性能,会是怎样的结果?
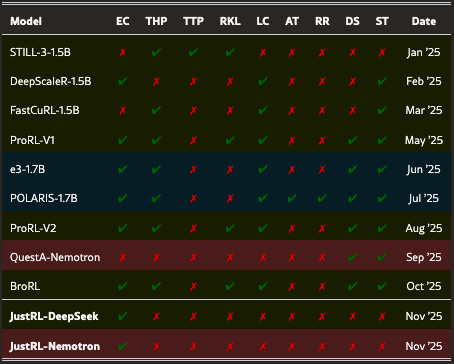
清华团队用两个 1.5B 模型做了这个尝试。结果在 9 个数学推理基准上达到了 54.87% 和64.32% 的新基线,算力只用了一半,训练过程也很平稳,4000步没遇到什么大问题。

更有趣的是,当我们试着加入一些"应该有用"的优化时,性能反而下降了。也许在某些情况下,简单的方法充分训练后,效果可能比我们预期的要好。这个工作最大的 novelty,也许就在于没有 novelty。

2月3日(周二)晚8点,青稞社区和减论平台将联组织 #青稞Talk 第107期,清华大学博士生何秉翔,将直播分享《JustRL: 用"最笨"的 RL 方法刷新 1.5B 推理模型新基线》。
分享嘉宾
何秉翔,清华大学博士生,导师为清华大学刘知远教授。研究方向为大模型对齐与强化学习,曾在 ACL、ICML、NeurIPS 等人工智能国际顶级会议发表论文,谷歌学术引用量超1000次。
主题提纲
JustRL: 用"最笨"的 RL 方法刷新 1.5B 推理模型新基线
1、RL 训练的 Trick 方法
2、极致简洁的 JustRL 及实现
3、消融实验及性能对比
4、AMA (Ask Me Anything)环节
直播时间
2月3日(周二)20:00 - 21:00