作者:归来仍是少年
原文链接:https://zhuanlan.zhihu.com/p/1991109652348418036
很多人在学习PPO(Proximal Policy Optimization)用于语言模型优化时,会直观认为既然已有 reward model(RM)来判断一个 response 的好坏,那么直接用它提供的信号去训练 policy model 不就行了吗?为何还要多此一举引入一个 critic model(价值函数)?
更进一步,如果 RM 能给出 token-level 的奖励信号,是否 critic 就完全冗余了?——这背后其实牵涉到强化学习的核心机制、时序信用分配(credit assignment)问题,以及 reward model 的本质局限。
Reward Model 的作用与局限
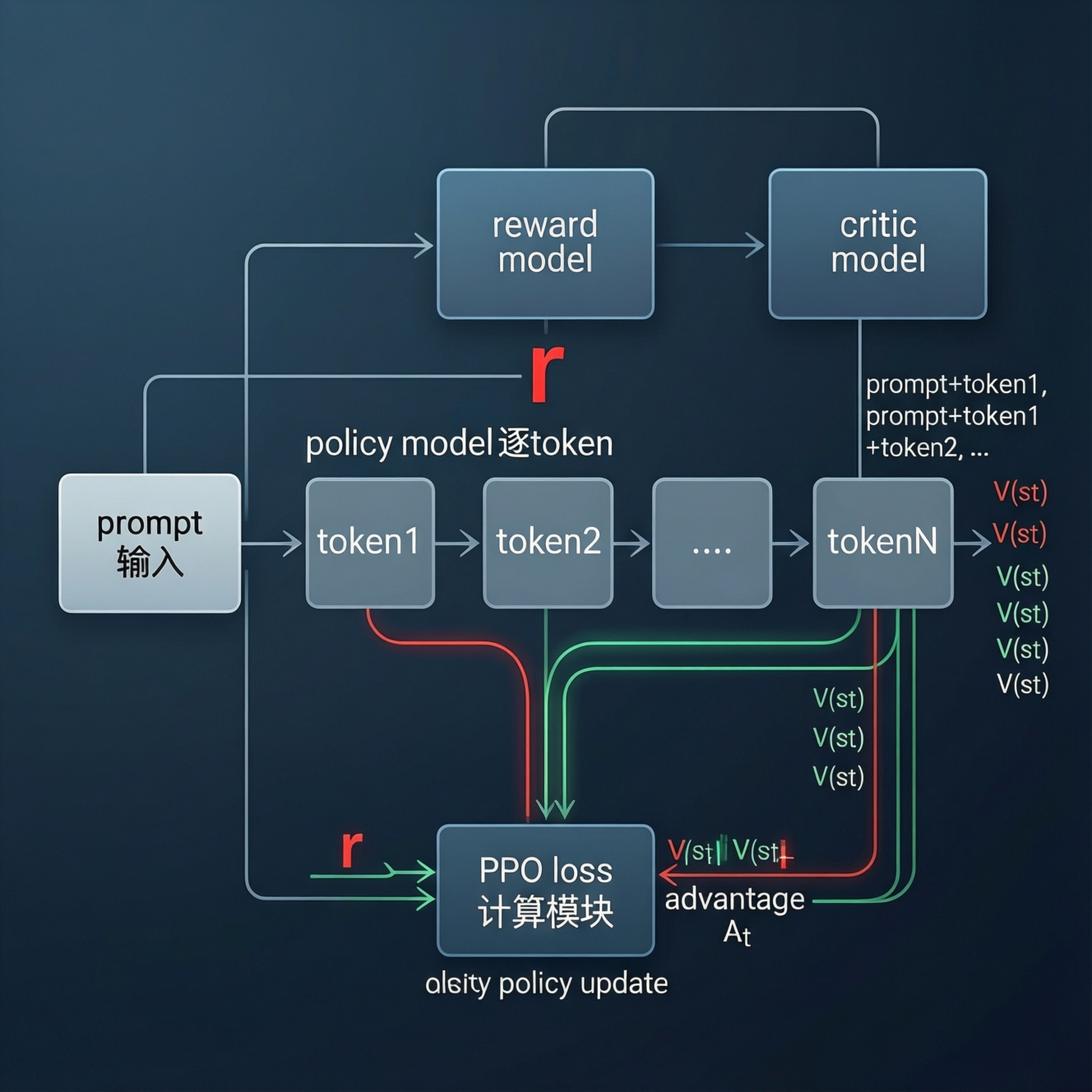
首先明确一点:reward model 通常只对一个完整的 response 进行打分,而不是对每个 token 打分。
在典型的 RLHF 流程中,RM 接收一个 prompt + response 对,输出一个 scalar score,代表整体偏好程度。
这个 score 是全局的、延迟的、稀疏的:它只在序列末尾出现,无法告诉模型“哪一部分写得好、哪一部分写得差”。
例如,模型生成了一段 500 个 token 的回答,RM 给出 +1 分。但其中前 300 个 token 逻辑严谨,后 200 个 token 胡说八道——RM 无法区分。
如果直接用这个 +1 去反向传播到整个序列的每个 token,就会导致“好 token 被差 token 拖累,差 token 被好 token 带飞”的问题。这就是 credit assignment problem(信用分配问题) 的典型体现。
你可能会想:那能不能让 RM 输出 token-level 的奖励?比如通过某种 attention 或 sliding window 打分?技术上当然可以尝试(例如用对比学习训练一个 local RM),但这会带来几个问题:
1.缺乏人类标注的 token-level 偏好数据:人类很难对中间 token 做细粒度偏好判断。我们能判断“整段回答是否可信”,但很难说“第 127 个 token 应该更谨慎”。因此,token-level RM 很难获得高质量监督信号。
2.局部奖励可能误导全局目标:一个 token 看似“好”(比如用了一个高级词汇),但放在上下文中反而破坏逻辑连贯性。局部最优 ≠ 全局最优。
3.RM 本质是判别模型,不具备时序建模能力:它不理解“未来还有多少 token 要生成”,也无法估计“当前 action 对最终 reward 的贡献”。
因此,reward model 的定位是提供 unbiased 的最终 outcome 信号,而不是指导 token-by-token 的训练过程。
Critic Model 的本质:价值函数与优势估计
PPO 属于 actor-critic 架构,其中:
- Actor(policy model):决定在状态 s 下采取什么 action(即生成哪个 token)。
- Critic(value model):估计在状态 s 下,未来能获得的期望累积奖励,即价值函数 V(s)。
在语言模型的上下文中,“状态 s” 可以理解为当前已生成的 token 序列前缀(prompt + partial response)。Critic 的任务就是预测:从当前这个前缀出发,最终能获得多少 reward?
有了 V(s) 之后,就可以计算 优势函数(Advantage Function):
A(s, a) = Q(s, a) - V(s)
其中 Q(s, a) 是“在状态 s 下采取 action a 后的期望累积奖励”。但在实践中,我们并不直接估计 Q,而是用 蒙特卡洛回报(Monte Carlo Return) 来近似:
R_t = \sum_{k=t}^{T} \gamma^{k-t} r_k
但由于 RM 只在 T 时刻给出一个 scalar reward(设为 r_T,中间 r_t = 0),所以:
R_t = \gamma^{T-t} r_T
于是优势函数简化为:
A_t = R_t - V(s_t) = \gamma^{T-t} r_T - V(s_t)
这个 A_t 就是我们用来更新 policy 的核心信号。它衡量的是:“在 t 时刻采取当前 action,比平均水平好多少?”——这就是 token-level 的训练信号。
为什么不能只用 RM?Critic 的不可替代性
假设我们强行不用 critic,直接用 RM 的最终 reward r_T 作为每个 token 的 loss 信号(即所有 token 共享同一个 reward),这相当于:
- 使用 REINFORCE 算法(蒙特卡洛策略梯度),其梯度估计方差极大。
- 没有 baseline(即 V(s)),导致训练极不稳定。
- 无法区分“早 token”和“晚 token”的贡献:越早的 token 对最终 reward 的影响本应更大,但其梯度被相同的 reward 乘以更小的策略概率,反而更新更弱。
而 critic 提供的 V(s_t) 充当了 方差缩减器(variance reducer)。通过 subtracting V(s_t) from R_t,我们得到了一个“去噪”后的信号,使得只有“超出预期”的 action 才会被强化。这极大提升了训练效率与稳定性。
更重要的是,critic 是在线学习的(on-policy),它和 policy 一起在当前策略生成的 trajectory 上训练,因此能准确反映当前 policy 的行为价值。而 RM 是离线固定的(offline),代表的是人类偏好,但无法动态适应 policy 的变化。
如果 RM 真能输出 token-level reward,还需要 critic 吗?
即使假设我们有一个完美的 token-level RM(例如每个 token 都有 ground-truth reward),critic 仍然有其价值,原因如下:
1.Temporal Credit Assignment 仍需累积:单个 token 的 reward 可能很小,甚至为零,但多个 token 的组合才有意义。Critic 通过估计未来 reward 的总和,能更好地捕捉 long-term dependency。
2.Reward Shaping vs. Value Estimation:RM 提供的是“外部奖励”,而 critic 学习的是“内部价值”,后者可以更平滑、更稳定。
例如,在对话中,一个承上启下的过渡句可能 RM 打分不高,但 critic 会知道它为后续高 reward 的结论做了铺垫。
3.PPO 的目标函数依赖 advantage:PPO 的 clip loss 是:
这里的 A_t 必须是 advantage,而不仅仅是 reward。没有 critic 就无法计算 A_t。
代码层面的直观理解(伪代码)
# 生成一个 trajectory: tokens = [x1, x2, ..., xT]
logprobs = policy(prompt).log_prob(tokens) # shape: [T]
reward = reward_model(prompt + tokens) # scalar
# critic 对每个前缀预测 value
values = []
for t in range(T):
prefix = prompt + tokens[:t]
v_t = critic(prefix) # scalar
values.append(v_t)
values = torch.tensor(values) # [T]
# 计算 returns (这里 gamma=1, 中间 reward=0)
returns = torch.zeros(T)
returns[-1] = reward
# 实际中可能用 GAE: Generalized Advantage Estimation
advantages = returns - values # [T]
# PPO loss per token
ratio = torch.exp(logprobs - old_logprobs)
surrogate1 = ratio * advantages
surrogate2 = torch.clamp(ratio, 1-eps, 1+eps) * advantages
policy_loss = -torch.min(surrogate1, surrogate2).mean()
可以看到,critic 提供的 values 是计算 advantage 的必要组件。没有它,advantages 就退化为 returns(即所有 token 共享 reward),训练效果大打折扣。
分工明确,各司其职
Reward Model:提供人类偏好的、全局的、最终的评价信号,是“裁判”。
Critic Model:提供时序动态的、局部的、预测性的价值估计,是“教练”。
Policy Model:根据 advantage 信号调整行为,是“运动员”。
三者构成一个闭环:policy 生成样本 → RM 打分 → critic 估计价值 → 计算 advantage → 更新 policy。
critic 的存在,使得稀疏、延迟的 reward 能被有效分解到每个决策点上,这是 PPO 能在语言模型上成功应用的关键。
所以,即便未来出现 token-level RM,critic 依然不可或缺——因为它解决的不是“奖励从哪来”,而是“奖励如何分配”的问题。