
视觉模型长期面临语义抽象与像素细节难以统一建模的问题,现有要么擅长理解,要么擅长生成,却难以兼得。
- 像 ViT、ResNet 这样的语义模型,能精准识别图像中的物体类别,却无法重建出一张清晰的图片;
- 而像 MAE、GAN 或扩散模型这样的生成系统,虽能合成逼真的像素细节,却常常“看不懂”自己画的是什么——比如生成三只眼睛的人脸,或结构错乱的汽车。
这种“理解”与“生成”的割裂,不仅导致模型碎片化,也阻碍了通用视觉智能的发展。

论文:The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
链接:https://arxiv.org/abs/2512.19693
代码:https://github.com/WeichenFan/UAE
来自南洋理工大学 MMLab 与 SenseTime Research 的研究员在最新的研究成果中,从频谱角度出发,提出一种统一表征假设(The Prism Hypothesis):

- 低频成分(<10%):承载全局结构、物体类别、场景语义——这是“理解”的基础;
- 高频成分(>50%):包含纹理、边缘、材质细节——这是“生成”的关键。
过去模型之所以难以兼顾两者,是因为它们在同一个潜在空间中混用所有频率,导致语义任务被噪声干扰,生成任务被过度平滑。
而统一表征假设认为视觉信号中的语义信息与细节信息可沿频率维度自然分离,并在同一潜在空间中协调建模。
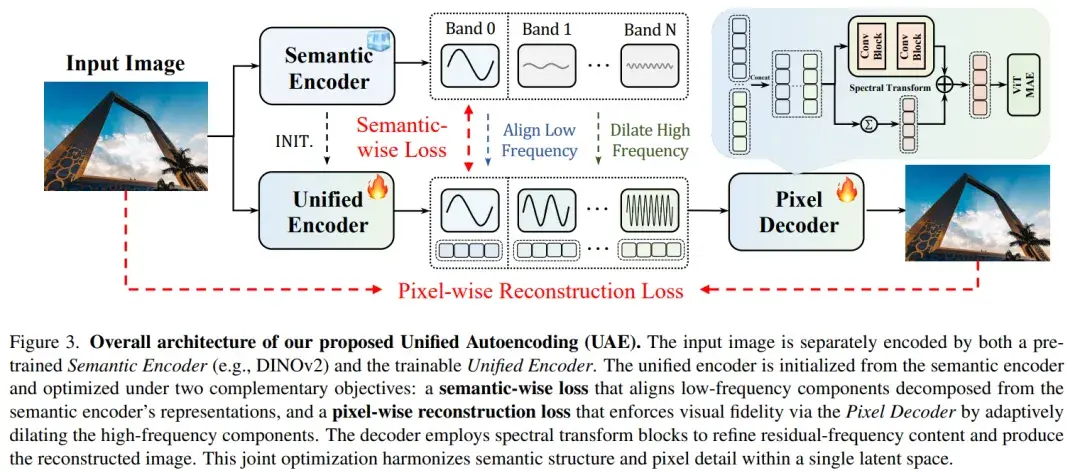
基于该假设,研究者系统性地构建了一个统一自编码框架(UAE),实验结果表明,该框架在不牺牲语义判别能力的前提下显著提升了重建与生成性能,为统一视觉理解与生成提供了新的视角与方法基础。

1月20日(周二)晚8点,青稞Talk 第104期,南洋理工大学 MMLab 实验室博士生范洧辰,将直播分享《视觉统一表征假说(The Prism Hypothesis):从语义到像素的统一自编码(UAE)》。
分享嘉宾
范洧辰,南洋理工大学 MMLab 实验室博士生,导师为刘子纬教授。曾参与Vchitect 系列文生视频项目,相关工作已开源并获得社区广泛关注。研究兴趣涵盖视频生成、多模态学习与扩散模型,致力于探索高保真、高可控的生成方法,尤其关注文本驱动下的视频内容生成与跨模态表示对齐。
主题提纲
视觉统一表征假说(The Prism Hypothesis):从语义到像素的统一自编码(UAE)
1、语义 & 像素,视觉模型的两大范式及其能力边界
2、频谱视角:视觉统一表征假说
3、统一自编码框架 UAE
4、AMA (Ask Me Anything)环节
直播时间
1月20日(周二)20:00 - 21:00