最近,随着大模型能力的不断提升,越来越多的研究开始在RL(强化学习)训练中同时优化多种偏好(如正确性、格式、长度、bug ratio等)。
这个趋势看似合理,但一个被广泛忽视的问题正在影响着训练效果——多奖励RL中的"优势崩溃"(Advantage Collapse)。

来自 NVIDIA 的研究者们,在 Multi-reward RL Optimization 上最新提出了 GDPO(Group reward-Decoupled Normalization Policy Optimization)方法,它不仅解决了这个关键问题,还为多奖励RL训练提供了更稳定、高效的解决方案。
链接:https://huggingface.co/papers/2601.05242
代码:https://github.com/NVlabs/GDPO
一、为什么多奖励RL训练会"翻车"?
在传统RL训练中,我们通常只优化单一奖励信号。但随着模型能力提升,单一奖励已无法满足复杂任务需求。于是,研究者们开始尝试"多奖励"策略:将多个奖励信号(如格式奖励、正确性奖励、长度奖励等)组合起来训练模型。
当前主流做法:将多个奖励信号简单相加,然后使用GRPO(Group Relative Policy Optimization)进行优化。

然而,NVlabs团队在最新论文中发现了一个关键问题:在多奖励设置下,GRPO的group-wise normalization(组内归一化)会把不同奖励组合压缩成几乎相同的advantage(优势值),导致训练信号分辨率大幅下降。
简单来说,当多个奖励信号被组合后,它们的相对差异被"抹平"了,模型无法有效区分哪些行为是真正更好的。这就像把不同颜色的颜料混合在一起,最终只剩下一种模糊的灰色,导致训练信号丢失。
结果就是:
- 训练收敛变慢
- 模型性能不稳定
- 甚至在早期训练阶段就失败
这就是我们所说的"advantage collapse"(优势崩溃)。
二、GDPO:解耦归一化,保留奖励差异
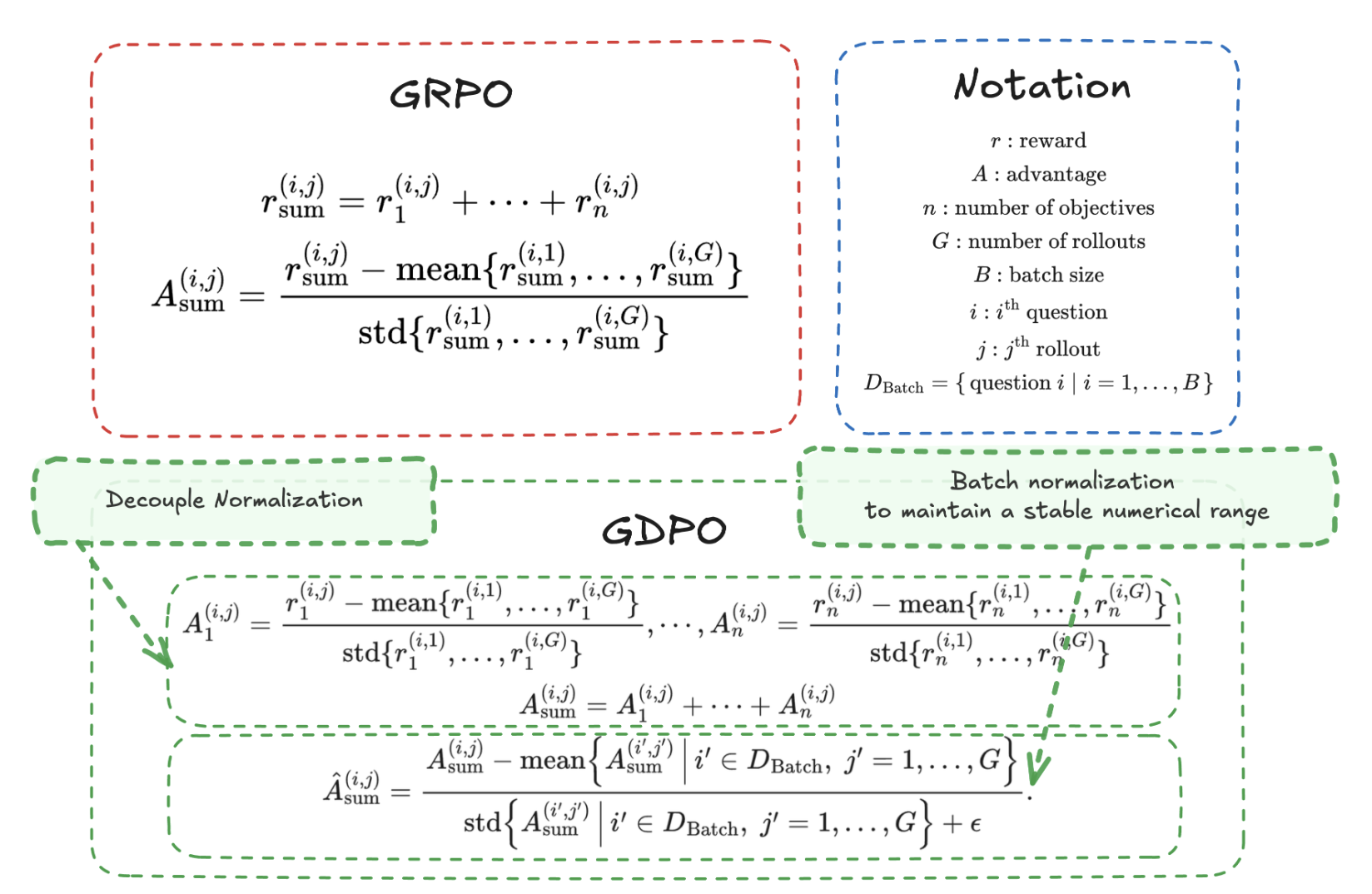
GDPO的核心思想很简单,但非常有效:"多奖励RL的关键不是'加更多reward',而是'别让advantage先坍塌'"
GDPO通过"解耦归一化"来解决这个问题:
1、 逐reward做group-wise normalization(解耦归一化):先对每个奖励信号单独进行组内归一化,保留它们的相对差异
2、 再聚合奖励:将处理后的奖励信号组合起来
3、 最后做batch-wise normalization:确保数值尺度不会随着奖励数量增加而膨胀,保证更新稳定性
这种设计确保了每个奖励的相对重要性被保留,避免了GRPO中的优势崩溃问题。

GDPO 在各种不同的强化学习训练设定下(例如不同的 rollout 数量和不同的 reward 数量),均能更有效地保留训练信号的分辨率(即保持更高数量的、具有显著差异的优势群组,distinct advantage group count)。
三、GDPO vs GRPO:技术实现差异
GDPO与GRPO的代码差异非常小,几乎可以视为"一键替换"。
TRL框架中GDPO与GRPO的代码实现:
GRPO实现
# line 1254 in trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
# Gather the reward per function: this part is crucial, because the rewards are normalized per group and the
# completions may be distributed across processes
rewards_per_func = gather(rewards_per_func)
rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1)
# Compute grouped-wise rewards
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
is_std_zero = torch.isclose(std_grouped_rewards, torch.zeros_like(std_grouped_rewards))
# Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = rewards - mean_grouped_rewards
if self.scale_rewards:
advantages = advantages / (std_grouped_rewards + 1e-4)
GDPO实现
# line 1222 in trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
# Gather the reward per function: this part is crucial, because the rewards are normalized per group and the
# completions may be distributed across processes
rewards_per_func = gather(rewards_per_func)
## Make sure every reward contain no nan value
rewards_per_func_filter = torch.nan_to_num(rewards_per_func)
all_reward_advantage = []
## Calculate the mean and std of each reward group-wise separately
for i in range(len(self.reward_weights)):
reward_i = rewards_per_func_filter[:,i]
each_reward_mean_grouped = reward_i.view(-1, self.num_generations).mean(dim=1)
each_reward_std_grouped = reward_i.view(-1, self.num_generations).std(dim=1)
each_reward_mean_grouped = each_reward_mean_grouped.repeat_interleave(self.num_generations, dim=0)
each_reward_std_grouped = each_reward_std_grouped.repeat_interleave(self.num_generations, dim=0)
each_reward_advantage = reward_i - each_reward_mean_grouped
each_reward_advantage = each_reward_advantage / (each_reward_std_grouped + 1e-4)
all_reward_advantage.append(each_reward_advantage)
combined_reward_advantage = torch.stack(all_reward_advantage, dim=1)
pre_bn_advantages = (combined_reward_advantage * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1)
## compute batch-wise mean and std
bn_advantages_mean = pre_bn_advantages.mean()
bn_advantages_std = pre_bn_advantages.std()
advantages = (pre_bn_advantages - bn_advantages_mean) / (bn_advantages_std + 1e-4)
verl框架中GDPO与GRPO的代码实现:
GRPO实现
## line 148 in verl-GDPO/verl/trainer/ppo/ray_trainer.py
elif adv_estimator == 'grpo':
token_level_rewards = data.batch['token_level_rewards']
index = data.non_tensor_batch['uid']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
advantages, returns = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_rewards,
eos_mask=response_mask,
index=index)
data.batch['advantages'] = advantages
data.batch['returns'] = returns
GDPO实现
## line 175 in verl-GDPO/verl/trainer/ppo/ray_trainer.py
token_level_scores_correctness = data.batch['token_level_scores_correctness']
token_level_scores_format = data.batch['token_level_scores_format']
# shared variables
index = data.non_tensor_batch['uid']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
## handle correctness first
correctness_normalized_score, _ = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_scores_correctness,
eos_mask=response_mask,
index=index)
## handle format now
format_normalized_score, _ = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_scores_format,
eos_mask=response_mask,
index=index)
new_advantage = correctness_normalized_score + format_normalized_score
advantages = masked_whiten(new_advantage, response_mask) * response_mask
data.batch['advantages'] = advantages
data.batch['returns'] = advantages
可以看到,GDPO的关键改进在于先对每个奖励单独进行组内归一化,保留了奖励的相对差异,而不是像GRPO那样先聚合再归一化。
四、实验验证:GDPO在三个任务上全面领先
NVlabs团队在三个典型任务上系统验证了GDPO的效果:
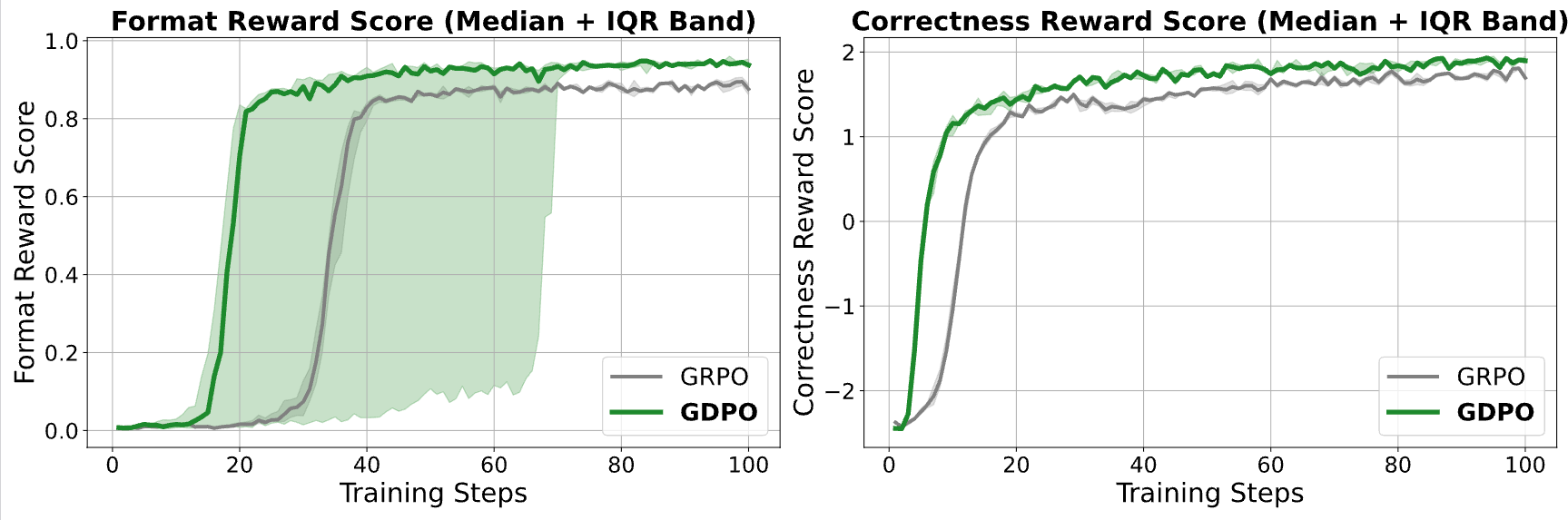

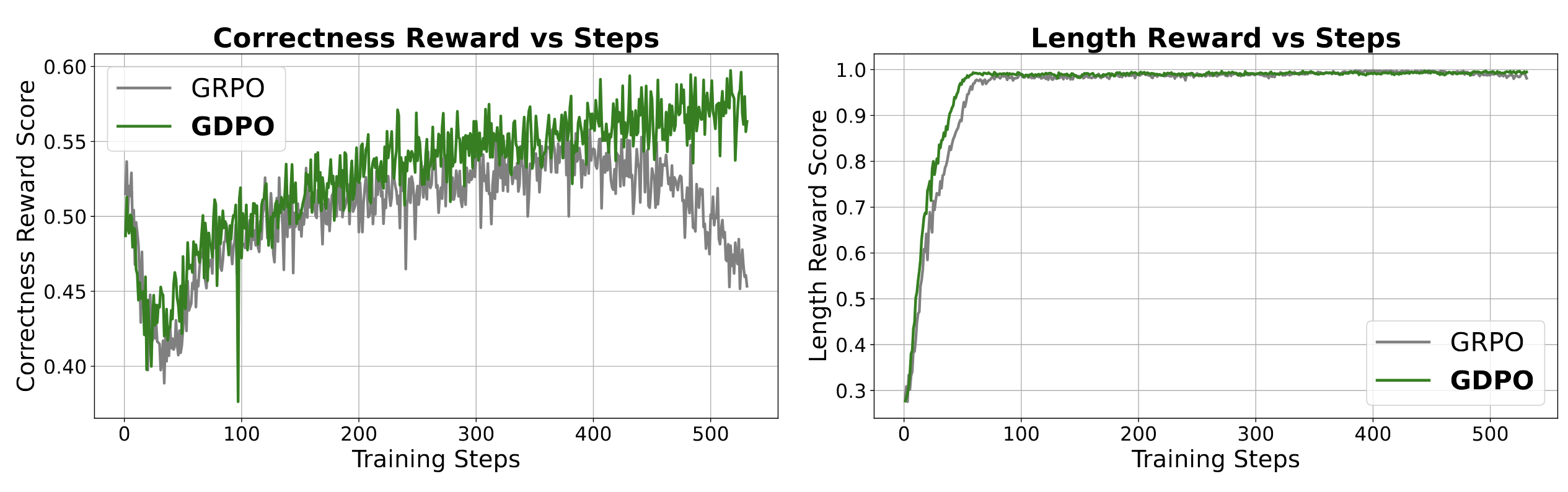
关键发现:GDPO不仅在训练收敛速度上更快,而且在训练过程中更加稳定,避免了GRPO常见的训练失败问题。
五、为什么GDPO如此重要?
GDPO的提出,为多奖励RL训练提供了一个简单而有效的解决方案。它的优势在于:
- 无需修改训练框架:GDPO是GRPO的简单替换,修改代码量极小
- 通用性强:已在VERL、TRL和Nemo-RL三个主流框架中实现
- 效果显著:在多个任务上都优于GRPO
正如论文中所说:"多奖励RL的关键不是'加更多reward',而是'别让advantage先坍塌'"。
六、结语
多奖励RL是提升大模型能力的重要方向,但"优势崩溃"问题一直困扰着研究者。GDPO通过简单的解耦归一化策略,成功解决了这一问题,为多奖励RL训练提供了新的思路。
如果你正在做多奖励RL训练,不妨尝试GDPO,它可能会让你的训练过程更加稳定、效果更佳。记住,训练效果的关键不在于奖励数量,而在于如何保留奖励的"信号价值"。
欢迎在评论区讨论你对多奖励RL的看法,或者分享你在实际项目中使用GRPO或GDPO的经验!