从DeepSeek R1到MiniMax-M2,当今最大且功能最强的开源权重大型语言模型(LLMs)仍然是基于原始多头注意力机制变体的自回归解码器式Transformer。
然而,近年来我们也看到了标准LLMs的替代方案不断涌现,从文本扩散模型到最新的线性注意力混合架构。其中一些旨在提高效率,而另一些(如代码世界模型)则致力于提升建模性能。
前面分享《大模型架构对比》,重点介绍了主要的基于Transformer的LLMs,本文就来聊聊对这些替代方案看法。
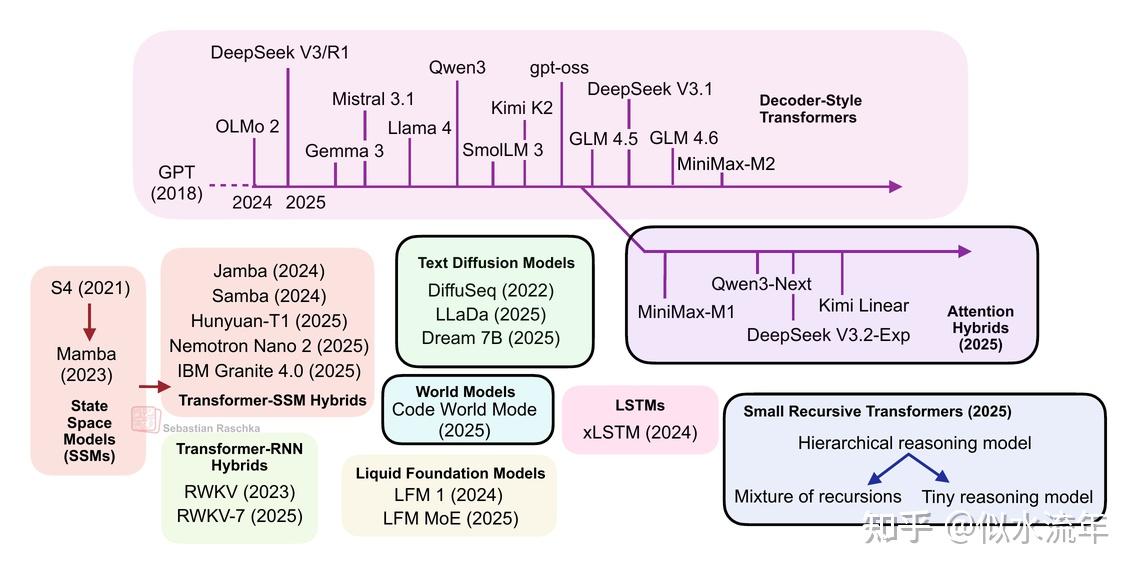
请注意,理想情况下,上图中显示的每个主题都值得撰写至少一篇完整的文章(并且希望未来能实现)。
因此,为了保持本文的合理长度,许多部分都相对简短。然而,我仍然希望本文能作为近年来涌现的所有有趣LLMs替代方案的有用入门介绍。
1. 基于Transformer的大语言模型
基于经典Transformer架构的LLMs在文本和代码领域仍处于最先进水平。仅考虑2024年底至今的一些亮点,值得注意的模型包括:
- DeepSeek V3/R1
- OLMo 2
- Gemma 3
- Mistral Small 3.1
- Llama 4
- Qwen3
- SmolLM3
- Kimi K2
- gpt-oss
- GLM-4.5
- GLM-4.6
- MiniMax-M2
还有许多其他模型。(上述列表主要关注开源大模型;像GPT-5、Grok 4、Gemini 2.5等专有模型也属于此类。)

由于我多次有写基于Transformer的LLMs,因此默认你对这一概念和架构的整体思路已经有所了解。
如果你想深入了解,可以阅读这篇文章《大模型架构对比》,文中对上述列出的架构(如下图所示)进行了详细对比。
PS:我本可以将Qwen3-Next和Kimi Linear与概述图中的其他Transformer-状态空间模型(SSM)混合架构归为一类。我个人认为这些其他Transformer-SSM混合模型是带有Transformer组件的SSM,而这里讨论的模型(Qwen3-Next和Kimi Linear)则是带有SSM组件的Transformer。不过,既然我已经将IBM Granite 4.0和NVIDIA Nemotron Nano 2列入了Transformer-SSM类别,也可以有论点支持将它们归为同一类别。
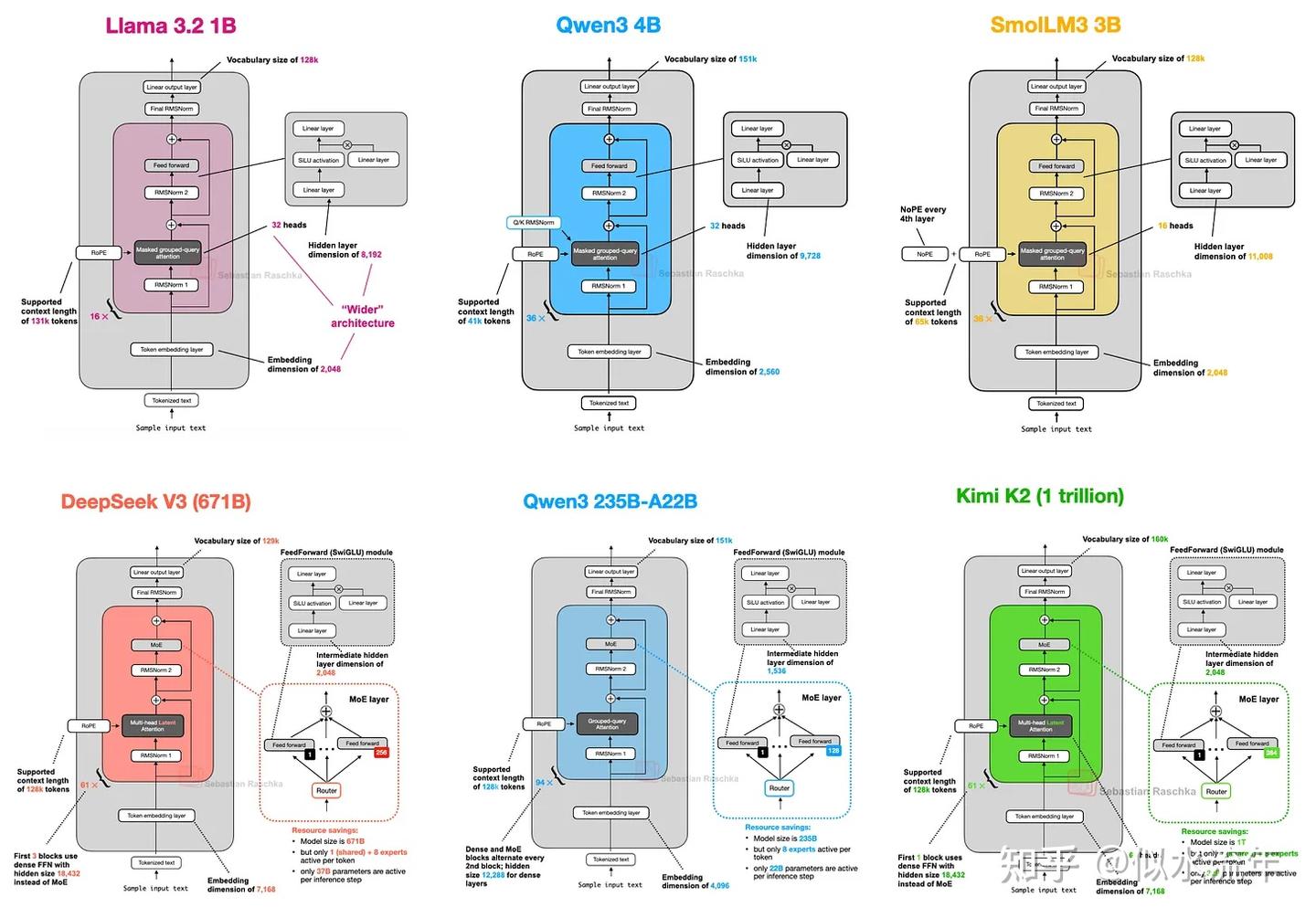
如果你正在与大型语言模型(LLMs)打交道,例如构建应用程序、微调模型或尝试新算法,我会将这些模型作为首选。它们经过测试、验证且性能良好。
此外,正如《大模型架构比较》一文中所讨论的,有许多效率提升措施,包括分组查询注意力、滑动窗口注意力、多头潜在注意力等。
然而,如果研究人员和工程师不致力于尝试替代方案,那将是乏味的,也是短视的。因此,剩余部分将涵盖近年来出现的一些有趣的替代方案。
2. (线性)注意力混合模型
在我们讨论更不同的方法之前,先来看一下采用更高效注意力机制的基于Transformer的大语言模型(LLMs)。特别关注那些随着输入token数量呈线性扩展而非二次扩展的模型。
最近,线性注意力机制出现了复兴,以提高大语言模型的效率。
2017年《Attention Is All You Need》论文中引入的注意力机制,即缩放点积注意力,仍然是当今大语言模型中最流行的注意力变体。除了传统的多头注意力外,它还被用于更高效的变体中,如分组查询注意力、滑动窗口注意力和多头潜在注意力。
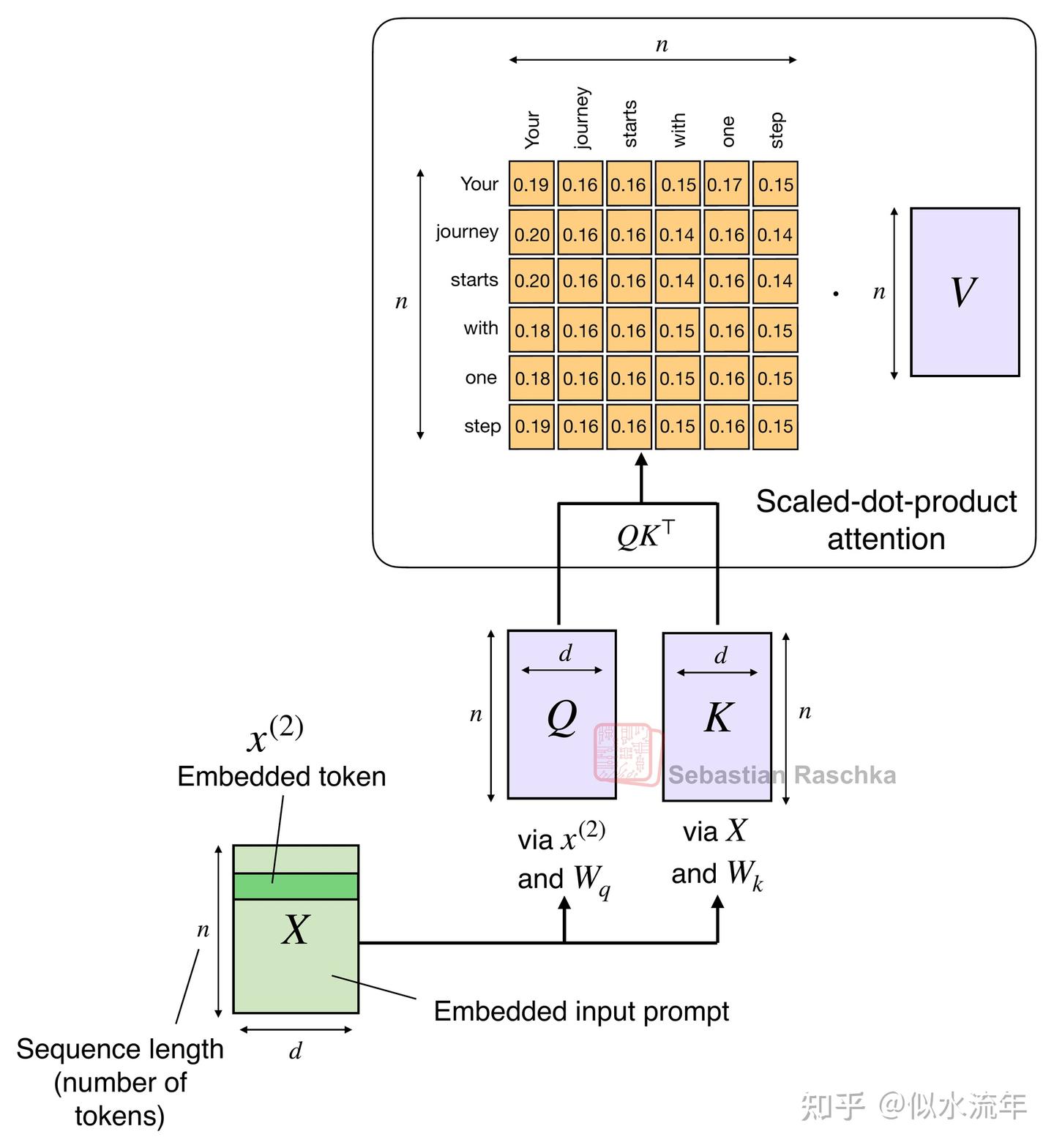
2.1 传统注意力与平方复杂度
原始注意力机制的规模随序列长度呈二次方增长:
这是因为查询(Q)、键(K)和值(V)都是n乘以d的矩阵,其中d是嵌入维度(一个超参数),n是序列长度(即标记的数量)。你可以阅读这篇文章以获取更多的了解 Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article。
2.2 线性注意力
线性注意力的变体已经存在很长时间了,到现在已经有很多相关论文。例如,我最早记得的一篇是2020年的《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》论文,其中研究人员对注意力机制进行了近似处理:
在这里,ϕ(⋅) 是一个核特征函数,设定为 ϕ(x) = elu(x)+1 。
这种近似方法效率很高,因为它避免了显式计算 n×n 的注意力矩阵 QK^T 。
我不想在这些较早的尝试上花费太多时间。但底线是,它们将时间和内存复杂度从 O(n²) 降低到了 O(n),从而极大地提高了长序列上注意力机制的效率。
然而,由于它们降低了模型准确性,这些方法从未真正流行起来,而且我从未见过这些变体以开源权重的最先进大语言模型的形式被应用。
2.3 线性注意力
今年下半年,线性注意力变体出现了复兴,一些模型开发者的相关尝试也如图所示存在一些反复。

首个值得关注的模型是具有闪电注意力机制的MiniMax-M1
MiniMax-M1是一款4560亿参数的专家混合(MoE)模型,其中活跃参数为460亿,该模型于今年6月发布。随后,在8月,Qwen3团队推出了Qwen3-Next,上面已对此进行了更详细的讨论。
接着,在9月,DeepSeek团队宣布了DeepSeek V3.2。(DeepSeek V3.2的稀疏注意力机制在计算成本上并非严格线性,但至少是二次的,因此我认为将其归入与MiniMax-M1、Qwen3-Next和Kimi Linear同一类别是合理的。)
这三个模型(MiniMax-M1、Qwen3-Next、DeepSeek V3.2)在其大部分或所有层中,用高效的线性变体替换了传统的二次注意力变体。
有趣的是,最近出现了一个转折:MiniMax团队发布了其新的230B参数M2模型,该模型未采用线性注意力,而是回归了常规注意力。该团队表示,线性注意力在生产环境中的LLMs中存在挑战。它在常规提示下似乎运行良好,但在推理和多轮任务中的准确性较差,而这些任务不仅对常规聊天会话至关重要,对智能体应用也同样重要。
这可能是一个转折点,表明线性注意力最终可能并不值得追求。然而,事情变得更加有趣了。10月,Kimi团队发布了其新的Kimi Linear模型,该模型采用了线性注意力。
关于线性注意力方面,Qwen3-Next和Kimi Linear均采用了Gated DeltaNet,我想在接下来的几个部分中以混合注意力架构的一个例子来讨论这一点。
2.4 Qwen3-Next
让我们从Qwen3-Next开始,它通过将常规注意力机制替换为Gated DeltaNet + Gated Attention混合机制,在内存使用方面实现了原生262k token上下文长度(之前的235B-A22B模型原生支持32k,通过YaRN扩展支持131k)。
他们的混合机制以图中所示的3:1比例混合Gated DeltaNet块和Gated Attention块。
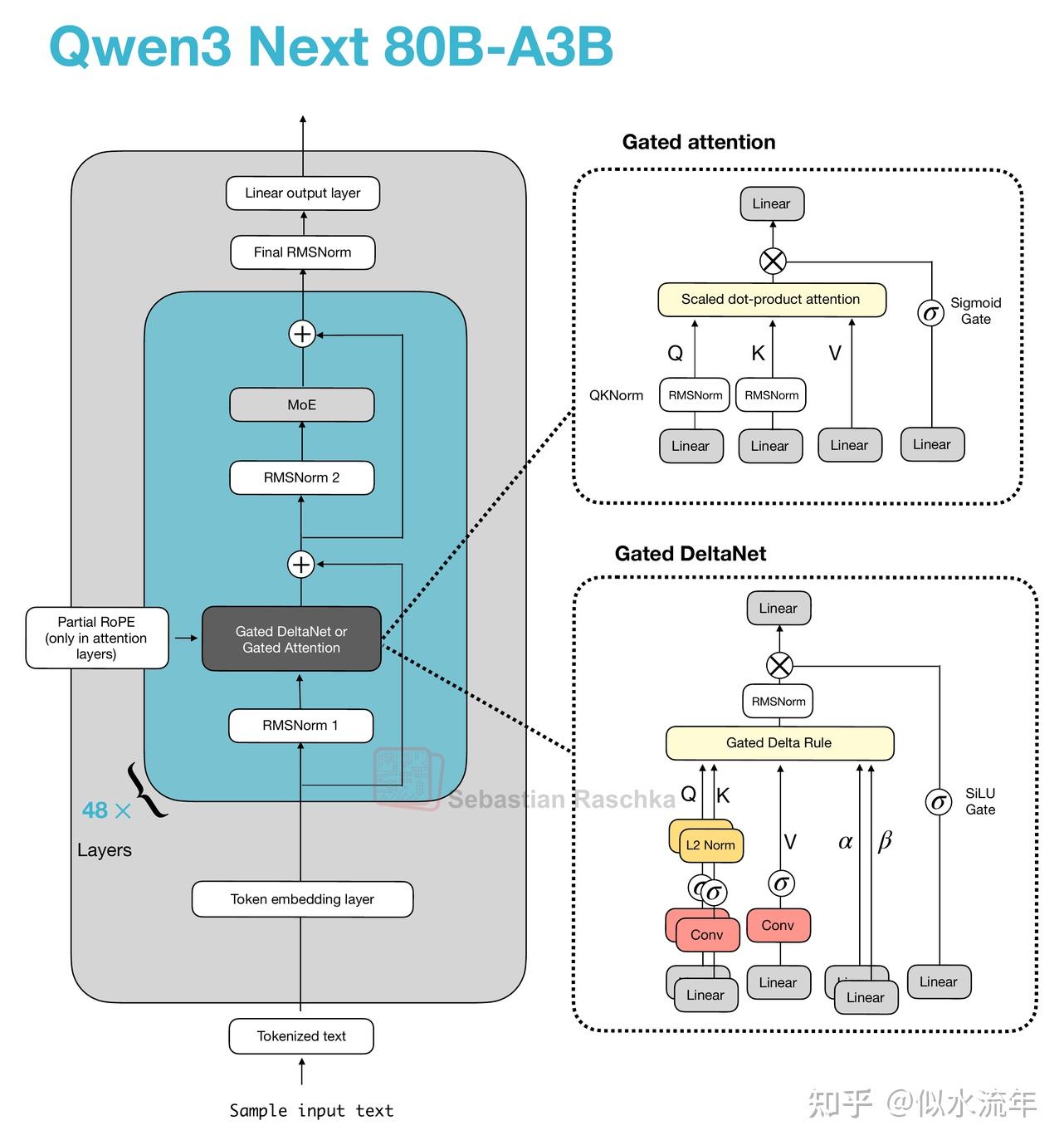
如上图所示,注意力机制在此架构中要么实现为门控注意力,要么实现为Gated DeltaNet。这仅仅意味着该架构中的48个Transformer块(层)会交替使用这两种机制。具体来说,正如前面提到的,它们以3:1的比例交替。例如,Transformer块的排列如下:
──────────────────────────────────
Layer 1 : Linear attention → MoE
Layer 2 : Linear attention → MoE
Layer 3 : Linear attention → MoE
Layer 4 : Full attention → MoE
──────────────────────────────────
Layer 5 : Linear attention → MoE
Layer 6 : Linear attention → MoE
Layer 7 : Linear attention → MoE
Layer 8 : Full attention → MoE
──────────────────────────────────
...
否则,该架构相当标准,与Qwen3类似。
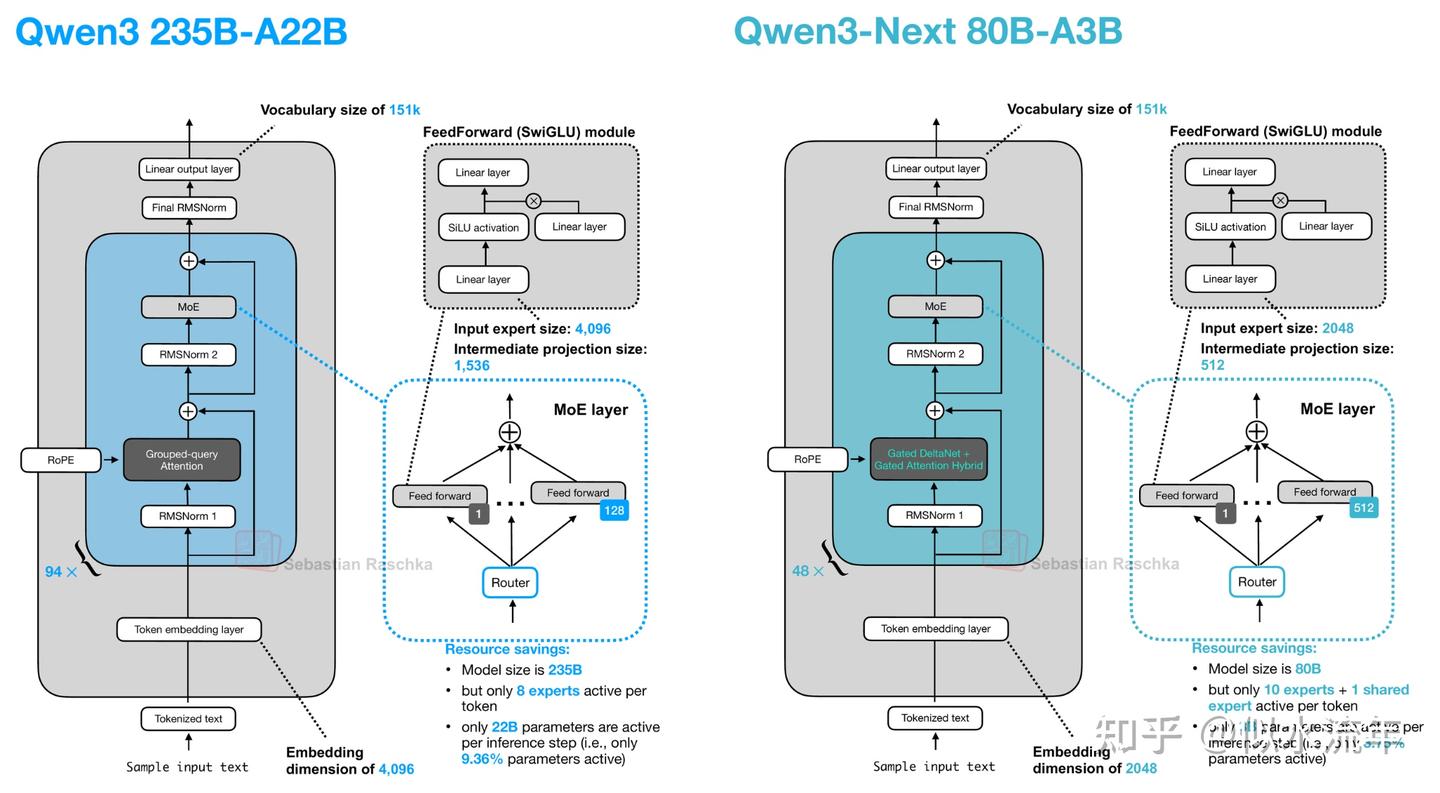
那么,什么是门控注意力和Gated DeltaNet?
2.5 门控注意力
在介绍Gated DeltaNet本身之前,我们先简要谈谈门控机制。如上图Qwen3-Next架构的上半部分所示,Qwen3-Next采用了“门控注意力”机制。这本质上是在常规的全注意力基础上增加了一个sigmoid门控。
这种门控是一种简单的修改,我将其添加到多头注意力(MultiHeadAttention)的实现中,以下为说明目的进行展示:
import torch
from torch import nn
class GatedMultiHeadAttention(nn.Module):
def __init__(
self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False
):
super().__init__()
assert d_out % num_heads == 0
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
####################################################
### NEW: Add gate
self.W_gate = nn.Linear(d_in, d_out, bias=qkv_bias)
####################################################
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length), diagonal=1),
persistent=False,
)
def forward(self, x):
b, num_tokens, _ = x.shape
queries = self.W_query(x)
####################################################
### NEW: Add gate
gate = self.W_gate(x)
####################################################
keys = self.W_key(x)
values = self.W_value(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
attn_scores = queries @ keys.transpose(2, 3)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(
mask_bool, torch.finfo(attn_scores.dtype).min
)
attn_weights = torch.softmax(
attn_scores / (self.head_dim ** 0.5), dim=-1
)
attn_weights = self.dropout(attn_weights)
context = (attn_weights @ values).transpose(1, 2)
context = context.reshape(b, num_tokens, self.d_out)
####################################################
### NEW: Add gate
context = context * torch.sigmoid(gate)
####################################################
out = self.out_proj(context)
return out
正如我们所见,在像以往一样计算注意力之后,该模型使用来自同一输入的单独门控信号,对其应用sigmoid函数以将其保持在0到1之间,并将其与注意力输出相乘。这使模型能够动态地放大或缩小某些特征。Qwen3-Next的开发人员表示,这有助于提高训练稳定性:
[…] the attention output gating mechanism helps eliminate issues like Attention Sink and Massive Activation, ensuring numerical stability across the model.
简而言之,门控注意力会调节标准注意力的输出。在下一节中,我们将讨论Gated DeltaNet,它用递归的delta规则记忆更新来替代注意力机制本身。
2.6 Gated DeltaNet
那么,什么是Gated DeltaNet?Gated DeltaNet(全称为Gated Delta Network)是Qwen3-Next的线性注意力层,旨在作为标准softmax注意力的替代方案。
它源自前面提到的《Gated Delta Networks: Improving Mamba2 with Delta Rule》一文。
Gated DeltaNet最初被提出作为Mamba2的改进版本,它结合了Mamba2的门控衰减机制和delta规则。
Mamba是一种状态空间模型(transformer的替代方案),这是一个值得未来单独深入探讨的重要主题。
delta规则部分指的是计算新值与预测值之间的差值(delta,Δ),以更新用作记忆状态的隐藏状态(稍后将详细介绍这一点)。
熟悉经典机器学习文献的读者可以将其类比为受生物学启发的Hebbian learning:“Cells that fire together wire together.”。这基本上是感知机更新规则和基于梯度下降的学习方法的前身,但无需监督。
Gated DeltaNet具有一种与前面讨论的门控注意力中的门类似的结构,不过它使用的是SiLU激活函数,而非逻辑sigmoid激活函数,如下图所示。(选择SiLU的原因可能是为了在标准sigmoid之上改善梯度流动和稳定性。)
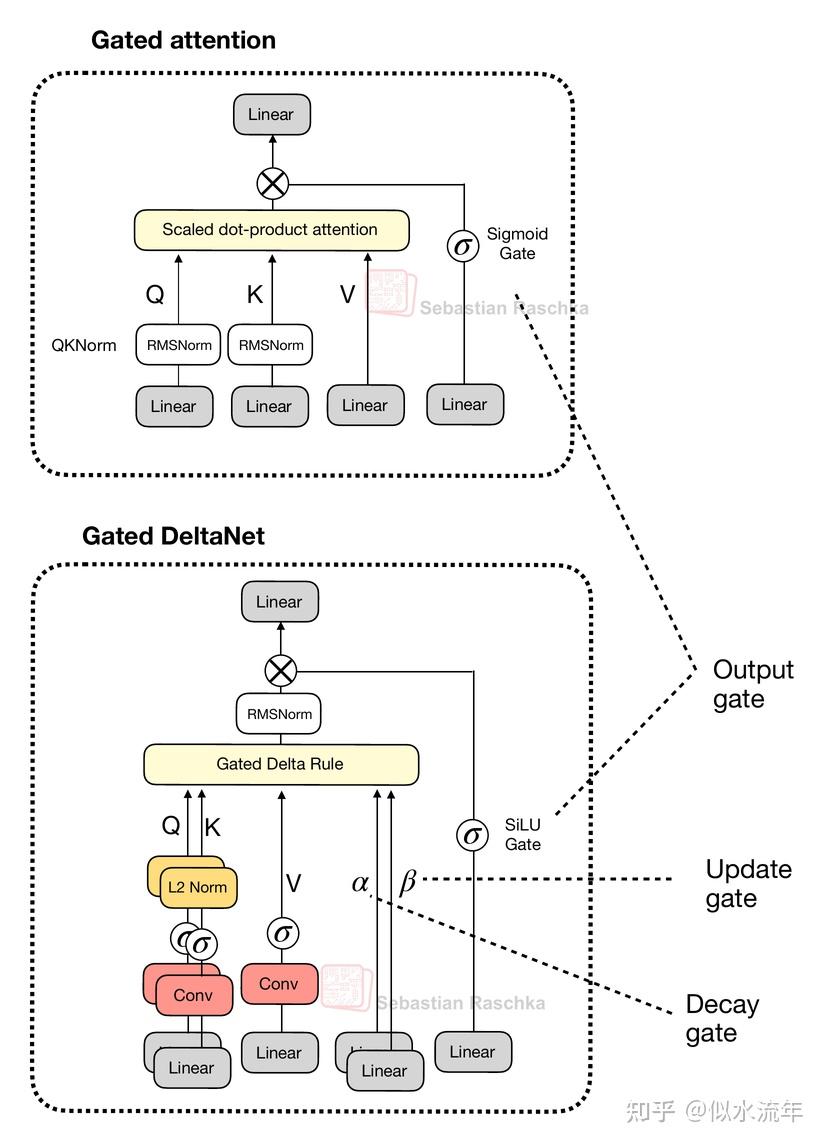
然而,如上图所示,在输出门旁边,Gated DeltaNet中的“门控”还指代几个额外的门:
- α(衰减门)控制记忆随时间衰减或重置的速度
- β(更新门)控制新输入修改状态的强度
在代码中,可以实现上述Gated DeltaNet的简化版本(不包含卷积混合部分),如下所示(该代码受Qwen3团队官方实现的启发):
import torch
from torch import nn
import torch.nn.functional as F
def l2norm(x, dim=-1, eps=1e-6):
return x * torch.rsqrt((x**2).sum(dim=dim, keepdim=True) + eps)
class GatedDeltaNet(nn.Module):
def __init__(
self,
d_in,
d_out,
dropout,
num_heads,
qkv_bias=False
):
super().__init__()
assert d_out % num_heads == 0
self.d_out = d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
### NEW: Gates for delta rule and output gating
self.W_gate = nn.Linear(d_in, d_out, bias=False)
self.W_beta = nn.Linear(d_in, d_out, bias=False)
# Note: The decay gate alpha corresponds to
# A_log + W_alpha(x) + dt_bias
self.W_alpha = nn.Linear(d_in, num_heads, bias=False)
self.dt_bias = nn.Parameter(torch.ones(num_heads))
self.A_log = nn.Parameter(torch.zeros(num_heads))
# We could implement this as:
# W_alpha = nn.Linear(d_in, num_heads, bias=True)
# but the bias is separate for interpretability
# and to mimic the official implementation
self.norm = nn.RMSNorm(self.head_dim, eps=1e-6)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
b, num_tokens, _ = x.shape
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
### NEW: Compute delta rule gates
beta = torch.sigmoid(self.W_beta(x))
alpha = -self.A_log.exp().view(1, 1, -1) * F.softplus(
self.W_alpha(x) + self.dt_bias
)
gate = self.W_gate(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
beta = beta.view(b, num_tokens, self.num_heads, self.head_dim)
gate = gate.view(b, num_tokens, self.num_heads, self.head_dim) # NEW
keys = keys.transpose(1, 2)
queries = queries.transpose(1, 2)
values = values.transpose(1, 2)
beta = beta.transpose(1, 2)
gate = gate.transpose(1, 2) # NEW
### NEW: QKNorm-like normalization for delta rule
queries = l2norm(queries, dim=-1) / (self.head_dim ** 0.5)
keys = l2norm(keys, dim=-1)
S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)
outs = []
### NEW: Gated delta rule update
for t in range(num_tokens):
k_t = keys[:, :, t]
q_t = queries[:, :, t]
v_t = values[:, :, t]
b_t = beta[:, :, t]
a_t = alpha[:, t].unsqueeze(1).unsqueeze(-1)
S = S * a_t.exp()
kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)
delta = (v_t - kv_mem) * b_t
S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)
outs.append(y_t)
context = torch.stack(outs, dim=2).transpose(1, 2).contiguous()
context = context.view(b, num_tokens, self.num_heads, self.head_dim)
### NEW: Apply RMSNorm and SiLU gate
context = self.norm(context)
context = context * F.silu(gate)
context = context.view(b, num_tokens, self.d_out)
context = self.dropout(context)
out = self.out_proj(context)
return out
(为简化起见,这里省略了Qwen3-Next和Kimi Linear使用的卷积混合部分,以便代码更易读,并专注于循环方面。)
因此,正如我们上面所看到的,它与标准(或门控)注意力存在诸多差异。
在门控注意力中,模型计算所有标记之间的正常注意力(每个标记都关注或查看其他每个标记)。然后,在获得注意力输出后,一个门(一个sigmoid函数)决定保留多少该输出。关键在于,它仍然是与上下文长度呈平方增长的标准缩放点积注意力。
作为回顾,缩放点积注意力的计算方式为 softmax(QK^T)V ,其中Q和K是 n\times d 的矩阵,n是输入标记的数量,d是嵌入维度。因此, QK^T 会产生一个 n \times n 的注意力矩阵,该矩阵再与 n\times d 维的值矩阵V相乘。

在Gated DeltaNet中,不存在n乘n的注意力矩阵。相反,模型逐个处理标记。它维护一个运行中的记忆(状态),该状态会随着每个新标记的输入而更新。这通过以下方式实现,其中S是在每个时间步t递归更新的状态。
S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)
outs = []
### NEW: Gated delta rule update
for t in range(num_tokens):
k_t = keys[:, :, t]
q_t = queries[:, :, t]
v_t = values[:, :, t]
b_t = beta[:, :, t]
a_t = alpha[:, t].unsqueeze(1).unsqueeze(-1)
S = S * a_t.exp()
kv_mem = (S * k_t.unsqueeze(-1)).sum(dim=-2)
delta = (v_t - kv_mem) * b_t
S = S + k_t.unsqueeze(-1) * delta.unsqueeze(-2)
y_t = (S * q_t.unsqueeze(-1)).sum(dim=-2)
outs.append(y_t)
门控控制该记忆的变化方式:
- α调节遗忘旧记忆(衰减)的程度。
- β调节在时间步t当前标记更新记忆的程度。
(最终输出门未在上述代码片段中显示,它类似于门控注意力,控制保留输出的程度。)
因此,从某种意义上说,Gated DeltaNet中的这种状态更新类似于循环神经网络(RNNs)的工作方式。其优势在于,它通过循环实现线性扩展,而非与上下文长度成二次关系。这种循环状态更新的缺点是,与常规(或门控)注意力相比,它牺牲了来自完整成对注意力的全局上下文建模能力。
Gated DeltaNet在一定程度上仍能捕捉上下文,但必须通过记忆(S)瓶颈。该记忆具有固定大小,因此更高效,但它会将过去的上下文压缩到单个隐藏状态中,类似于RNNs。
这就是为什么Qwen3-Next和Kimi Linear架构没有用DeltaNet层替换所有注意力层,而是采用前面提到的3:1比例的原因。
2.7 DeltaNet 内存节省
在上一节中,我们讨论了DeltaNet相对于全注意力的优势,即在上下文长度方面的计算复杂度是线性的而非二次的。
除了线性计算复杂度外,DeltaNet的另一个重大优势是内存节省,因为DeltaNet模块不会扩展KV缓存。(有关KV缓存的更多信息,请参见我的KV Cache详解+从0开始实现(附代码)一文)。相反,正如前面提到的,它们保持固定大小的循环状态,因此内存使用量与上下文长度无关而保持恒定。
对于一个常规的多头注意力(MHA)层,我们可以按以下方式计算KV缓存的大小:
KV_cache_MHA ≈ batch_size × n_tokens × n_heads × d_head × 2 × bytes
乘数为2是因为我们在缓存中存储了键和值。
对于上述实现的简化版DeltaNet,我们有:
KV_cache_DeltaNet = batch_size × n_heads × d_head × d_head × bytes
请注意,KV_cache_DeltaNet的内存大小不依赖于上下文长度(n_tokens)。此外,我们存储的是记忆状态S,而不是单独的键和值,因此2×bytes就变成了字节。然而,请注意我们现在这里有一个二次项d_head×d_head。这来自于状态:
S = x.new_zeros(b, self.num_heads, self.head_dim, self.head_dim)
但通常这没什么可担心的,因为头部维度通常相对较小。例如,在Qwen3-Next中它是128。
带有卷积混合的完整版本要复杂一些,包括核大小等,但上面的公式应该能说明Gated DeltaNet背后的主要趋势和动机。

2.8 Kimi Linear vs. Qwen3-Next
Kimi Linear 与 Qwen3-Next 在结构上存在若干相似之处。这两种模型均依赖混合注意力策略。
具体而言,它们将轻量级线性注意力与更重的全注意力层相结合,两者均采用 3:1 的比例,即每三个采用线性 Gated DeltaNet 变体的 transformer 块中,就有一个块使用全注意力,如下图所示。
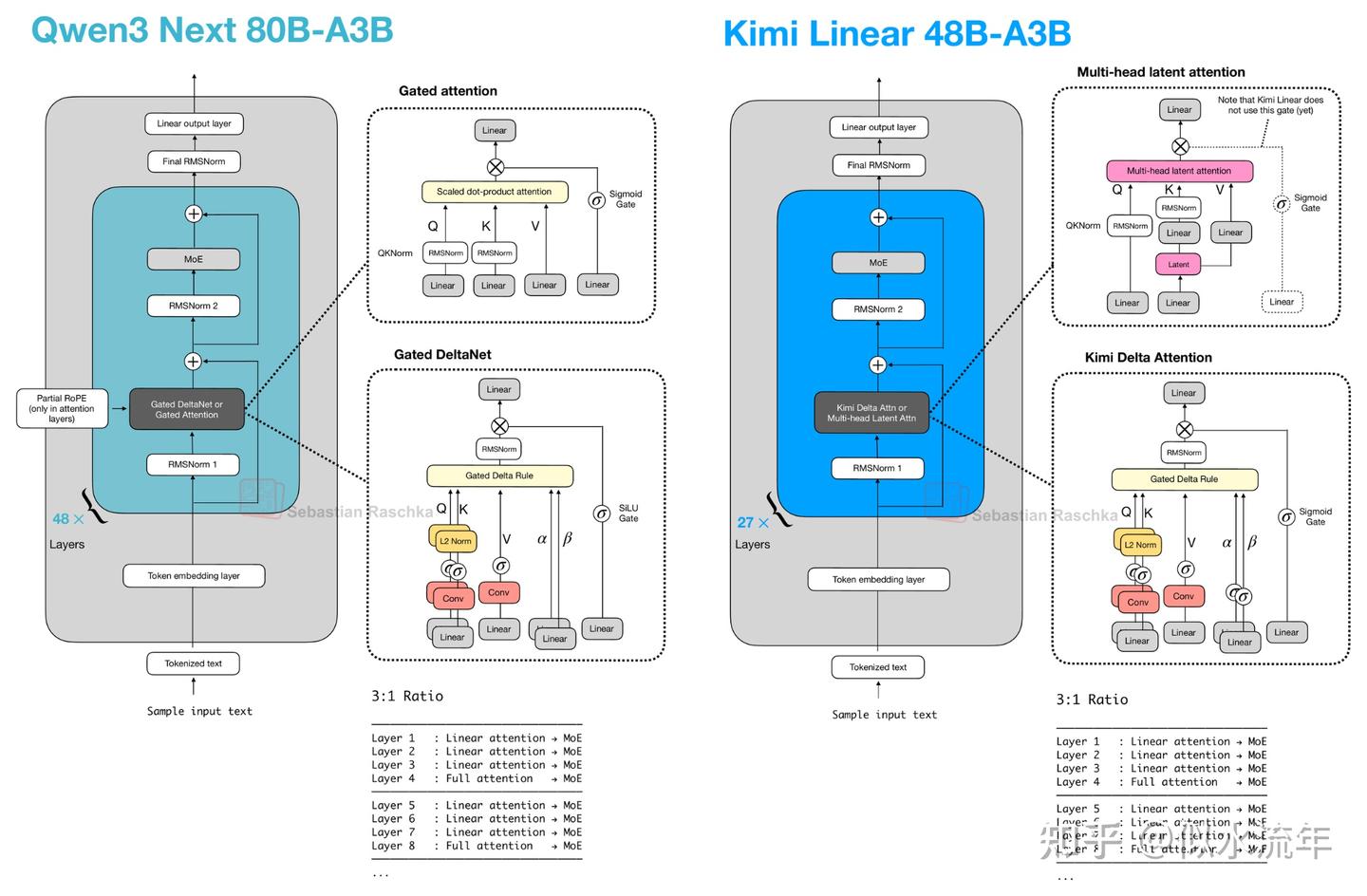
Gated DeltaNet 是一种受循环神经网络启发的线性注意力变体,其中包含来自《Gated Delta Networks: Improving Mamba2 with Delta Rule》论文的门控机制。从某种意义上说,Gated DeltaNet 是一种具有 Mamba 风格门控的 DeltaNet,而 DeltaNet 本身是一种线性注意力机制(相关内容将在下一节详述)。
图 11 右上角框中所示的 Kimi Linear 中的 MLA 并未使用 sigmoid 门控。这种省略是刻意为之,以便作者能更直接地将该架构与标准 MLA 进行比较;不过他们表示未来计划添加该门控。
此外,还需注意,上述图表中 Kimi Linear 部分省略 RoPE 框也是有意为之。Kimi 在多头潜在注意力(MLA)层(全局注意力)中应用了 NoPE(无位置嵌入)。
正如作者所述,这使得 MLA 在推理时能够以纯多查询注意力方式运行,并避免了为长上下文扩展而对 RoPE 进行微调(据称位置偏置由 Kimi Delta 注意力块处理)。
2.9 Kimi Delta Attention
Kimi Linear 通过 Kimi Delta 注意力(KDA)机制修改了 Qwen3-Next 的线性注意力机制,该机制本质上是对 Gated DeltaNet 的改进。
与 Qwen3-Next 为每个注意力头应用标量门控(一个值)来控制记忆衰减率不同,Kimi Linear 将其替换为针对每个特征维度的通道级门控。
据作者称,这能提供对记忆的更精细控制,进而提升长上下文推理能力。
此外,对于全注意力层,Kimi Linear 将 Qwen3-Next 的门控注意力层(本质上是带有输出门控的标准多头注意力层)替换为多头潜在注意力(MLA)。
这是一种与 DeepSeek V3/R1 使用的相同 MLA 机制,但增加了额外的门控。(简要回顾一下,MLA 通过压缩键/值空间来减小 KV 缓存大小。)
虽然没有直接与 Qwen3-Next 进行比较,但与 Gated DeltaNet 论文中的 Gated DeltaNet-H1 模型(本质上是带有滑动窗口注意力的 Gated DeltaNet)
相比,Kimi Linear 在保持相同 token 生成速度的同时,实现了更高的建模准确性。
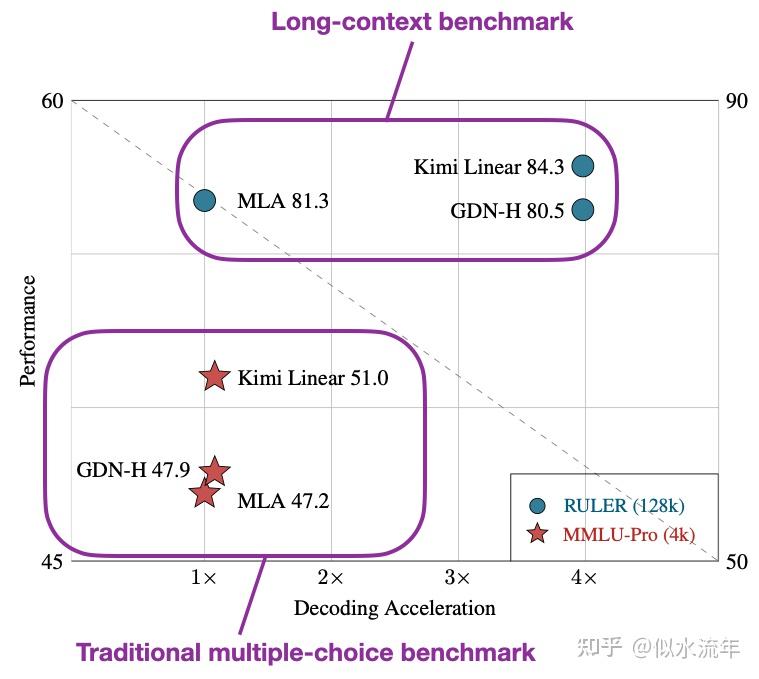
此外,根据DeepSeek-V2论文中的消融研究,当仔细选择超参数时,多粒度线性注意力(MLA)的性能可与常规全注意力相媲美。
而Kimi Linear在长上下文和推理基准测试中表现优于MLA的事实,再次使线性注意力变体成为更大规模最先进模型的有前景的选择。
话虽如此,Kimi Linear是一个480亿参数的大模型,但其规模仅为Kimi K2的1/20。有趣的是,看看Kimi团队是否会将这种方法应用于他们即将推出的K3模型。
2.10 混合注意力的未来
线性注意力并非新概念,但混合方法的近期复兴表明,研究人员正再次认真探索使Transformer更高效的实际途径。
例如,Kimi Linear与常规全注意力相比,KV缓存减少了75%,解码吞吐量最高可达6倍。
新一代线性注意力变体与早期尝试的不同之处在于,它们现在是与标准注意力结合使用,而非完全取代标准注意力。
展望未来,我预计下一波注意力混合方法将专注于进一步提升长上下文稳定性和推理准确性,使其更接近全注意力的最先进水平。
3. 文本扩散模型
与标准的自回归大型语言模型架构相比,文本扩散模型家族是一种更为激进的偏离。
你可能对扩散模型有所了解,这类模型基于2020年发表的Denoising Diffusion Probabilistic Models论文,用于生成图像(作为生成对抗网络的继任者),后来由Stable Diffusion等工具实现了、扩展了并普及开来。

3.1 为什么要研究文本扩散?
随着2022年Diffusion‑LM Improves Controllable Text Generation论文的发表,我们开始看到一种趋势的开端:研究人员开始采用扩散模型来生成文本。到了2025年,我看到了大量关于文本扩散的论文。鉴于这些模型日益普及,我认为现在终于到了讨论它们的时候了。
那么,扩散模型的优势是什么,为什么研究人员将其视为传统自回归大语言模型(LLMs)的替代方案呢?
基于传统Transformer的(自回归)大语言模型一次生成一个token。为简洁起见,我们将其简称为自回归大语言模型。
现在,基于文本扩散的大语言模型(让我们称之为“扩散大语言模型”)的主要卖点在于,它们可以并行生成多个tokens,而不是依次生成。
需要注意的是,扩散大语言模型仍然需要多个去噪步骤。
然而,即使扩散模型在每一步需要64个去噪步骤来并行生成所有tokens,这在计算上仍然比执行2000个顺序生成步骤来生成一个包含2000个tokens的响应更高效。
3.2 去噪过程
扩散语言模型(diffusion LLM)中的去噪过程,类似于常规图像扩散模型中的去噪过程,如下图GIF所示。(关键区别在于,文本扩散不是通过向像素添加高斯噪声来破坏序列,而是通过概率性地掩码标记来实现。)
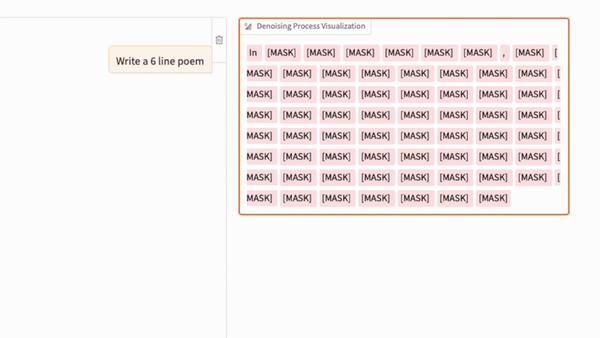
正如我们在上面的动画中所看到的,文本扩散过程依次用文本标记替换[MASK]标记以生成答案。如果您熟悉BERT和掩码语言建模,可以将此扩散过程视为BERT前向传递的迭代应用(其中BERT使用不同的掩码率)。
从架构上看,扩散大语言模型(LLMs)通常是解码器风格的Transformer,但没有因果注意力掩码。例如,前述的LLaDA模型使用Llama 3架构。
我们将那些没有因果掩码的架构称为“双向”架构,因为它们可以一次性访问所有序列元素。(请注意,这与BERT架构类似,由于历史原因,BERT被称为“编码器风格”。)
因此,自回归大语言模型与扩散大语言模型之间的主要区别(除移除因果掩码外)是训练目标。像LLaDA这样的扩散大语言模型使用生成式扩散目标,而不是下一个标记预测目标。
在图像模型中,生成式扩散目标很直观,因为我们有一个连续的像素空间。例如,添加高斯噪声并学习去噪在数学上是自然的操作。然而,文本由离散标记组成,因此我们不能以相同的连续方式直接添加或移除“噪声”。
因此,这些扩散大语言模型不是通过扰动像素强度来破坏文本,而是通过随机逐步掩码标记来破坏文本,其中每个标记以指定概率被特殊掩码标记替换。
模型然后学习一个反向过程,在每一步预测缺失的标记,这有效地将序列“去噪”(或取消掩码)回原始文本,如图15动画所示。
解释其背后的数学原理更适合单独的教程,但大致来说,我们可以将其视为扩展到概率最大似然框架的BERT。
3.3 自回归与扩散大语言模型
之前我说过,扩散式大型语言模型(LLMs)之所以具有吸引力,是因为它们能够并行生成(或去噪)标记,而不是像传统的自回归大型语言模型那样按顺序生成。这使得扩散模型有可能比自回归大型语言模型更高效。
不过,传统大型语言模型的自回归特性也是其关键优势之一。而纯并行解码存在的问题,可以从最近ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs论文中的一个出色例子中得到说明。
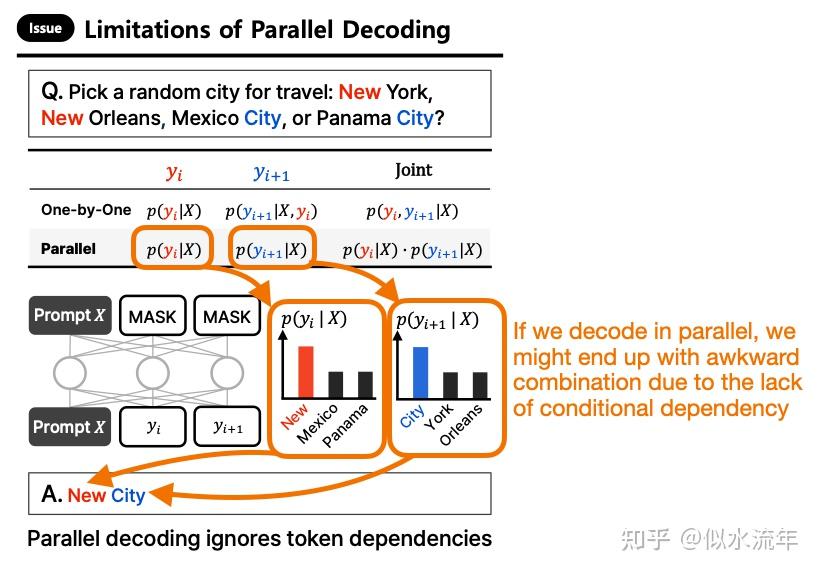
例如,给出以下提示:
“Pick a random city for travel: New York, New Orleans, Mexico City, or Panama City?”
假设我们要求LLM生成一个双词答案。它可能会首先根据条件概率 p(y_t="New"∣X) 采样出“New”这个token。
在下一次迭代中,它将根据先前生成的标记进行条件判断,并很可能选择“York”或“Orleans”,因为这两个选项的条件概率
,
都相对较高(因为在训练集中,“New”经常与这些后续内容共同出现)。但如果两个标记是并行采样的,模型可能会独立选择概率最高的两个标记 p(y_t="New"∣X) , p(y_{t+1}="City"∣X) ,这会导致诸如“New City”之类的生硬输出。(这是因为模型缺乏自回归条件控制,无法捕捉token之间的依赖关系。)
无论如何,上述说法是对扩散式大型语言模型(diffusion LLMs)的简化,使其听起来似乎完全没有条件依赖关系。这并不准确。如前所述,扩散式大型语言模型会并行预测所有token,但这些预测通过迭代精炼(去噪)步骤相互依赖。
在此过程中,每一步扩散都会基于当前整个含噪声的文本进行条件控制。此外,token通过每一步中的交叉注意力和自注意力机制相互影响。因此,即使所有位置的更新是同时进行的,这些更新也通过共享的注意力层相互条件控制。
然而,正如前面提到的,在理论上,生成一个包含2000个token的答案时,20到60步的扩散过程可能比自回归大型语言模型的2000步推理过程更高效。
3.4 当前的文本扩散模型
这是一个有趣的趋势:视觉模型正在采用类似LLM的注意力机制以及Transformer架构本身,而基于文本的LLM则受到纯视觉模型的启发,开始实现文本扩散。
我认为这是一把双刃剑,如果我们使用较少的扩散步骤,生成答案的速度会更快,但答案质量可能会下降。如果我们增加扩散步骤以生成更好的答案,最终得到的模型成本可能会与自回归模型相当。
引用论文 ParallelBench: Understanding the Trade-offs of Parallel Decoding in Diffusion LLMs 作者的话:
[…] we systematically analyse both [diffusion LLMs] and autoregressive LLMs, revealing that: (i) [diffusion LLMs] under parallel decoding can suffer dramatic quality degradation in real-world scenarios, and (ii) current parallel decoding strategies struggle to adapt their degree of parallelism based on task difficulty, thus failing to achieve meaningful speed-up without compromising quality.
翻译:我们对扩散大语言模型和自回归大语言模型进行了系统性分析
揭示出以下两点:
- (i)在并行解码下,扩散大语言模型在现实场景中可能会出现显著的质量下降;
- (ii)当前的并行解码策略难以根据任务难度调整其并行程度
因此在不牺牲质量的前提下无法实现有意义的速度提升。
此外,我看到的另一个特定缺点是,扩散式大型语言模型(LLMs)由于不存在“链”结构,因此无法将其作为链的一部分来使用工具。或许可以在扩散步骤之间交错使用它们,但我认为这并非易事。(如果我错了,请指正。)
简而言之,扩散式大型语言模型似乎是一个值得探索的有趣方向,但目前它们可能无法取代自回归式大型语言模型。
不过,我认为它们可以作为小型设备端大型语言模型的有趣替代方案,或者可能取代小型蒸馏自回归式大型语言模型。例如,谷歌宣布正在开发一个用于文本的Gemini Diffusion,在其中他们提到
Rapid response: Generates content significantly faster than even our fastest model so far.
翻译:快速响应:生成内容的速度比我们迄今为止最快的模型还要快得多。
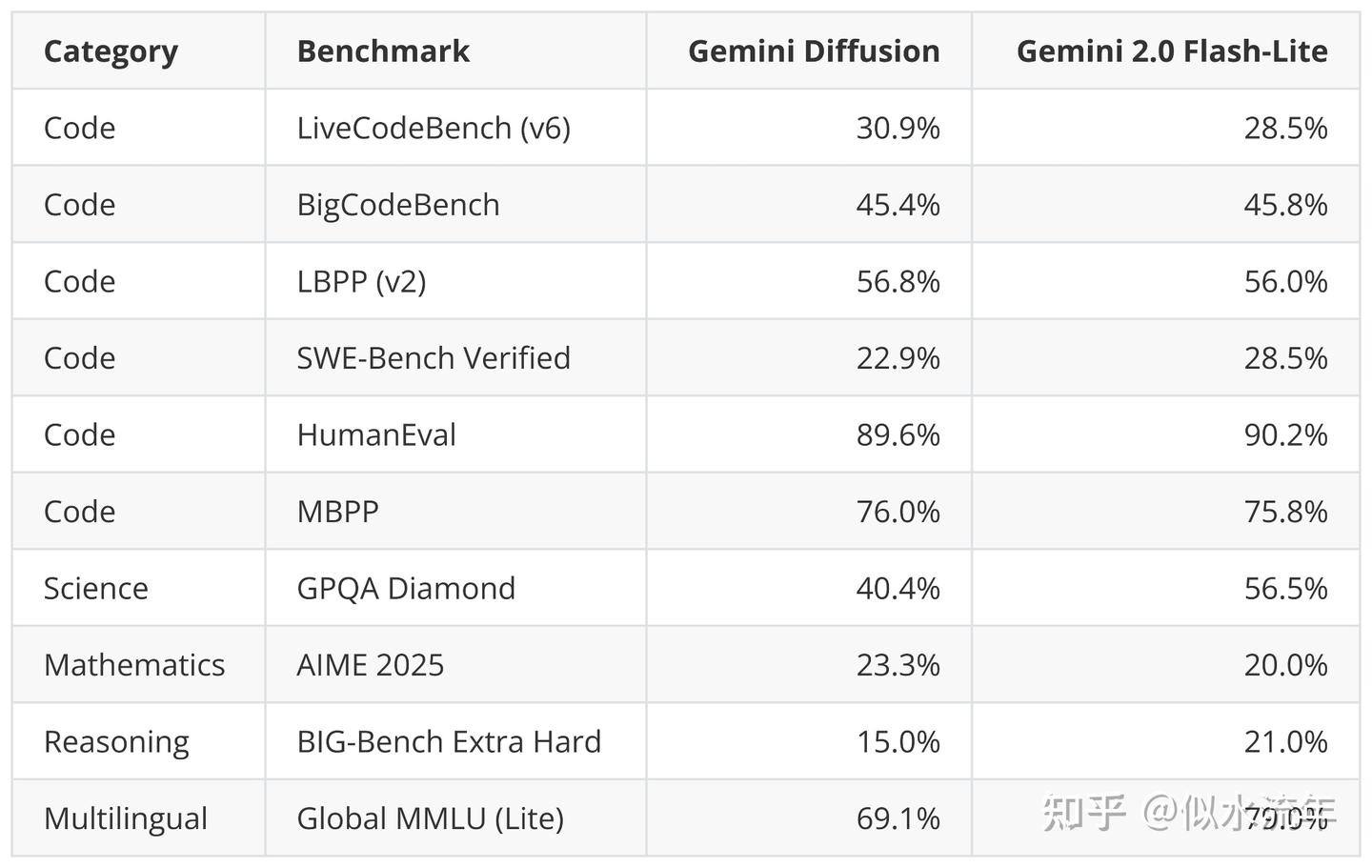
尽管速度更快,但该模型的基准性能似乎与它们快速的Gemini 2.0 Flash-Lite模型相当。一旦模型发布,用户在不同任务和领域对其进行尝试后,其采用情况和反馈将很有趣。
4. 世界模型
到目前为止,我们讨论的方法主要集中在提高效率,使模型更快或更具可扩展性。而这些方法通常会导致建模性能略有下降。
现在,本节的主题将从不同角度切入,专注于提升建模性能(而非效率)。这种性能的提升是通过让模型具备“对世界的理解”来实现的。
世界模型传统上是独立于语言建模发展的,但2025年9月发表的Code World Models论文首次将它们直接与这一领域相关联。
理想情况下,与本文其他主题类似,世界模型本身值得一篇完整的文章(甚至是一本书)来专门阐述。然而,在我们深入探讨Code World Models(CWM)论文之前,让我先简要介绍一下世界模型。
4.1 世界模型背后的核心思想
最初,世界模型的理念是隐式地建模结果,即在结果实际发生之前就预测可能发生的情况(如下图所示)。
这类似于人类大脑如何基于以往经验持续预测即将到来的事件。例如,当我们伸手去拿一杯咖啡或茶时,大脑已经预测了它的重量感,并在我们甚至还没触摸或拿起杯子之前就调整了握力。
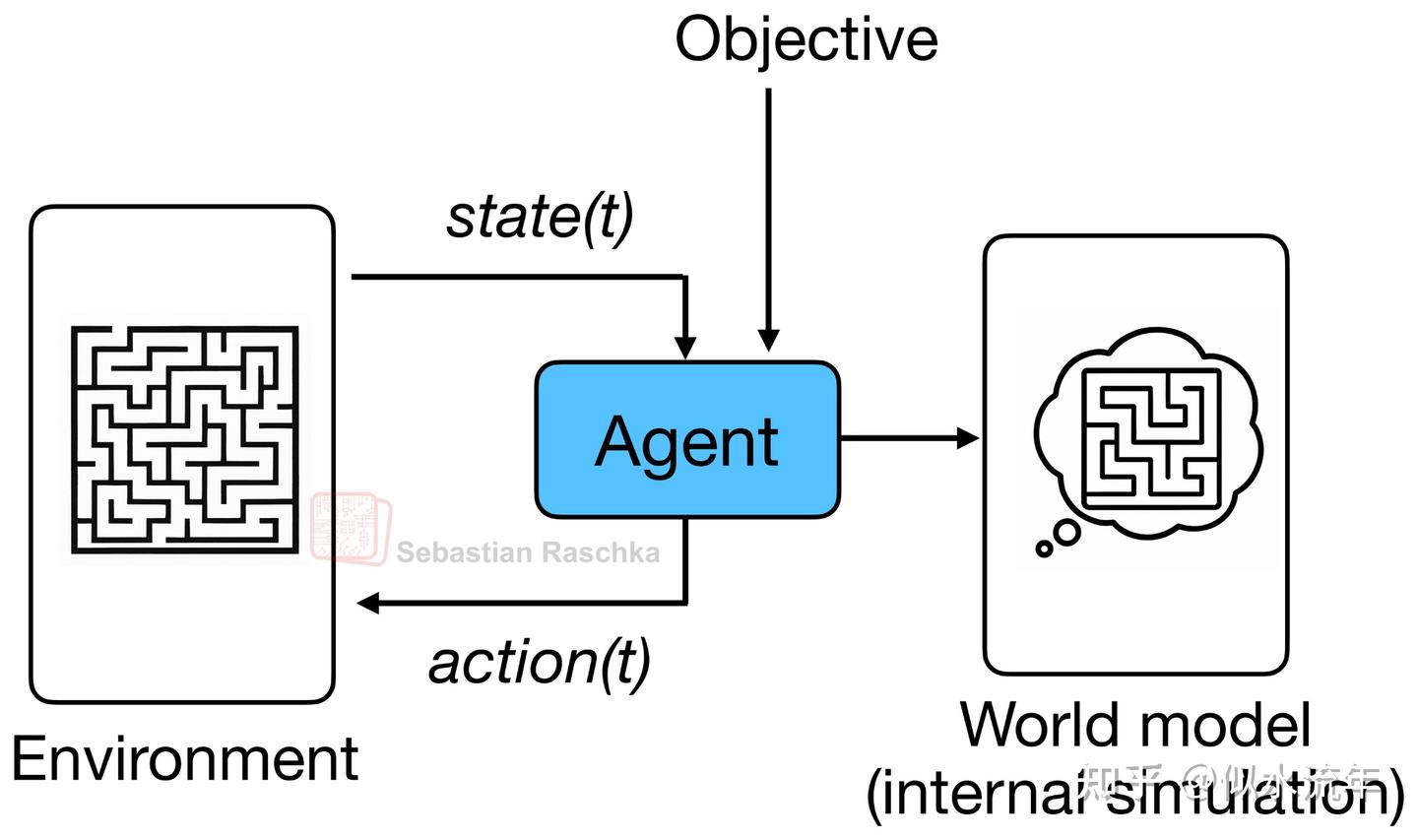
据我所知,“世界模型”这一术语是由Ha和Schmidhuber于2018年发表的同名论文World Models推广开来的,该论文使用变分自编码器(VAE)加循环神经网络(RNN)架构,为强化学习智能体学习内部环境模拟器。但该术语或概念本身本质上只是指对世界或环境的概念进行建模,因此其起源可追溯至20世纪80年代的强化学习和机器人研究领域。
坦白说,在Yann LeCun 2022年的文章A Path Towards Autonomous Machine Intelligence出现之前,我对世界模型的新解读并未引起我的关注。该文章本质上是探讨一条不同于大型语言模型(LLMs)的AI替代发展路径。
4.2 从视觉到代码
话虽如此,世界模型论文此前主要集中在视觉领域,涵盖了多种架构:从早期基于VAE和RNN的模型,到如今的Transformer、扩散模型,甚至是Mamba层混合架构。
而现在,作为一名更专注于大语言模型(LLMs)的研究者,Code World Model(2025年9月30日)这篇论文是第一篇能完全吸引我注意力的论文(此处无双关之意)。据我所知,这是首个能够从文本映射到文本(或更准确地说,从代码映射到代码)的世界模型。
CWM是一个拥有320亿参数的开源权重模型,上下文窗口长度为131k tokens。在架构上,它仍然是一种仅含解码器的密集型Transformer,采用滑动窗口注意力机制。此外,与其他大语言模型类似,它也经历了预训练、中训练、监督微调(SFT)以及强化学习等阶段,但中训练数据引入了世界建模组件。
4.3 代码世界模型与常规大语言模型在代码方面的对比
那么,这与常规的代码大语言模型(如Qwen3-Coder)有何不同呢?
像Qwen3-Coder这样的常规模型仅通过下一个 token 的预测进行训练。它们学习语法和逻辑的模式,以生成看似合理的代码补全,从而具备编程的静态文本级理解能力。
相比之下,CWM 学习模拟代码运行时会发生的情况。它被训练用于预测执行操作(如修改一行代码)后产生的程序状态,例如变量的值,如下图所示。
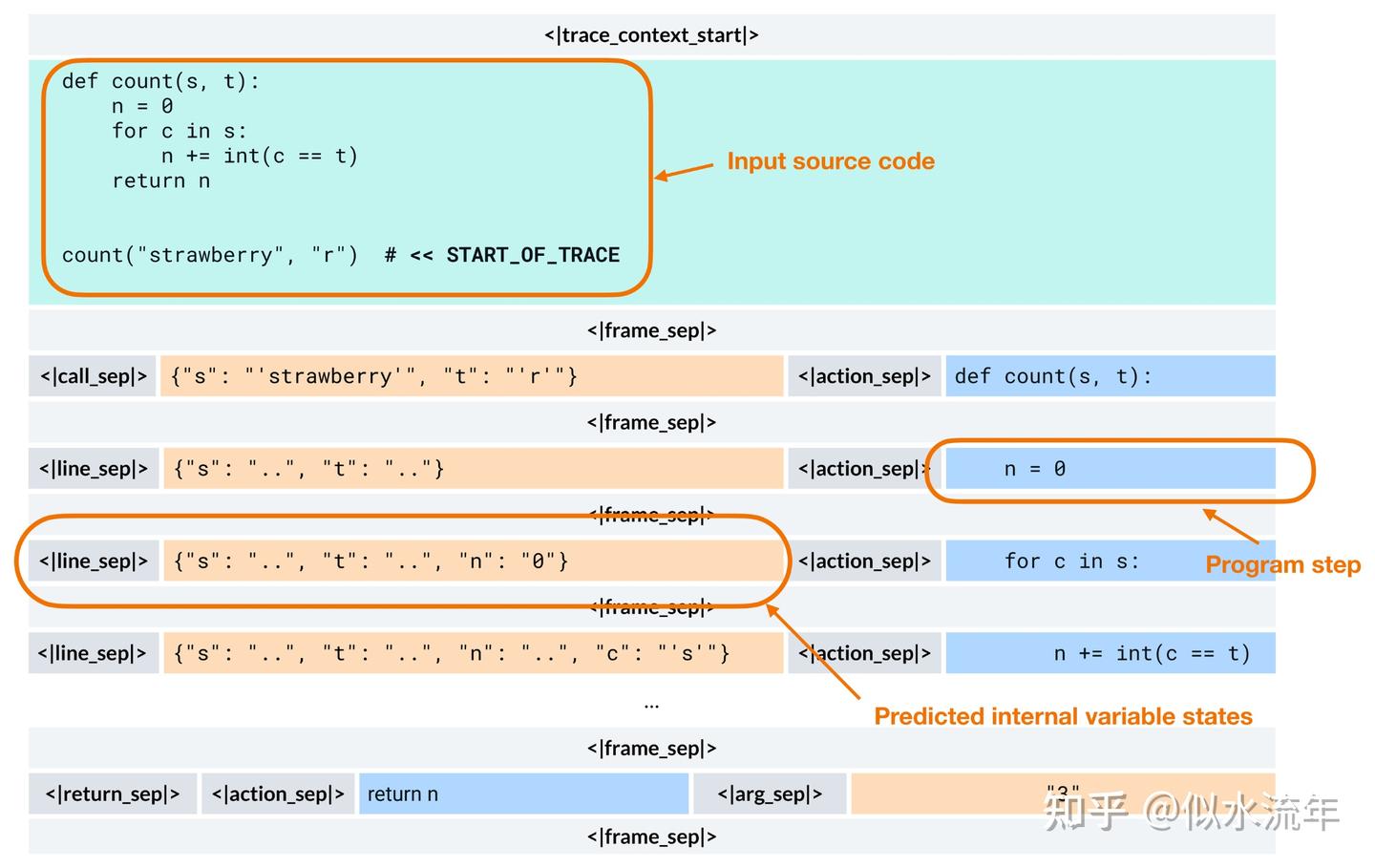
在推理阶段,CWM 仍然是一种自回归式 Transformer,像 GPT 风格的模型一样逐个生成 token。关键区别在于,这些 token 可以编码结构化的执行轨迹,而不仅仅是纯文本。
因此,我可能不会称其为“世界模型”,而是“增强世界模型的大型语言模型”。
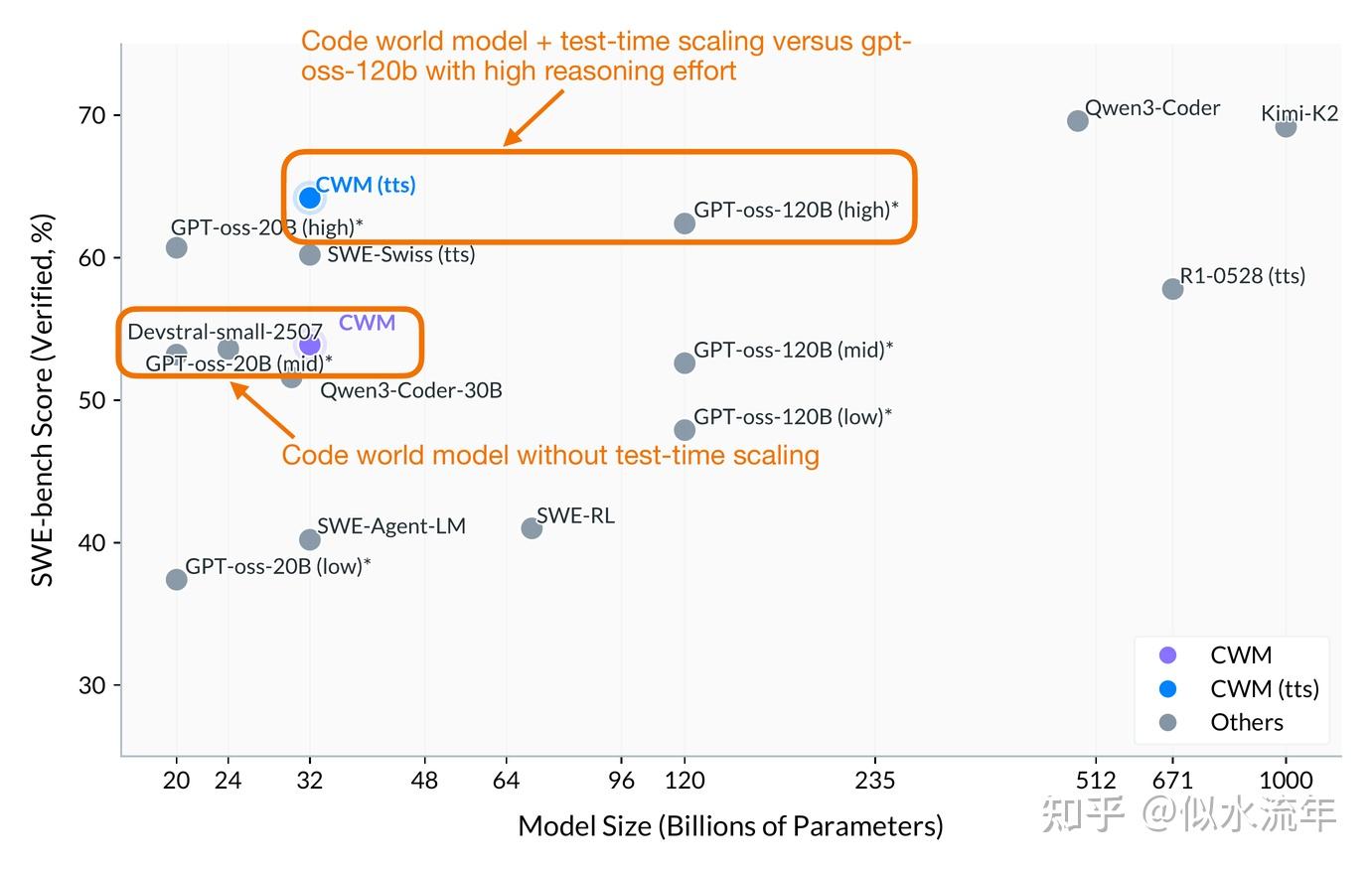
作为首次尝试,它的表现令人惊讶地出色,在大致相同规模下与 gpt-oss-20b(中等推理强度)相当。
如果使用推理时扩展技术,它甚至在推理强度较高时的表现略优于 gpt-oss-120b,同时体积小 4 倍。
需要注意的是,他们的推理时扩展采用了带有生成单元测试的 best@k 程序(可理解为一种复杂的多数投票方案)。
如果能看到 CWM 与 gpt-oss 在 tokens/秒或解题时间上的比较会很有趣,因为它们使用不同的推理时扩展策略(best@k 与每单位推理强度生成更多 tokens)。
5. 小型递归Transformers
你可能已经注意到,所有先前的方法仍然基于Transformer架构。本节的主题也是如此,但与我们之前讨论的模型不同,这些是专为推理设计的小型专用Transformer。是的,专注于推理的架构并不一定总是大型的。
事实上,分层推理模型(HRM)作为一种小型递归Transformer的新方法,最近在研究界引起了广泛关注。
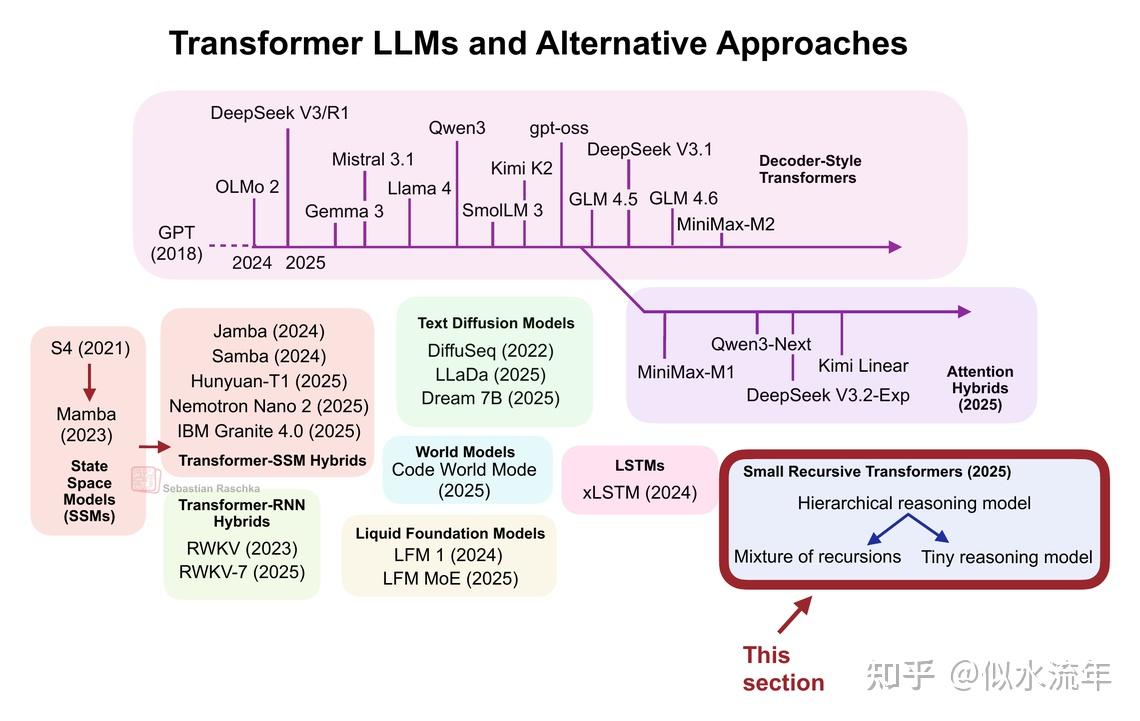
更具体地说,HRM开发人员展示了即使是非常小的Transformer模型(仅包含4个块)在逐步优化答案的训练下,也能在特定问题上展现出令人印象深刻的推理能力。这使该模型在ARC挑战赛中名列前茅。

递归模型(如HRM)背后的思想是,模型不是通过一次前向传递生成答案,而是以递归的方式反复优化其自身的输出。(在此过程中,每次迭代都会优化一个潜在表示,作者将其视为模型的“思考”或“推理”过程。)
第一个主要例子是夏季早些时候的HRM,随后是Mixture-of-Recursions (MoR)论文。
最近,2025年10月发表的Less is More: Recursive Reasoning with Tiny Networks提出了微型递归模型(Tiny Recursive Model, TRM,如下图所示),这是一种更简单、更小巧的模型(700万参数,比HRM小约4倍),在ARC基准测试上的表现甚至更好。
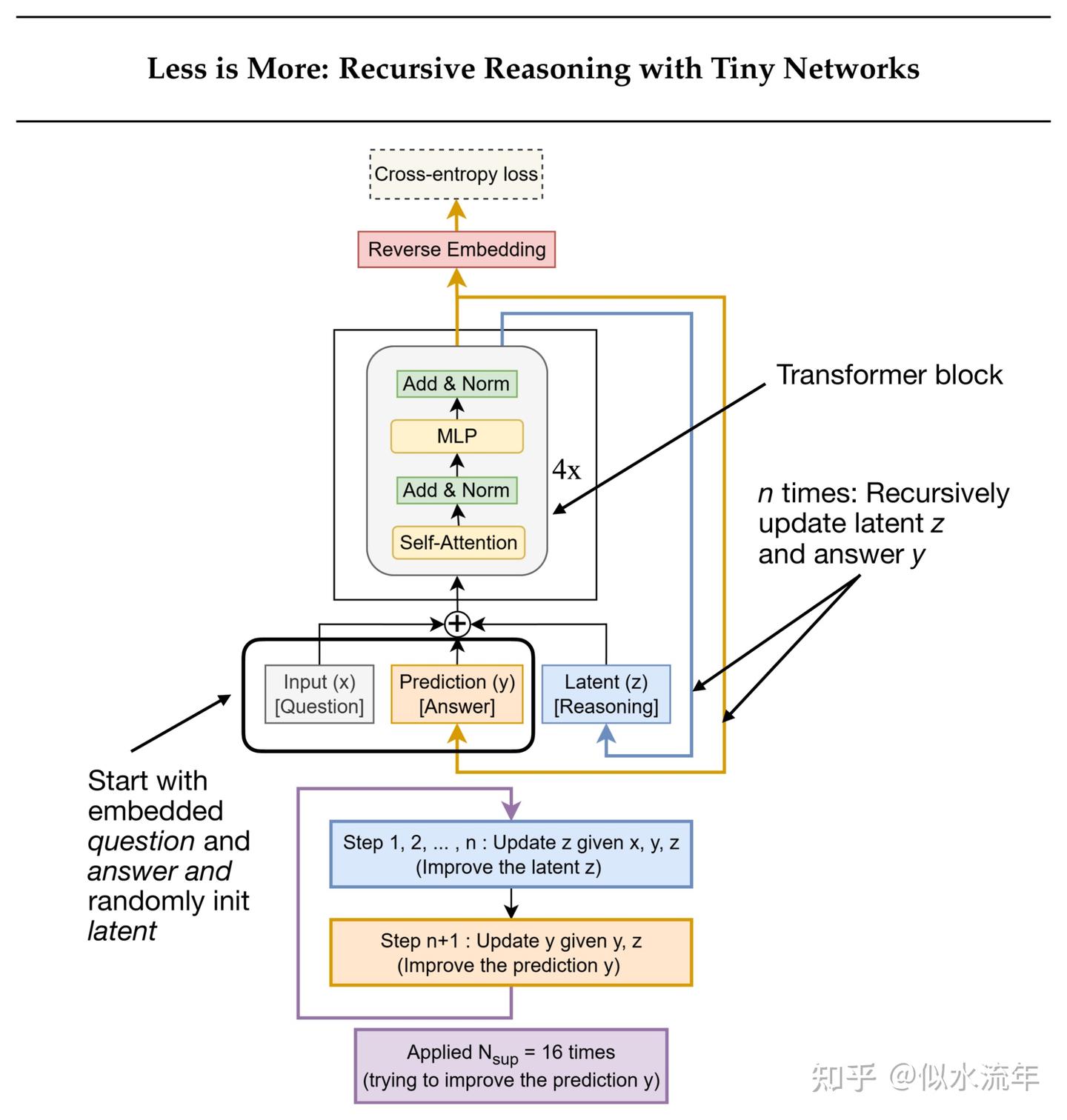
在本节的其余部分,让我们更详细地了解一下TRM。
5.1 这里的递归是什么意思?
TRM 通过两种交替更新来优化其答案:
1.它从当前的问题和答案中计算出一个潜在的推理状态。
2.然后根据该潜在状态来更新答案。
训练过程中,每个批次最多进行 16 步优化。每一步会执行多个无需梯度的循环,以迭代优化答案。随后会进行一个梯度循环,通过完整的推理序列反向传播梯度来更新模型权重。
需要说明的是,TRM 并不是在文本上运行的语言模型。不过,由于(a)它基于 Transformer 架构,(b)推理现在是大型语言模型(LLM)研究的核心焦点,而该模型对推理提供了截然不同的思路,因此这里包含相关内容。
虽然 TRM 未来可以扩展到文本问答任务,但目前它处理的是基于网格的输入和输出。换句话说,“问题”和“答案”都是离散标记的网格(例如 9×9 数独或 30×30 的 ARC/迷宫谜题),而非文本序列。
5.2 TRM与HRM有何不同?
HRM 包含两个小型Transformer模块(每个4个块),它们在递归级别之间进行通信。TRM 仅使用一个2层的Transformer。(请注意,之前的TRM图示在Transformer块旁标有“4×”,但那可能是为了便于与HRM进行比较而设计的。)
TRM会通过所有递归步骤进行反向传播,而HRM仅通过最后几步进行反向传播。
HRM包含一个显式的停止机制来确定何时停止迭代。TRM则用一个简单的二元交叉熵损失来替代该机制,从而学习何时停止迭代。
从性能上看,如图所示,TRM的表现比HRM好很多。
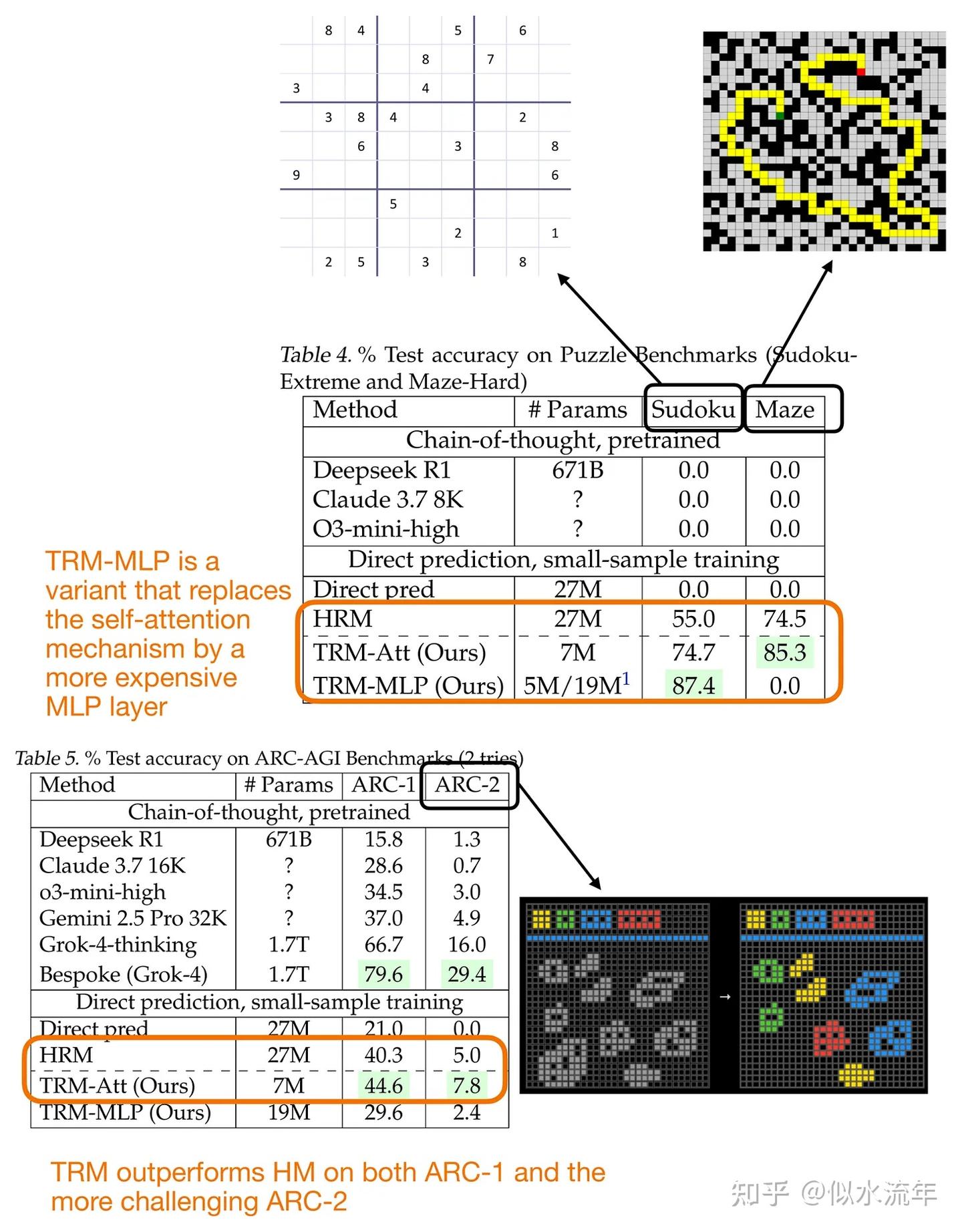
该论文包含了大量令人惊讶的消融研究,得出了若干有趣的额外见解。以下是我认为突出的两点:
- 层数越少,泛化能力越好。将层数从4层减少到2层,数独准确率从79.5%提升到了87.4%。
- 注意力机制并非必需。用纯MLP层替换自注意力机制也提高了准确率(从74.7%提升到87.4%)。但这在这里仅可行,因为上下文较小且长度固定。
5.3 整体视角
尽管HRM和TRM在这类基准测试中取得了非常好的推理性能,但将它们与大型LLM进行比较并不完全公平。HRM和TRM是针对ARC、数独和迷宫路径寻找等任务的专用模型,而LLM则是通用型模型。
诚然,HRM和TRM也可以用于其他任务,但它们必须针对每个任务进行专门训练。因此,从这个意义上说,我们可以将HRM和TRM类比为高效的计算器,而LLM则更像计算机,能够完成许多其他事情。
尽管如此,这些递归架构令人兴奋,它们作为概念验证展示了小型高效模型如何通过迭代自我完善来进行“推理”。
或许,在未来,这类模型可以作为推理或规划模块嵌入到更大的工具使用型LLM系统中。
目前,LLM仍然是广泛任务的理想选择,但一旦目标领域得到充分理解,就可以开发出像TRM这样的领域特定递归模型,以更高效地解决某些问题。
除了数独、迷宫寻找和ARC概念验证基准测试外,在物理学和生物学领域可能还有许多这类模型的应用场景。
6.总结
我原本计划在概述图中涵盖所有模型类别,但由于文章最终比我预期的要长,我不得不将xLSTMs、液体基础模型、Transformer-RNN混合模型和状态空间模型留到下次再讲(尽管Gated DeltaNet已经对状态空间模型和循环设计有所展示)。
作为本文的结论,我想重复之前说过的话,即标准的自回归Transformer大语言模型已被证明是可靠的,并且迄今为止经受住了时间的考验。此外,在效率不是主要考量因素的情况下,它们目前也是我们拥有的最佳选择。
参考资料:
https://sebastianraschka.com/blog/2025/beyond-standard-llms.html