作者:乞力马扎罗不说话
https://zhuanlan.zhihu.com/p/1978600046514685178
这篇博客想法诞生于上半年基于 trl / verl 魔改 agentic rl 时期,但拖延一直搁置。眼看相关技术栈演进速度惊人,再不发出来就要过气了,于是决定抛砖引玉分享。预计本系列还会分别基于一线魔改的开发者经验,在后续博客中再逐步深入解构代码。
本文主要从 Multi-turn Agentic RL 训练效率这一核心问题切入,从异步推理亮点设计、长尾样本处理、 offpolicy 缓解,以及现有训推加速的复用和改进出发,横向对比近半年有代表性的几个工作 AReaL (Ant)、Seer (Moonshot)、Slime (Zhipu) 和 verl (Bytedance) 的设计思路与解决方案。
太长不看版本:直接点击全面对比和选型思路章节。所有框架几乎都较好复用和集成了 pretrain / inference 端的技巧,随着时间演进,也在互相集成对方的优秀 feature,但各自侧重点有所不同,AReaL 的异步推理, Seer 的极致同步,再到 Slime 的 MoE 和 verl 的易用性大一统,四个框架本质是在不同约束条件下的探索优化。
Pretrain vs Post-train: MFU to Rollout
Pretrain 时代,训练效率的提升关键是 MFU —— 因为 Scaling Law 中FLOPS 和模型能力之间的关系,不可减少的矩阵浮点计算成了瓶颈 (FLOPS)。于是,主流 Megatron / FSDP 通过横刀流、纵刀流各并行策略(TP/PP/DP、Sequence Parallel、Expert Parallel)以及算子融合(Ops Fusion)、计算通信重叠(Overlapping)等策略,尽可能填满 GPU,就能带来整体速度的最大提升。
Post-training 时代,特别是 GRPO 等算法,瓶颈则转移到了 Rollout 时间 以及 Rollout / Train 的配合关系。这在 Agentic RL 训练中尤其严重,训练中 80%+ 的时间都发生在 rollout。
- Test-time scaling 设置下的 Rollout 极度依赖前一个 action 的生成,这种自回归属性导致它几乎无法通过简单的“加卡”来线性加速。
- LLM 时代,Rollout 本身就是昂贵的 GPU 任务,如何设计 train / rollout 两者之间的协同和调度机制成为了新的系统级挑战。
Agentic RL 三大训练瓶颈
Agentic RL 可以分为两类:
- Single-turn RL:例如数学题或单轮交互的工具,只对最后结果校验,输出形如 [prompt, response]。
- Multi-turn Agentic RL:模型在一次 Rollout 中需要多轮和环境交互,输出作为 Interleaved Context 继续推理。以 ReACT 范式和 append-only context 管理的方式为例,输出如 [prompt, action1, obs1, action2, obs2... response]。
2025 Q1,业界主要还在用 openrlhf, trl 及 verl-1.0 等框架主要支持第一种,因此也不需要太多改进。而如果进阶到一般性的 Multi-turn Agentic RL,如果不做针对性优化,以我们实际训练中的 32B 模型为例,Naive 的手搓框架单步时间 1 小时+,严重拖垮迭代速度。

抛开 Scaling up 不谈,仅分析 Basic RL 过程,我们可以从上图 rollout -train 时间看到,核心痛点在于:
Long context,指的是最长任务的 decode 时间
- Long CoT 输出,Test-time scaling 普遍需要 Long CoT 来激发强推理能力
- Long horizon tool call,工具轮次数随着任务复杂度上升直线上升
Bubble,指的是推理中 GPU 空闲等待其他任务完成的空转时间(类比于 pretrain 中 pipeline parallel,称之为 bubble)。
- Long-tail Effect: 在 GRPO/PPO 中,一个 Batch 的结束取决于最长的那条轨迹(Longest Trajectory)。Agentic 任务的输出长度极不平衡,也遵循二八定律,频繁触达 Context Window 上限的轨迹往往是不可替代和最有价值的的 Hard Exploration Case。这种 Long-tail Effect 导致同一个 Batch 长短不一,显卡持续等待中空转,进一步增加了 bubble 占比。
Long Call Tool Execution:指的是工具从输出到调用环境、通信等一系列时间。
- Long Call Tool 的调用(代码 Sandbox、数据库轮询、大规模检索)不仅耗时,而且具有强依赖性(后一轮推理依赖前一轮工具的返回结果),必须串行执行,这部分几乎很难压缩。
时间带来 2025 7 月,业界为了解决上述问题,给出了不同方案,从解决思路的演进来看:
常规思路:
- 提升推理速度:复用 vLLM / SGLang 等 Backend 的极致优化,引入 FP8 量化推理,使用改进版的 Speculative Decoding (SD)。
- 降低总长度:通过 Context Manager 压缩历史(如 Qwen AgentFold),或在训练中混合 Long/Short CoT。未来还可能追求更高效的推理路径。
RL 特有思路(核心战场):
- 异步(Asynchronous):异步推理,无论是 replay buffer 还是其他 partial rollout 半异步的设计,都是牺牲一定的 On-policy 准度,换取极致效率(AReaL 的思路),比如重走一遍 A3C / A2C 历史、彻底解耦训推策略。
- 分离式(Disaggregated):在架构上直接解耦 rollout / train,追求训推平滑切换与零冗余,本质上都是 Impala 思想在 LLM 时代的复刻与升级。
- 同步(Load Balance):坚持同步,不牺牲 On-policy,而是建模为负载均衡任务来消除 bubble 做到零冗余,切分任务、全局显存池化来尽可能消除 Bubble 和降低 tail latency(Seer 的思路)。
AReal: Fully Asynchronous
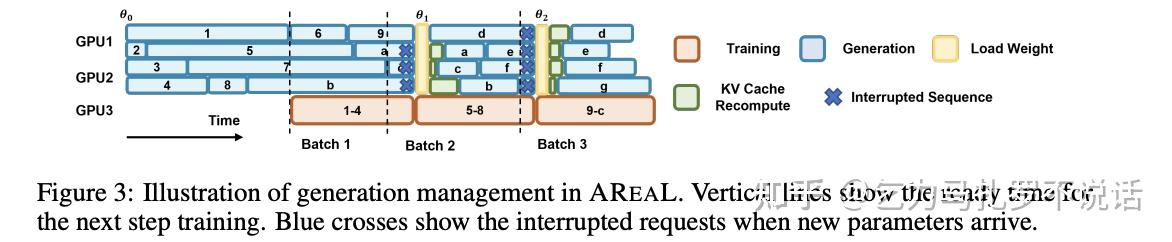
AReaL 选择了类似 Impala/A3C 的 Fully Asynchronous 路线。
核心哲学:既然同步和等待是 Bubble 的根源,那就彻底解耦训练和推理,再从算法和系统缓解异步引入的 off-policyness。
Highlight:
Stream Rollout:将 Rollout 和 Train 物理分离。推理侧始终用最新 Policy 不间断生成,训练侧持续从 Replay Buffer 取数更新。理论上,Bubble 被压缩至近似为 0。(这也允许了训推采用异构硬件,来降低整体成本如 H800 训练,L40s/A10 推理)。
Staleness-aware PPO :异步的代价是 Off-policyness,梯度越来越不准。AReal 一方面理论上引入 Decoupled PPO,另一方面做好 rollout - train 的相对平衡策略。
- Decoupled PPO Objective,再次解耦实际行为策略和理论行为策略(现在一共有三个策略),通过双层 Importance Sampling 修正行为策略与目标策略的梯度偏差,从而安全地利用“稍微”过时的数据。
- Staleness Control 保证 replay buffer 足够新(rollout >> train),优先回放旧样本 (类似 Priorized level replay),同时引入超参 eta 控制允许的最大版本偏差 。
- Interruptible Generation:保证训练端维持 batch size(train >> rollout), 为了维持训练端的 Batch Size 稳定,当 Replay Buffer 数据不足时,系统可以强制挂起长任务、优先产出短任务,实现抢占式调度。
此外也采用了一些系统的优化做极致加速,比如 GPU / CPU 解耦,将 reward 计算等 offload 到 CPU 上, 从而可以和 GPU 运算重叠进行;Rollout 时 asyncio 做高并发;以及动态内存分配,固定最大内存下,平衡 micro batch token 数量。
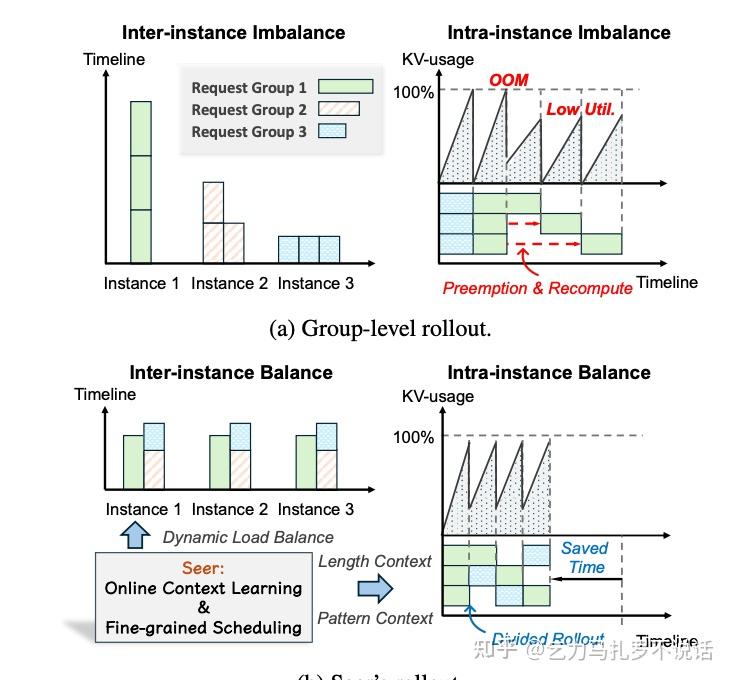
Seer: Load Balance
核心哲学:为了保证推理模型的逻辑严密性,坚持 On-policy 同步训练的原教旨主义( A2C ),但通过极致的系统工程做负载均衡,消除长尾 bubble。
Highlight:
Divided Rollout:把长尾 request 切分成更小的 chunk ,以 chunk 粒度调度任务,灵活填充卡间气泡。
- Global KV Cache (Mooncake): Seer 基于 Mooncake 实现了 Disaggregated KV Cache 这一配合使用的核心基建。全局 KV Cache 意味着负载较高的卡上的 request 可以直接迁移到另一张卡,无需重复 prefill,极大允许了 divided 之后的片段可以在卡间低成本灵活切换。
Context-Aware Scheduling: 试图通过 prompt 来预测最长的可能生成长度,采用 Long-first pool 调度,优先处理长任务(从实验来看,简单的 context-aware 策略效果居然能降低 tail latency 87% ,divided rollout 反而只能降低 6% 左右)。
Adaptive Grouped Speculative Decoding (AGSD):传统 SD 需要固定的 Draft Model,即便支持了推理使用,但在 RL 过程中 Draft Model 会迅速过时导致接受率崩塌,等价于串行。Seer 则是采用同组其他生成快 request 构成的 Compressed Suffix Tree ,当作慢 request 的 draft model,非常巧妙,可能会是压缩推理的主要思路。
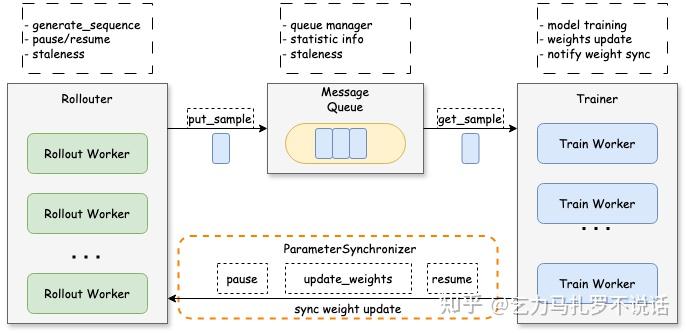
Verl: Hybrid Flow
verl (Volcano Engine RL) 拥有目前最发达的开源社区生态 —— 所以除了官方 agent 支持还有 verl-agent 等二次开发工作。官方场外版七月通过 AgentLoop 支持了多轮 Agentic 训练,在一个月前的最新版本中也支持了类似的 Fully Asynchronous 和 decoupled PPO 的训练策略,在细节上略有差异。
这里不再重复基础 RL 训练上的设计优势和异步设计,只列出有区别的细节。
核心哲学:开源、集成、高速迭代
Highlight:
- AgentLoop
- Offpolicy-ness 控制
- Staleness Control,verl 采用动态的 staleness_threshold 控制最大允许的旧样本比例,staleness_threshold=0 时近似同步,> 0 时允许 Rollouter “抢跑”。例如设置为 0.5,表示允许使用滞后不超过 0.5 个 Epoch 的数据。
- Partial Rollout / Sleep-Resume,类似的允许长任务被打断 sleep 和由下一次策略 resume,不浪费一个 token。
Slime: Hybrid
核心哲学:为 MoE 而生,轻量级框架,追求灵活性。
Highlight:
Hybrid Mode:Slime 采用了更灵活的机制,允许根据不同任务采用同步异步。
- Colocated Synchronous 模式:适合推理/数学任务,减少通信,数学证明等对逻辑严密性要求极高的任务,需要保证严格 On-Policy
- Decoupled Asynchronous 模式:适合复杂长执行的 Agent 任务,防止环境交互阻塞训练
SGLang Native Integration 深度绑定 SGLang。这意味着所有 SGLang 社区的优化(RadixAttention、Triton Kernels)都能第一时间用上。
Active Partial Rollouts: 通过超额推理,牺牲一部份上下文切换时间,降低单 batch latency。比如需要 batch size = 32,启动 64 个请求,当最快的 32 个请求完成时,立即终止剩余,但保留 KV cache 用于下一个 batch 生成。
从基建到创新的全面横向对比
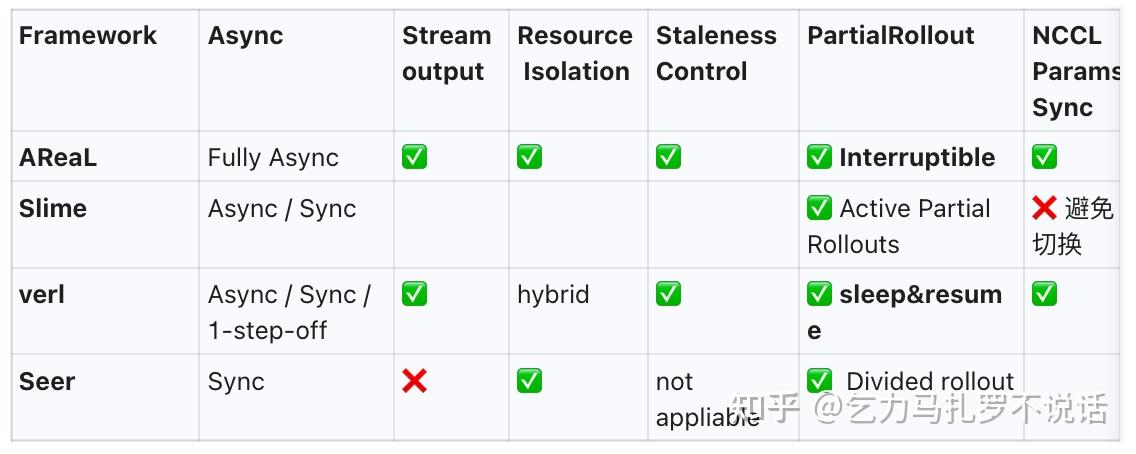
训推端和调度
都采用了 ray,并复用了 sglang / vllm 等推理前后引擎,相较前一代的 rl 框架都有更好的 scale up 特性。
| Framework | Org | Policy Type | Training Backend | Inference Backend | Orchestration |
|---|---|---|---|---|---|
| AReaL | Ant | Off-policy | Megatron / FSDP | vLLM / SGLang | Ray |
| Slime | Zhipu | Hybrid | Megatron | SGLang (Native) | Ray |
| verl | Bytedance | Hybrid | Megatron / FSDP | vLLM / SGLang | Ray |
| Seer | Moonshot | On-policy | Megatron | vLLM (Custom) | K8s / Ray |
推理加速的极致复用

异步推理的技巧
从长尾样本的效率加速看,各显神通地采用了不同机制:
- verl / AReaL (Sleep-Resume):允许长任务被中断(Sleep/interupt)和下一轮 Resume,不浪费 token,更适合计算比较贵的场景。
- Slime (Active Partial Rollouts): 超额推理,通过冗余计算换整体时延的策略,更适合推理比较便宜、但 batch 时间要求高的场景。
- Seer (Divided Rollout):将长任务切碎,利用全局 kvcache 池调度,系统利用率最高,无计算浪费,但对基础设施(网络带宽、KV Cache池)要求最高。
从训推分离后的数据管理 Replay Buffer 设计来看:
- AReaL(Replay Buffer): 倾向于混合历史数据,类似 DQN/IMPALA,能带来数据多样性,但 Off-policy 程度最重。
- Slime (APR Replay Buffer):允许存历史 patial rollout 的片段改进版本 replay buffer。
- Verl(FIFO TransferQueue): 倾向于流式处理最新数据,更适合 PPO/GRPO 等 On-policy 变种算法。
具体选型思路
构建复杂长调用 Agent(如全网搜索、代码执行、长工具调用)适合完全异步换吞吐的 AReaL 或 Slime (Async Mode),用样本量暴力美学弥补 Off-policy 的精度损失。
构建严密逻辑推理等场景(如 Math/Coding 刷榜)需要严格 on-policy,适合 Seer (架构参考) 或 verl (同步/半异步模式)。Seer 的全局调度是目前的性能天花板。
训练超大规模的 MoE,适合 Slime,SGLang Native + DeepEP 对 MoE 的支持最为完善。
中小团队快速上手/魔改,或者初学者学习,适合 verl 或者 slime,verl 各个特性集成很完备和均衡,开源社区足够活跃,后者轻量级代码框架,学习性很好。
如何定义工业级强化学习
总结上述框架的演进,我认为一个能称之为“工业级”的 Agentic RL 训练框架,应该具备以下画像:
训推分离与灵活切换的同/异步机制
原生具备灵活解耦 Rollout/Train 和异步,算法同学能简单易用地高速魔改。这都指向了 Ray —— 足够好的分布式计算通用抽象。
- 是否采用 Ray
- 是否灵活支持同步和异步推理机制
- 是否支持 onpolicyness tradeoff
- 是否训推分离,以及高效的参数切换和同步
极致复用推理加速技术
- 是否原生集成 vllm / sglang
- 是否支持 FP8 和更低精度的量化
- 是否支持更适合 moe 的 deepep 和 route replay
- 是否支持适配于 RL 训练的投机采样
灵活长上下文管理和压缩
包括 particial Rollout、全局 KV cache、更通用的上下文压缩机制、以及可暴露灵活魔改的 Context Manager。
- 是否针对 long-context 样本做感知和细粒度加速
- 是否支持 partial rollout / divided rollout 等灵活多样的推理策略
- 是否采用有效的 context manager,压缩率如何
作为相对通用和底层的算法框架,会更加关注前两者,而在实际应用场景上,做 rollout 长文本压缩和长度均衡显然更直接和有效,这仍然需要 task-specific 的 context manage(coding / tool using / mcp)或比 MCP 协议更省 token 的统一协议,有赖于应用团队做更多针对性优化的方案(这是另一个话题,埋坑)。
为什么选择训练效率作为切入点?从我个人的工程经历来看,早年传统 RL 在 OpenAI Gym 时代,我一开始用 MPI 手搓分布式训练,直到升级到 Ray 以后才体会到系统抽象带来的极大跃升;进入 LLM Pretrain 时代,也是在趟过 Megatron-LM、DeepSpeed 以及各种显存、精度、混合并行训练的深坑后,才算走上正轨。
在 Post-training 阶段,前期 Infra 的“粮草先行”程度(与算法 Co-evolving),直接决定了后期算法、数据和策略迭代的速率与天花板。而当下的 RL 开源届还不能完全说有一套高效的、统一的 Infra把 async 推理、long-tail effect、 offpolicyness 平衡的很好(相信各大厂内部版或许要更进一步),但时间窗口或许不会太久。