基于强化学习框架的自我提升正日益成为增强模型推理能力的关键后训练方法,这一方法直接促成了DeepSeek-R1的成功。
青稞Talk 第45期,香港科技大学(HKUST)计算机系博士生曾伟豪,将直播分享《B-STaR & SimpleRL-Zoo:通过强化学习自我提升推理性能和效率》。
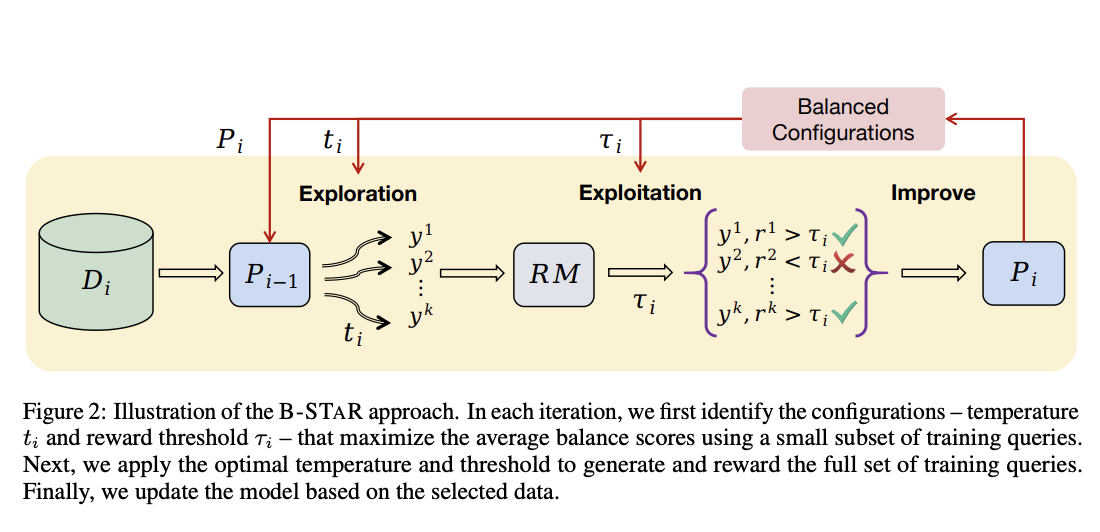
B-STaR 是一种在训练过程中平衡探索与利用的自我提升框架。该框架通过确保模型生成内容的多样性并避免性能崩溃,实现了持续的自我改进。
论文名称:B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners
Abs:https://arxiv.org/pdf/2412.17256
SimpleRL 提供了一个简单的强化学习方案,用于提升模型的推理能力,无需SFT、无需奖励模型,仅通过规则奖励函数和RL训练,即可大幅超越传统方法。

SimpleRL-Zoo是SimpleRL的进化版,针对多种开源基座模型的零样本强化学习(Zero RL)训练进行了全面探索。在覆盖不同模型家族和规模的10种基座模型上研究了Zero RL训练,通过采用关键设计策略(如优化格式特定的奖励机制和控制数据难度),在大多数场景下显著提升了推理准确性和思维链长度。
论文名称:SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Abs:https://arxiv.org/abs/2503.18892
Code:https://github.com/hkust-nlp/simpleRL-reason

特别值得一提的是,首次在Qwen系列之外的小型模型中观察到了“aha moment”。在本次Talk中,曾伟豪博士将分享实现Zero RL训练成功的核心设计原则,以及他们的研究发现与实践经验。

主题提纲
B-STaR & SimpleRL-Zoo:通过强化学习自我提升推理性能和效率
1、大模型训练中的强化学习方法
2、平衡探索与利用的自我提升框架 B-STaR
3、SimpleRL-Zoo:针对开源基座模型的零样本强化学习训练
- 实现Zero RL训练成功的核心设计原则
- 研究发现与实践经验
嘉宾介绍
曾伟豪,香港科技大学(HKUST)计算机系博士生,主要研究方向为大语言模型(LLM)的post-training,特别关注模型推理能力增强、对齐数据工程、自我进化训练方法等。他提出了SimpleRL方法,利用极少数据结合强化学习显著提升模型在数学推理任务上的能力(Github 3K Star);在B-STAR中引入探索与利用的动态平衡机制,进一步提升LLM的自我学习效果(ICLR 2025);在Deita项目中,通过自动数据筛选实现高效指令微调,使对齐训练更加数据节省(ICLR 2024);他还与微软合作提出Auto Evol-Instruct框架,实现无人工干预的指令进化(EMNLP 2024)。相关成果发表于ICLR、ACL、EMNLP等顶级会议,致力于推进开源LLM社区的发展。
直播时间
4月19日(周六)上午11点
参与方式
Talk 将在青稞·知识社区上进行,扫码对暗号:" 0419 ",报名进群!
